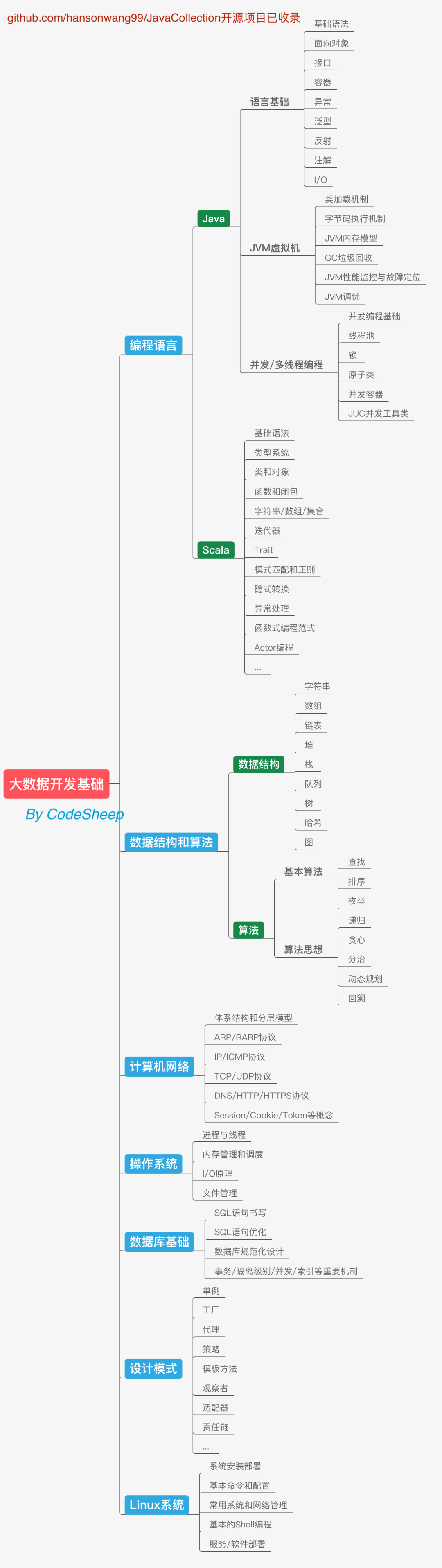
# 大数据开发基础
学习编程语言往往是我们开启学习之路的第一大步。大数据领域的很多框架都是基于Java语言开发的,而且各种框架也都提供了Java API来提供使用和操作接口,所以Java语言的学习逃不掉。除此之外Scala在必要时也可以学一下,在大数据开发领域里用得还是挺多的。Scala语言的表达能力很强,代码信噪比很高,而且很多大数据框架也都提供了Scala语言的开发接口,况且Scala也可以运行于Java平台(JVM),并且兼容Java程序,所以也可以和大数据相关系统进行很好的集成。
除此之外,老生常谈的数据结构和算法、计算机网络、操作系统、数据库、设计模式也是程序员必备的通用计算机基础,不光是搞大数据的需要具备,搞后端开发的也是掌握这些基础,而且这些东西在求职面试时也是必备的,这部分应该大量花时间给坐实。
最后还要提一下对Linux操作系统的要求,当然我们这里主要还是着眼于Linux系统使用的角度。因为大数据系统的开发、部署基本都是基于Linux环境进行的。掌握常用的命令、配置、网络和系统管理、基本的Shell编程等等,对学习都大有裨益。
—
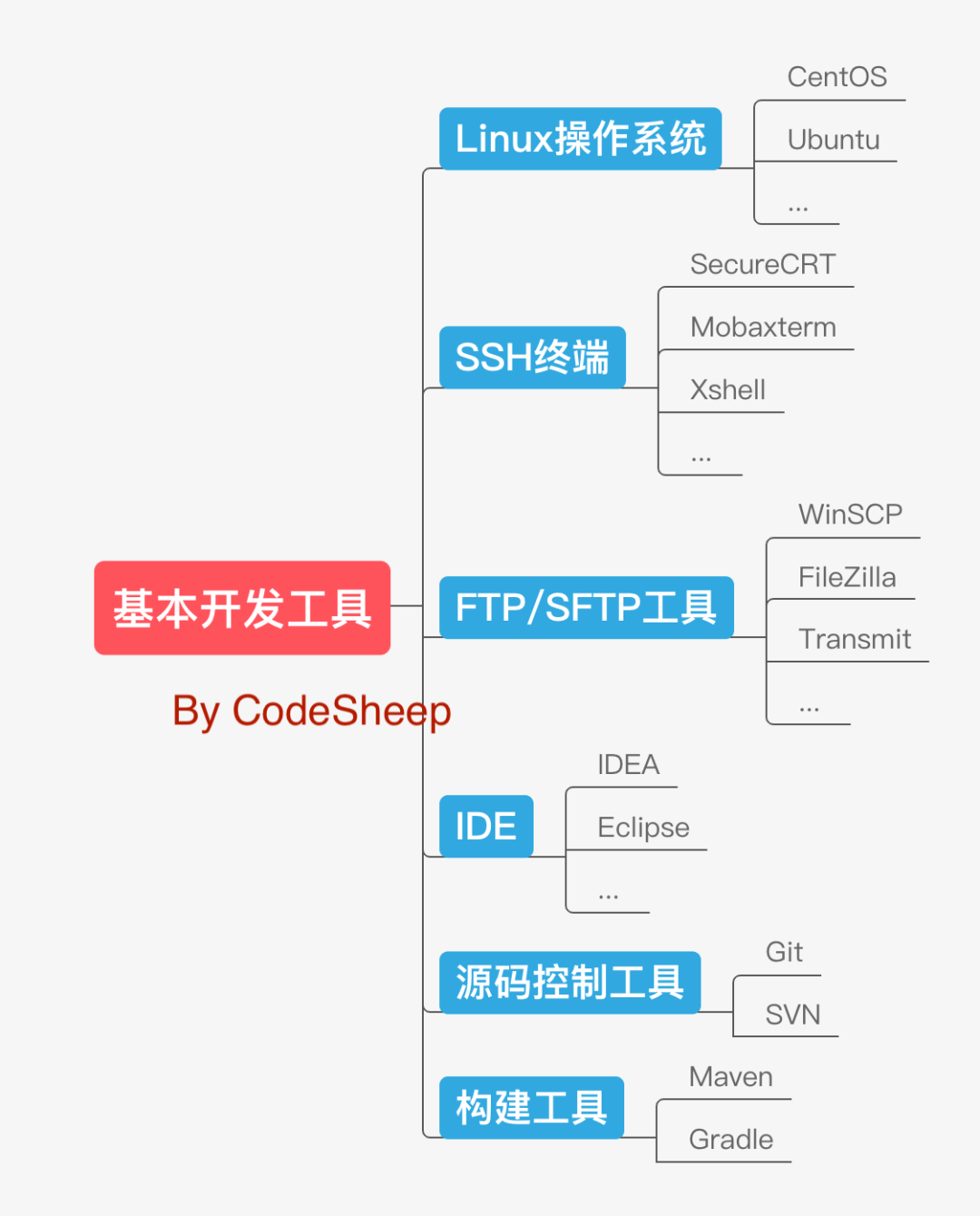
# 基本开发工具
大数据领域的常见开发工具和软件和后端开发基本差不多,比如:选一个常见的Linux操作系统,一套好用的SSH工具和FTP/SFTP工具,一个称手的集成开发环境,以及主流的源码控制工具和构建工具等等。
接下来就进入到大数据开发的具体流程,分几大块捋一遍,首先就是数据采集。
—
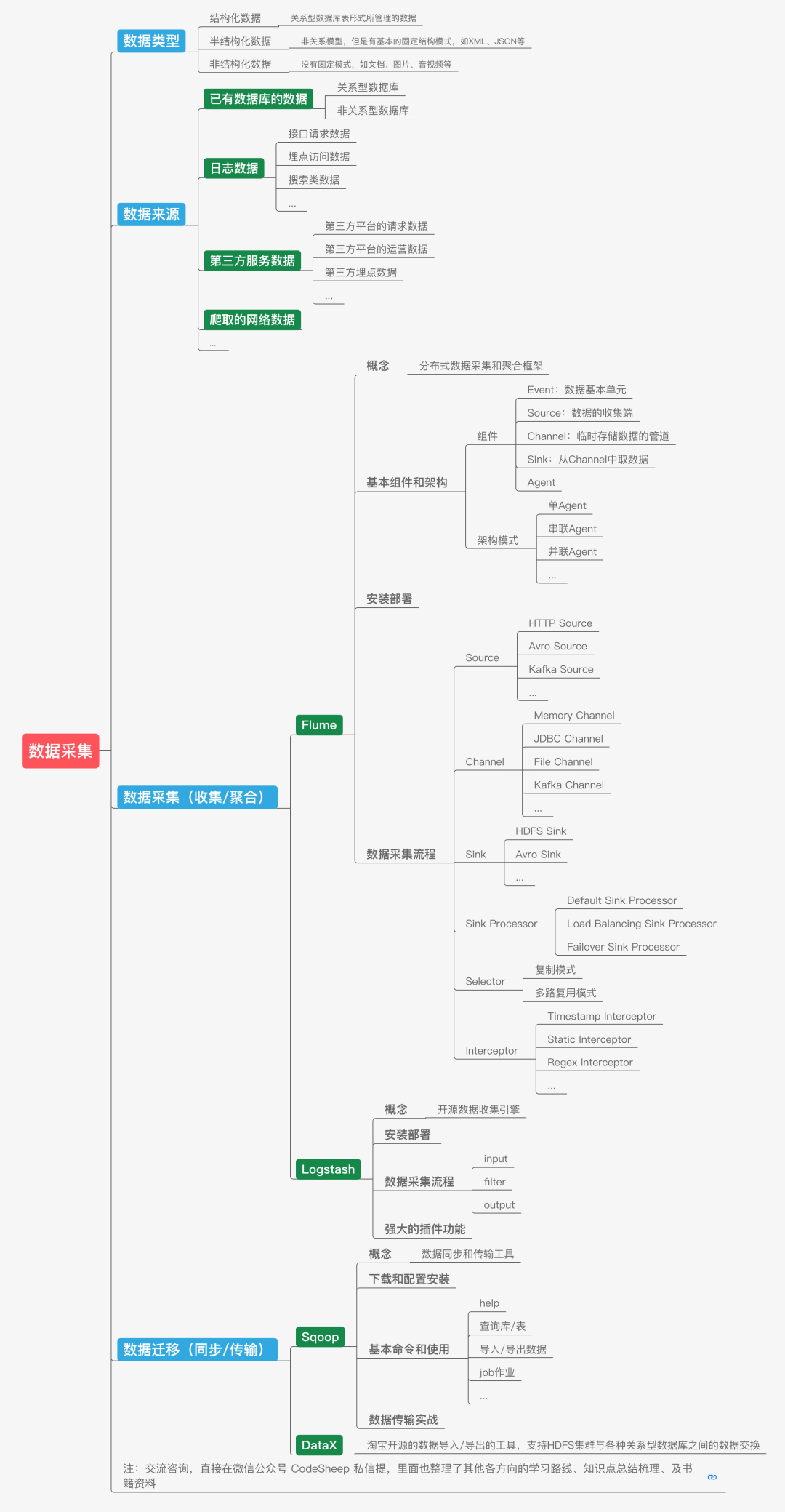
# 数据采集
既然大数据系统是处理海量数据的,那么第一个问题,这个海量数据到底是什么类型?从哪里来呢?
可以说,输入大数据系统的数据类型种类繁多,形式结构也有所不同,有传统的结构化数据,也有XML、Json等这类的半结构化数据,甚至还有文档、音视频这类非结构化数据。

数据的来源更是五花八门,有直接来自后端已有数据库的数据,有来自后端日志系统的数据,有来自第三方服务的各种数据,甚至还有从网上爬取的各种数据。

找到了数据源,接下来的数据采集和数据传输工作就很重要了。
我们就以后台最常见的日志数据为例,由于现在的服务系统采用集群部署方式的很多,那分布式集群上海量日志数据的采集和传输就是一个大问题。Flume是一个较常使用的分布式数据采集和聚合框架,最典型的应用就是日志数据的收集。它可以定制各类数据发送方并聚合数据,同时提供对数据的简单处理,并写到各种数据接受方,完成数据传输。
与此同时,还有一个叫做Logstash的开源数据收集引擎可能大家也听过,也比较常用的。
当然还有一种场景也是数据采集这一步通常需要考虑的,那就是在不同的存储系统(或数据库)之间进行数据的迁移(如:导入/导出)。比如我们经常需要在传统关系型数据库(如MySQL)和大数据系统的数据仓库(如Hive)之间进行数据迁移(交换),这时候一个叫Sqoop的数据采集和传输工具就非常常用了。除此之外,淘宝开源的DataX也是同类型工具。
—
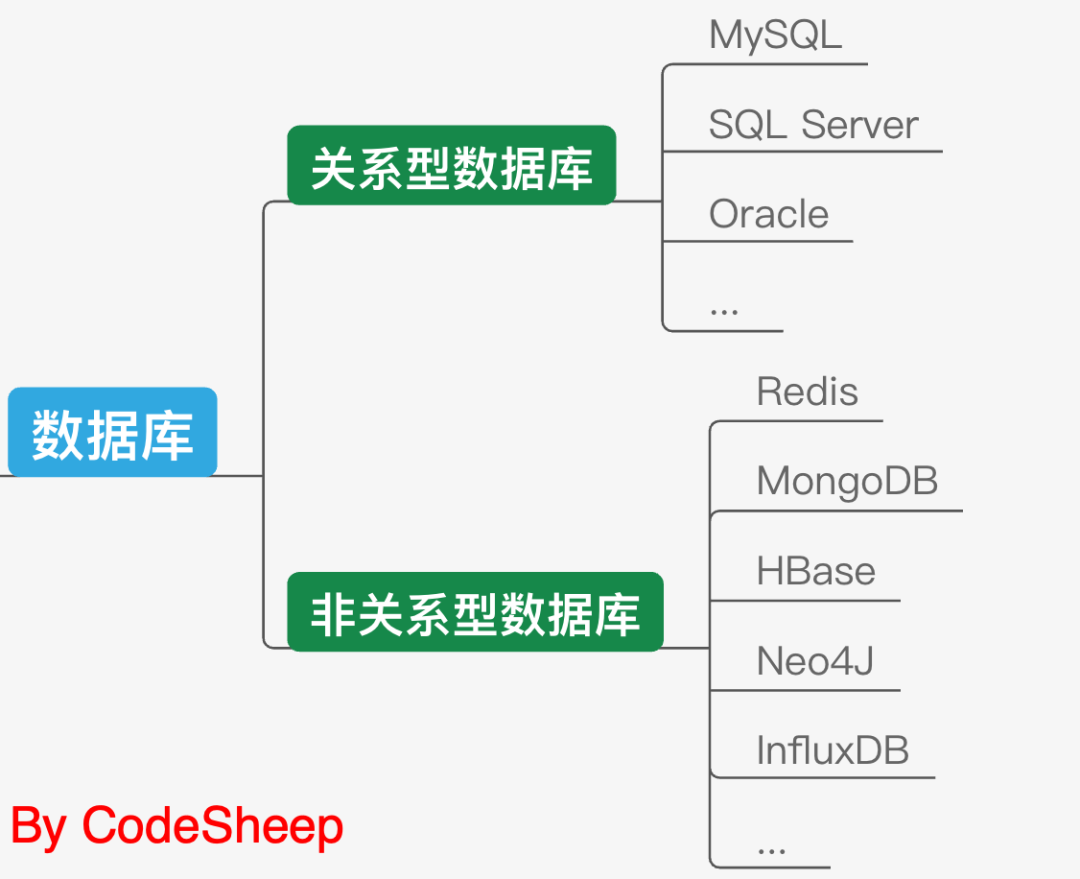
# 数据存储
数据采集完成,接下来需要对其进行存储,这也是非常清晰的思路和流程。
说到数据存储,我们首先想到的当然是数据库存储。包括MySQL、Sql Server等等这种最常见的关系型数据库,以及Redis、MongoDB、HBase等这类非关系型数据库。
我们这里将ElasticSearch单独提出来聊,因为虽然它某一程度上也可以视为数据库,但是它更主要的身份还是一个优秀的全文搜索引擎。它的出现,解决了一部分传统关系型数据库和NoSQL非关系型数据库所没有办法高效完成的一些工作,比如高效的全文检索,结构化检索,甚至是数据分析,所以现在用的公司也越来越多。
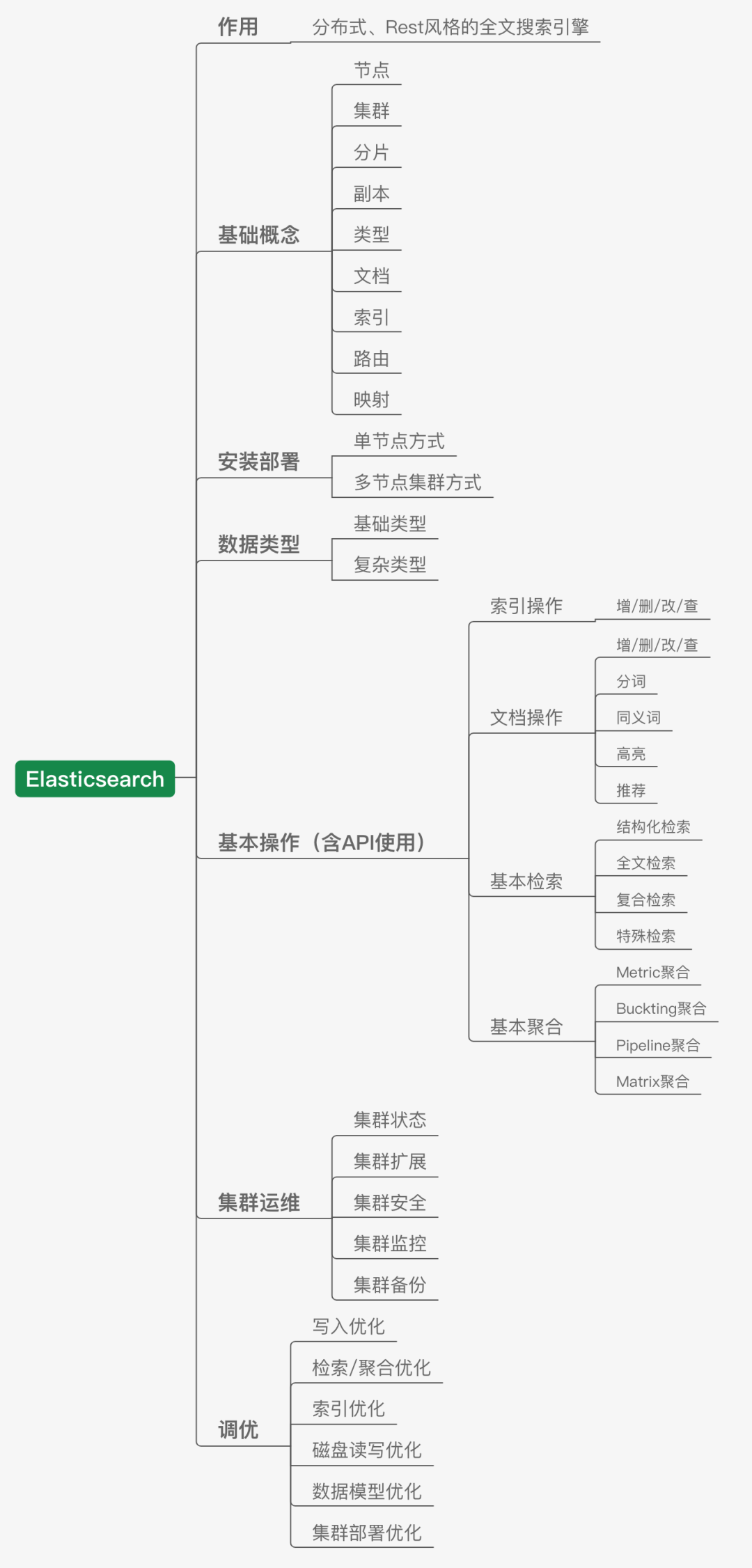
除了传统的数据库,在大数据领域,应用非常广泛的存储技术还包括分布式文件系统和分布式数据库。说到分布式文件系统,大名鼎鼎的HDFS就是一个使用非常广泛的大数据分布式文件系统,它既是基本的数据存储平台,也是大数据系统基础平台设施;而后者的代表性技术HBase则是一个构建在HDFS之上的分布式数据库,适合海量数据的存储。
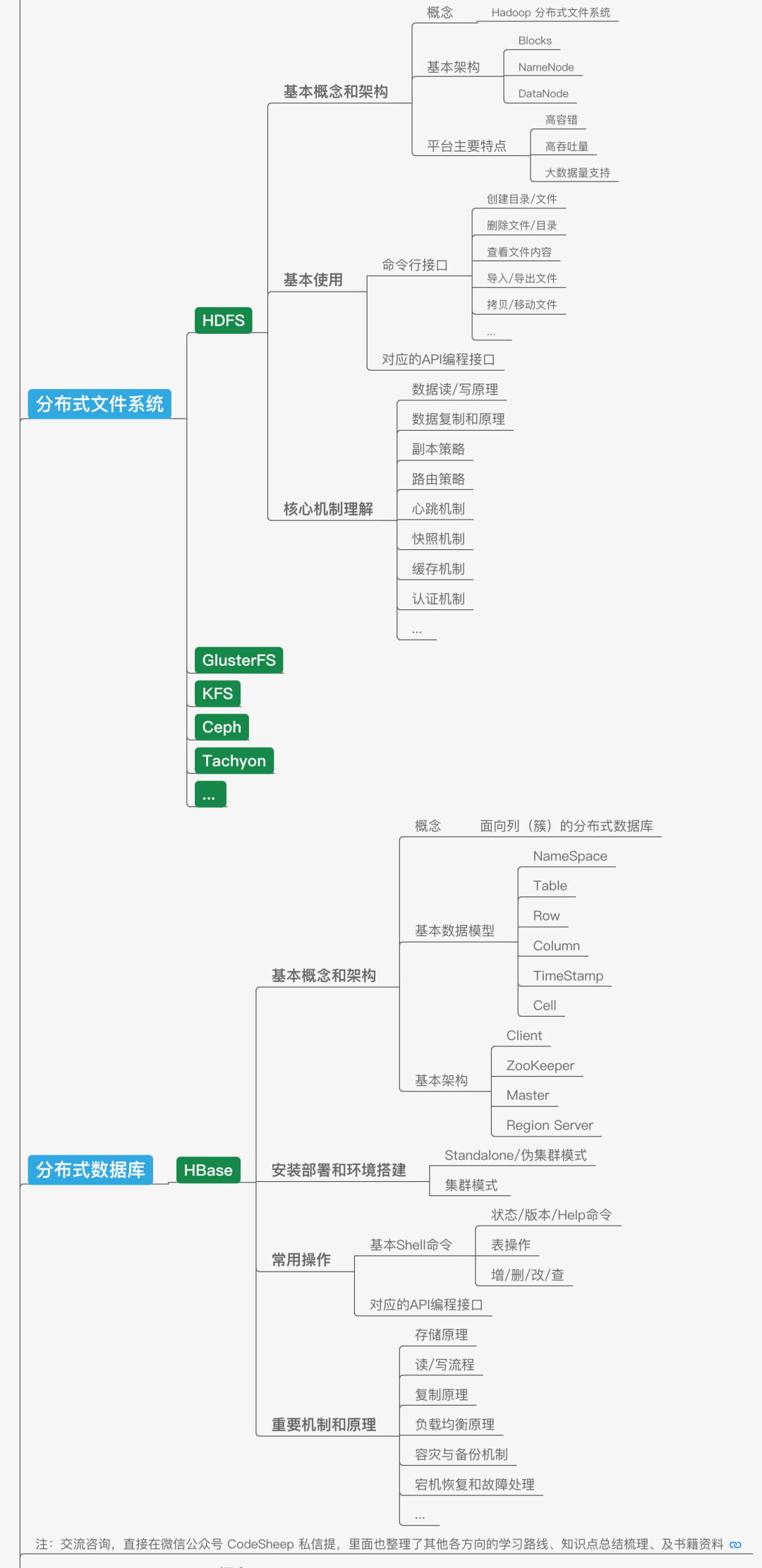
在大数据领域,除了分布式文件系统和分布式数据库,还有一个经常听到的就是以Hive为代表的数据仓库。我们可以将数据仓库理解为一个逻辑上的概念,其底层往往是基于文件系统打造的。还以Hive为例,它的出现主要就是可以让开发人员能够通过SQL的方式来方便地操作和处理HDFS上的数据,适用于离线批量数据的处理,上手友好,使用门槛降低。

所以将这部分内容做一个阶段性总结,可以如下所示:

—
# 数据处理
数据有着落了,接下来干啥?当然是充分挖掘数据所蕴含的价值,更直白一些说就是对其进行各种查询、分析和计算,这样才能为数据赋能,产生价值。
最早期的MapReduce就是Hadoop提供的分布式计算框架,可以用来统计和分析HDFS上的海量数据,适合于速度不敏感的离线批处理;后来出现的内存计算框架Spark则更加适合做迭代运算,因此也备受青睐。在一些不需要实时计算的场景,这些框架应用得十分广泛,但是在一些离线数据分析无法满足需求的场景下,比如金融风控、实时推荐等,这时候在线计算或者说流式计算就变得十分有必要了,这也成了现如今诸如Storm、Flink等一大批优秀的实时计算框架的主阵地,尤其是Flink,这几年的火热程度不用多说,基于它构建的处理引擎也鳞次栉比。

—
# 数据价值和应用
大数据系统最终的任务还是得服务于业务,为生产创造出实际价值。这种价值应用场景包括但不限于提供各种统计报表,商品推荐,数据可视化展现,商业分析,辅助决策等等。

—
# 大数据周边技术
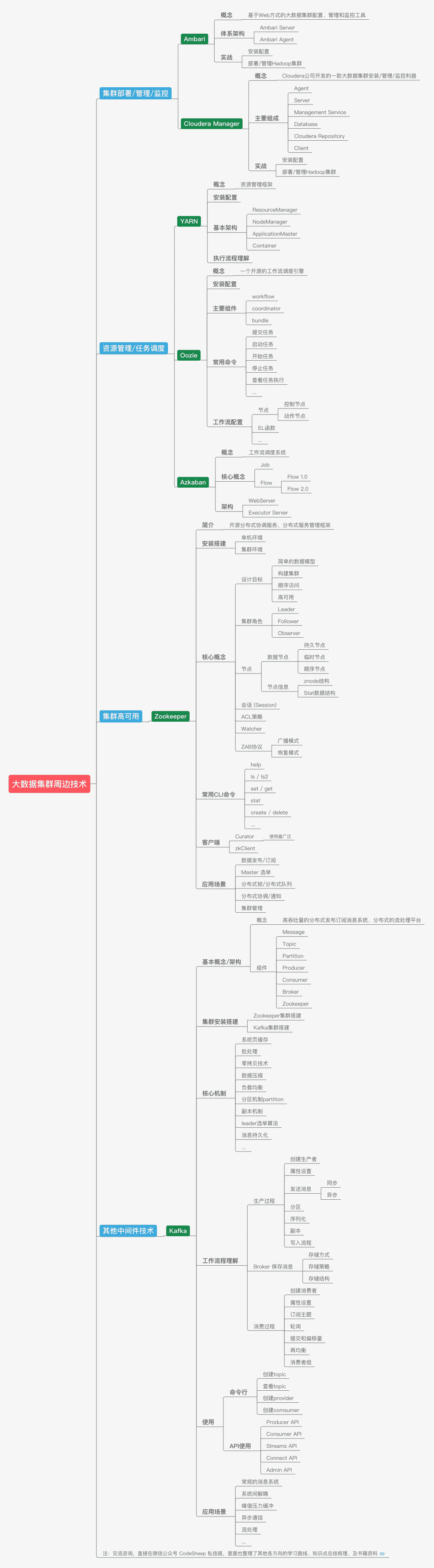
聊到这里,应该说上面的内容已经基本将一个大数据引擎的主流程走完了,然而实际的大数据系统还需要诸多周边技术的支持,因此还衍生了很多附加框架和技术。
由于单机性能的局限和瓶颈,所以大数据系统的很多框架组件都是集群部署的,这时候针对集群系统的部署、管理以及监控工具就不可或缺了,比如使用广泛的Ambari和Cloudera Manager等。
有了集群之后,集群平台上各种资源的管理以及各种任务的调度就成了一个复杂且棘手的问题,这时候资源管理框架YARN,任务工作流调度框架Azkaban和Oozie等就有了用武之地。
同时为了保证分布式集群的高可用,像ZooKeeper这种分布式协调服务框架简直帮了大忙,像Master选举、集群管理、分布式协调通知等任务统统不在话下。
最后,还必须要提的一个大名鼎鼎的中间件框架,那就是Kafka。它不仅仅是一个高吞吐量的消息系统,有了它之后,系统解耦、峰值压力缓冲、高效流处理等等都使得它成为后端开发和大数据开发人员眼里那个最靓的崽。
—
# 总结
最后我们也将上述所有内容的完整版思维导图给贴在这里,由于这个图实在太大,上传后可能被压缩,如需无损版源文件的,可长按或微信扫码关注下方公众号CodeSheep二维码,回复「大数据」三个字自取吧:

(长按或扫码识别)

—
# 几个要讨论的话题
## 大数据开发和后端开发关系大吗?
应该说很多技术点和框架都是有交集的。比如通用编程基础部分完全一致,再者常用的像Redis、Zookeeper、Kafka、Elasticsearch等等这些主流得不能再主流的框架,在以前咱们梳理Java后端路线时也都有,所以二者的交集很大,甚至很多做大数据的,以前就是从后端转过来的,非常自然,因为很多技术都相通甚至完全一样。
## 这么多框架都得学吗?
大数据领域框架这么多,睡不着觉的可以大致数一数,仅刚才那个脑图里面所提及的最起码就有三四十个,是每个都需要学习吗?我们在梳理时,同类型的主流框架都列举了不止一个。一般来说,我们只要学明白其中一个,上手同类型其他技术就都不难了,举一反三很重要。另外我们尽量学主流经典的框架,一般就没啥问题,比如分布式文件系统HDFS很经典用得很多,流处理里面Flink现在火得一腿,自学对应部分时就可以考虑学一下。
## 具体框架(技术)到底怎么学?
最后还是得落实到具体某一个技术(框架)到底怎么学的问题。我觉得学习思路倒也清晰,首先第一步,搞清楚这个框架是干什么的,解决了什么问题和痛点,同类“竞品”还有哪些,这一步在上面的详细思维导图里,我们已经帮你完成了;第二大步,把这个技术(框架)用起来,获得成就感很重要,那具体又怎么用呢,思路也很明了,首先是把对应环境安装部署好,跑起来,然后基于准备好的环境做实验,跑Demo,自己写东西拿上去跑,由简单到复杂,慢慢上手直至熟练,该过程中肯定会踩坑,所以做好记录、输出、笔记,写下自己的踩坑过程和解决思路非常重要,步步为营;最后一大步才是针对里面的关键机制深入研究其原理,学到就是赚到,所以总体也就这三大步。
本文来自博客园,作者:原力星球,转载请注明原文链接:https://www.cnblogs.com/cheng020406/p/17294793.html