
本文比较系统的介绍了什么是全栈以及全栈开发的具体步骤和实践,最后分享了作者做全栈的心得体会。一、前言
1.1 什么是全栈
1.2 为什么做全栈
降低沟通成本,提升交付效率:精细化分工导致的结果是协同成本大大增加,尤其是对于跨多个团队的项目,每个开发可能找对接的同学都得找好几个人才能找到,影响整体的需求交付效率。当下,由单人或单团队完成需求的闭环开发,降低协同或许是提升产品交付效率的最快方式。
从全局视角加深领域专业度、增强个人竞争力:首先,无论是前端技术、客户端技术还是服务端技术,研发平台、框架、规范都基本定型,学习成本降低;其次,通过学习全栈技术,可以增加技术视角的广度,未来进行开发工作时,不再偏居一隅,可以从整个项目的角度出发,设计更合理的架构;最后,未来市场需要的也是全栈型开发同学,在《Stack Overflow 2021 全球8W名开发者调查报告》显示排名前三分别是:全栈工程师(49.7%)、后端工程师(43.7%)、前端工程师(27.4%)。
二、全栈需求开发SOP
2.1 需求分级
| |
| |
| |
|
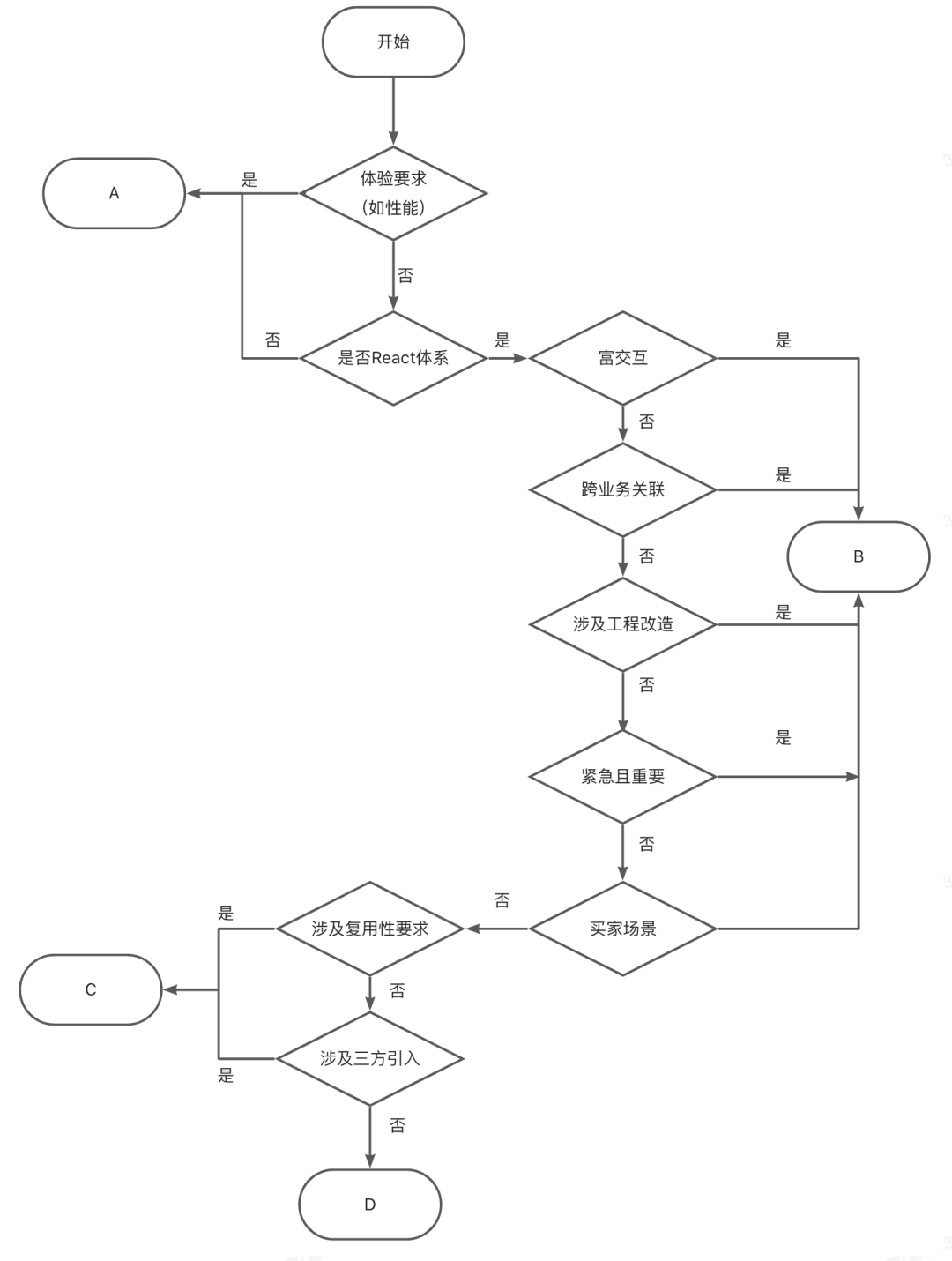
2.2 需求评估
前端同学根据需求分级流程完成需求定级
与专业前端协商后指定需求承接同学
承接同学评估工时
工时对焦及优化(专业前端、承接同学)
2.3 需求开发 & 发布
准备工作 代码开发 本地调试 发布
2.4 需求质量保障
所有全栈研发的代码由业务前端owner或师兄强制CR;
发起CR时机,在完成项目开发和自测后,全栈同学需及时提交CR给师兄和业务前端owner;
师兄和业务前端owner完成代码review后,全栈同学按照要求进行代码修复;
统计千行缺陷率、可自测发现率、线上问题数、预警量等指标,纳入全栈交付质量统计; 线上故障由业务前端owner和实际开发人共同处理,线上缺陷由全栈开发同学修复;
2.5 需求复盘
三、全栈需求实践
3.1 背景
3.2 准备工作
3.2.1 环境准备
3.2.2 熟悉代码
alita-xianzhi |--- hook // 钩子脚本 |--- .eslintignore // eslint格式校验忽略文件 |--- .eslintrc.js // esliint格式配置文件 |--- package.json // 依赖包版本(类似pom.xml) |--- src // 源代码 |-- common // 定义项目常量,比如目录,常用文字说明等 |-- components // 公共组件目录 |-- entry // 跳转页 |-- pages // 页面代码,文件名与 URL 路径相对应 |-- service // 服务,接口请求地址 |-- utils // 公用方法 |-- index.jsx // 主页 |-- index.scss // 主页样式css |-- tab-config.js // 路由配置3.2.3 新建变更
3.3 代码开发
3.3.1 模块划分
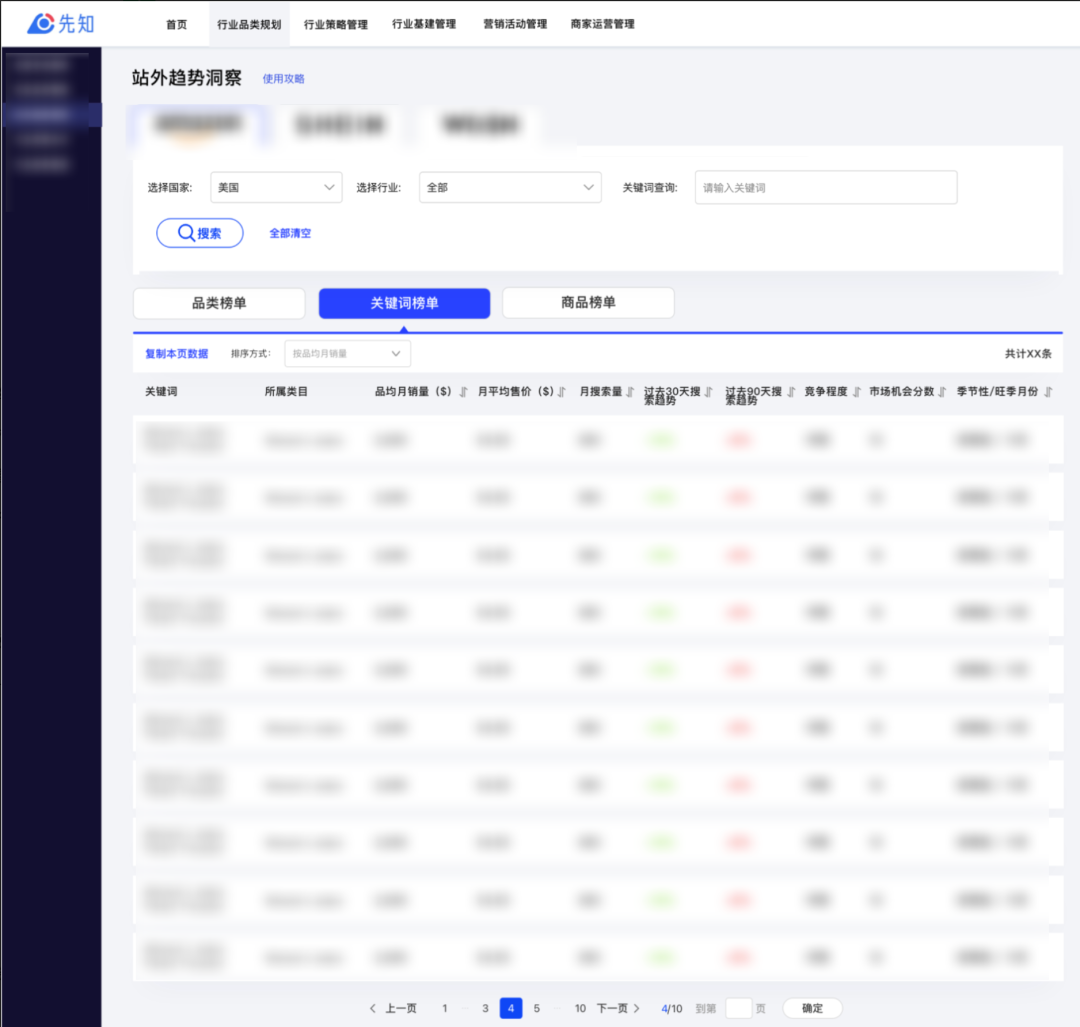
筛选栏:展示筛选项、搜索栏
详情Tab:展示多个Tab,本次开发的关键词榜单就是其中一个Tab页面
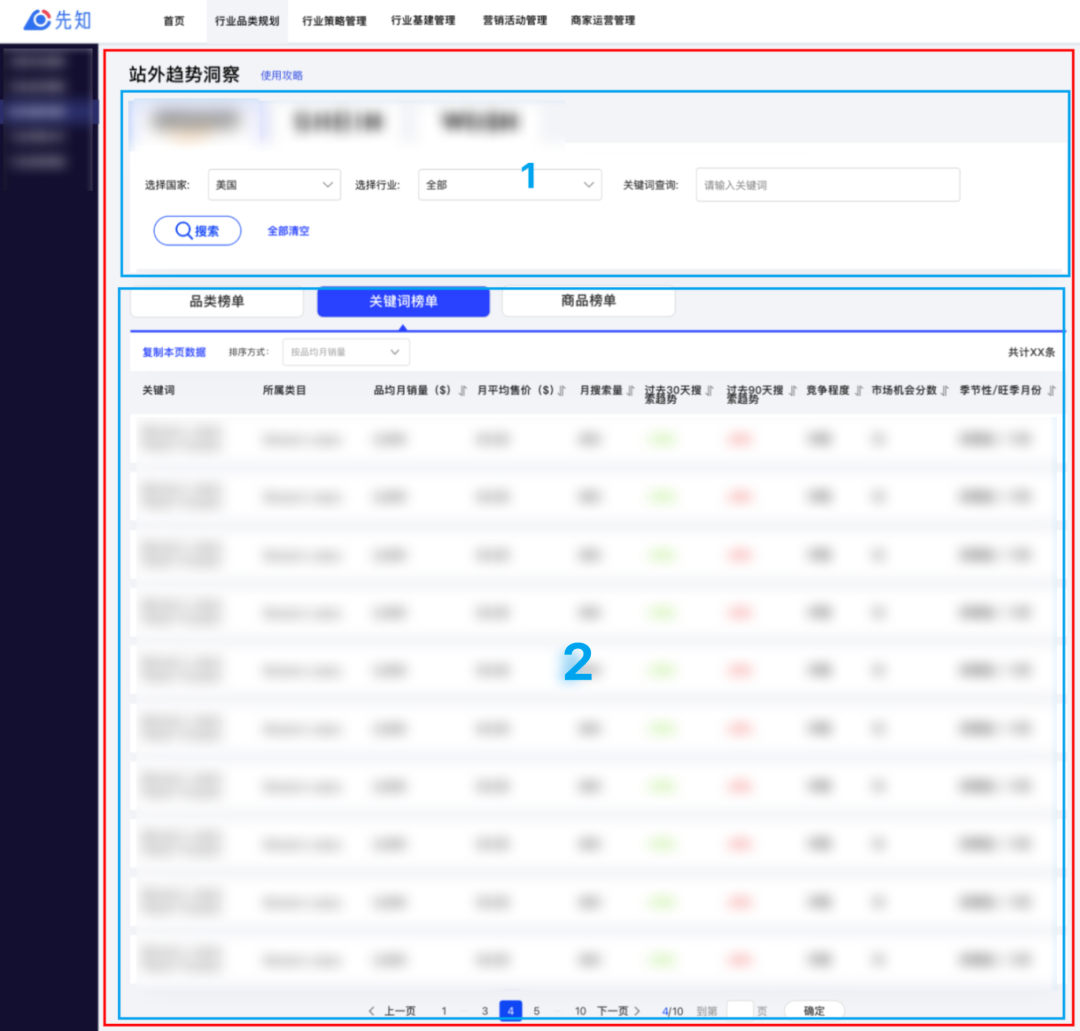
筛选栏改造:改造query-header-container文件夹下的组件代码
详情Tab:在aaa文件夹下新增keyword-table文件夹,然后在里面写代码
src |-- pages |-- outside-opportunity-discovery |-- components // 站外机会发现组件 |-- query-header-container // 筛选框组件 |-- index.jsx // 筛选框组件主页 |-- index.scss // 筛选框组件主页样式 |-- aaa // aaa榜单 |-- keyword-table // aaa关键词榜单列表 |-- index.jsx // aaa关键词榜单主页 |-- index.scss // aaa关键词榜单主页样式 |-- index.jsx // aaa榜单主页 |-- index.scss // aaa榜单主页样式3.3.2 筛选栏开发


class QueryContainer extends Component { render(){ return ( {currentTab === 'keyword' && ( 关键词榜单筛选栏 )} {currentTab !== 'keyword' && ( 品类榜单筛选栏 )} ); }}上例中,相当于有两个if条件语句,伪代码如下:
if(currentTab == 'keyword'){ 展示关键词榜单筛选栏}if(currentTab != 'keyword'){ 展示品类榜单筛选栏}
同时,React也支持三目运算符,例如:
class QueryContainer extends Component { render(){ return ( {currentTab === 'keyword' ? ( 关键词榜单筛选栏 ) : ( 品类榜单筛选栏 )} ); }}通过以上逻辑判断,可以实现对筛选栏的改造,根据不同Tab展示不同样式。
3.3.3 详情Tab开发
目标样式 

解决思路 整个列表可以被分为两部分:表头和表数据。为了保持整个站外商品库榜单的风格统一,这里没有选择直接使用Table组件,而是选择了定制化程度更高的Grid栅格布局,通过将页面分为10列多行,最后通过css调整表格的样式。Grid栅格布局支持按照行、列构建页面,将页面分为多个网格,非常方便自定义页面风格。例如: class keywordTable extends Component { render(){ return (
Grid栅格布局将每一个行划分为24个小列,只需要指定span,即可按比例设置列的宽度。className可以轻松的定制每个网格的样式。上例中,使用Grid栅格布局渲染了一行,并将其平分为两列。
渲染表头 表头与表数据样式不同,同时内容也是固定的,所以可以单独渲染,我将其抽为单独的渲染函数,部分代码如下: class keywordTable extends Component { renderTableHeader(){ return (
在每个网格内,可以任意的渲染组件,比如上例中我就在其中一个网格内嵌入了下降图标的Icon。React还支持动态的拼接每个组件的className,上例中,我封装了一个动态获取className的方法,用于实现点击排序后,排序字段高亮的样式。
渲染表数据 表数据的每一行对前端来说是相同的,只需要遍历表数据,一行一行的进行渲染即可,部分代码如下: class KeywordTable extends Component { renderTableKeyword(){ return ( {dataList.map((item = {}, index) => { return ( 上例中,首先遍历数据列表中的每一个对象,在遍历时,需要给对象设置默认值,避免对象为null导致页面渲染异常,然后取对象中的各属性值并渲染到网格中。
组装渲染函数 上面将数据列表拆分为表头和表数据进行渲染,最后需要将两者放到组件的渲染函数中才会生效,代码如下: class KeywordTable extends Component { render(){ return ( {this.renderTableHeader()} {this.renderTableKeyword()} ); }}
3.3.4 组件通信开发
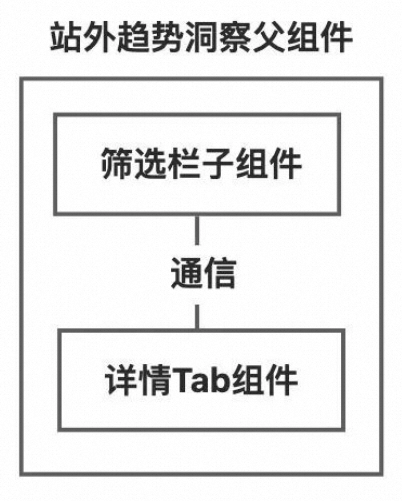
上文提到筛选栏的样式需要在原有基础上进行改造,根据用户选择的不同详情Tab确定展示的样式,但在渲染筛选栏组件时,还无法确定当前用户选择的是哪个Tab;同时,筛选栏选择不同的筛选项并通过请求后端接口返回不同数据后,需要让数据列表展示不同的数据,但拉取数据和展示数据是在两个组件中完成的。这些地方就涉及到组件之间的通信,需要让筛选栏与下方的详情Tab交互,从而执行不同的渲染逻辑。 类比后端,每个组件相当于一个类,组件渲染出来的页面效果即是一个对象,想要实现两个对象之间的通信,可以有两种思路: 两个对象之间本身存在包含关系,例如对象A包含对象B,这时候A可以轻松的获取B的属性;
两个对象之间存在一个媒介,通过媒介进行交互,例如对象C同时包含对象A和对象B,这时候A和B可以通过C轻松交互;
这里我使用了第2种思路,也就是父组件。内容页面同时包含了筛选栏和详情Tab两个组件,这就是天然的媒介。父组件中维护两个子组件需要通信的变量作为属性,子组件通过读写父组件中的属性来完成交互。 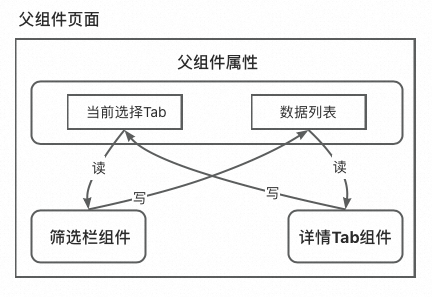
子组件读父组件属性 state
Java中的类属性可以直接定义在类中;与之相似,每个前端的组件也可以维护自己的属性,区别在于,前端组件的属性需要放在state中。例如: class AAA extends Component { state = { currentTab: 'keyword', dataList: [] } render(){ const {currentTab} = this.state }}
props
在Java中,类的初始化使用构造器,解析构造器中的参数实例化对象;与之相似,前端组件在渲染时,可以通过解析传入参数初始化,这个参数统一封装到props中,可以通过this.props访问。例如: class QueryContainer extends Component { render() { const {currentTab} = this.props; }}
通过以上方法,可以让子组件随时感知到父组件的属性值变化,只要currentTab值改变,React框架会检测到props值改变,从而触发子组件重新渲染,调用render()函数,最终实现根据不同Tab渲染不同筛选栏的效果。 子组件写父组件属性 Java支持将函数作为Function对象进行参数传递,与之相同,React框架也支持将函数作为参数,通过props传递。如果子组件希望写父组件属性,只需要将父组件中写state值的操作封装为函数,然后传递给子组件即可。例如: class AAA extends Component { state = { currentTab: 'keyword', dataList: [] } setDataList(newDataList){ this.setState({newDataList}); } render(){ const {currentTab} = this.state }}class QueryContainer extends Component { onSearchBtnClick(){ // 构造新的dataList newDataList = ...; this.props.setDataList(newDataList); }}
3.4 本地调试
3.4.1 代理配置
前端代码在开发完后可以在本地直接启动、并调用服务端的预发接口,从而实现本地调试,步骤如下: 确定待代理的URL
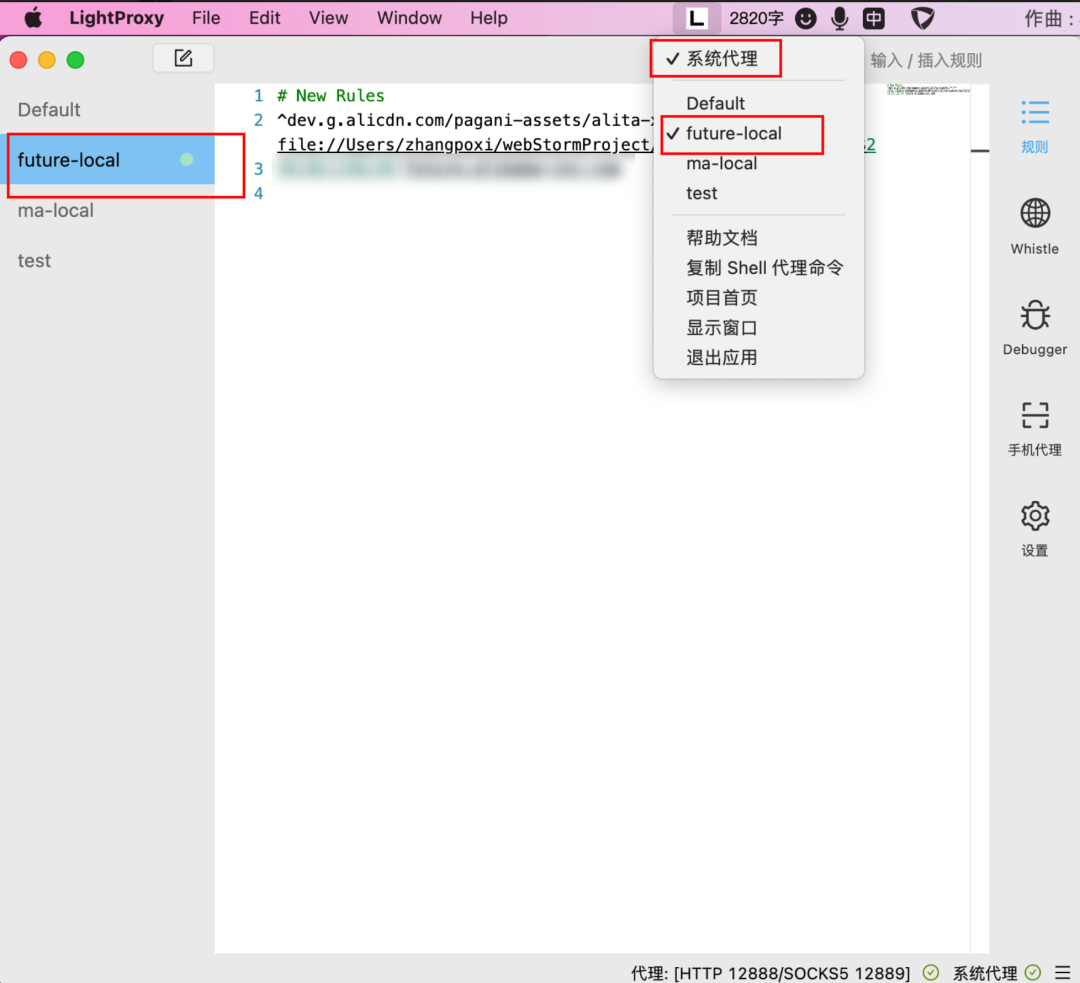
使用LightProxy配置前端代码Host绑定,例如:
^dev.g.alicdn.com/pagani-assets/alita-xianzhi/**/** file://Users/zhangpoxi/webStormProject/alita-xianzhi/build/$2
本例中的绑定将所有包含路径dev.g.alicdn.com/pagani-assets/alita-xianzhi的http访问请求代理到前端代码编译得到的文件夹中,实现本地调试的效果
使用LightProxy配置后端预发接口代理,例如:
127.0.0.1 future.alibaba-inc.com
本例中将所有访问域名的请求路由到指定ip的机器上,实现本地访问预发接口的效果 启动LightProxy代理,如下图,如果LightProxy左侧配置项上有绿点,且菜单栏中的系统代理项前有小勾,则表示代理生效中
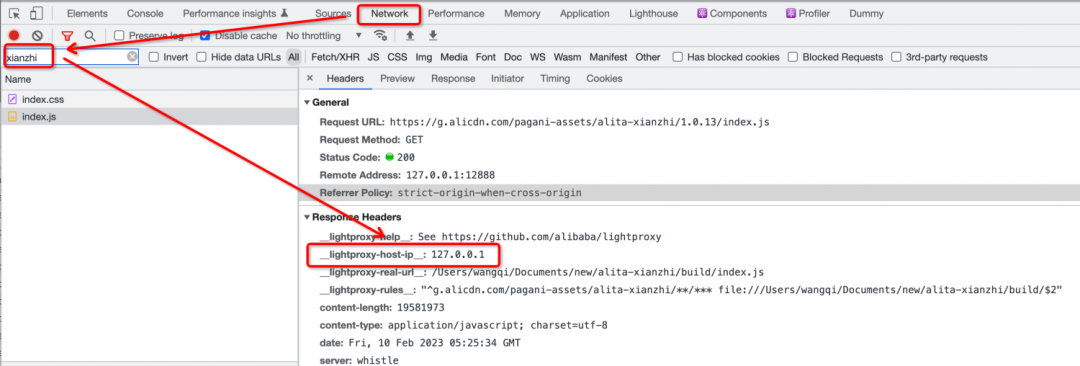
3.4.2 如何判断代理是否生效
打开浏览器,打开“开发者工具”,Chrome浏览器快捷键F12
访问代理的URL
搜索被代理的前端请求中的任意字符串,比如xianzhi
查看访问的ip地址,如果是127.0.0.1则说明代理生效
3.5 发布
用户看到的页面本质上将就是文件,所以前端代码打包完成后都会推送到CDN,通过版本号确定需要拉取的文件,如图所示主要分为以下几步: 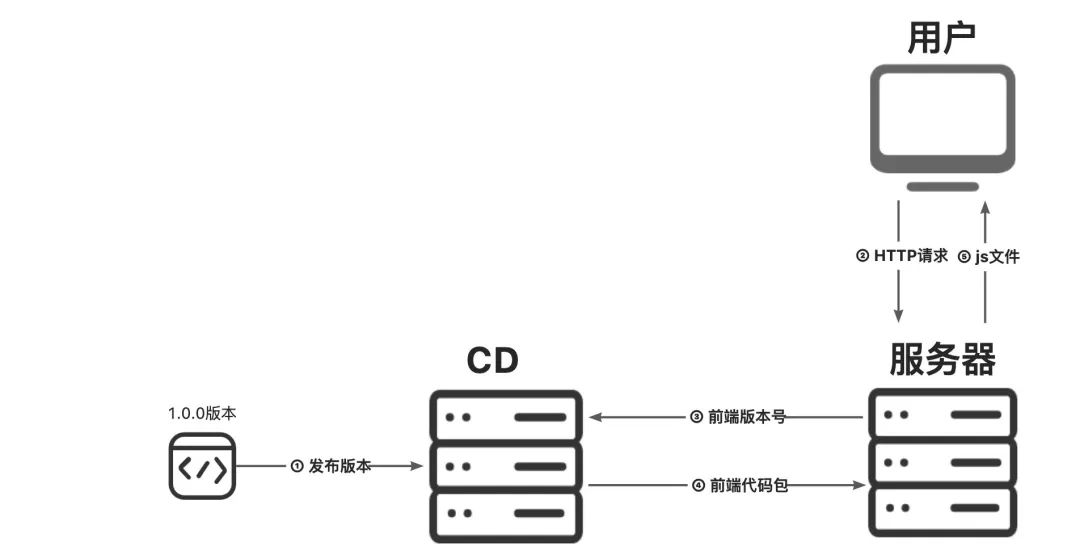
开发同学将前端代码打包并推送到CDN上;
用户访问服务器,服务器确定当前使用的版本号;
服务器向CDN请求某版本号的前端代码包;
CDN找到对应的前端代码并返回给服务器;
服务器向用户响应页面文件。
3.6 常见问题
3.6.1 npm安装依赖失败
现象 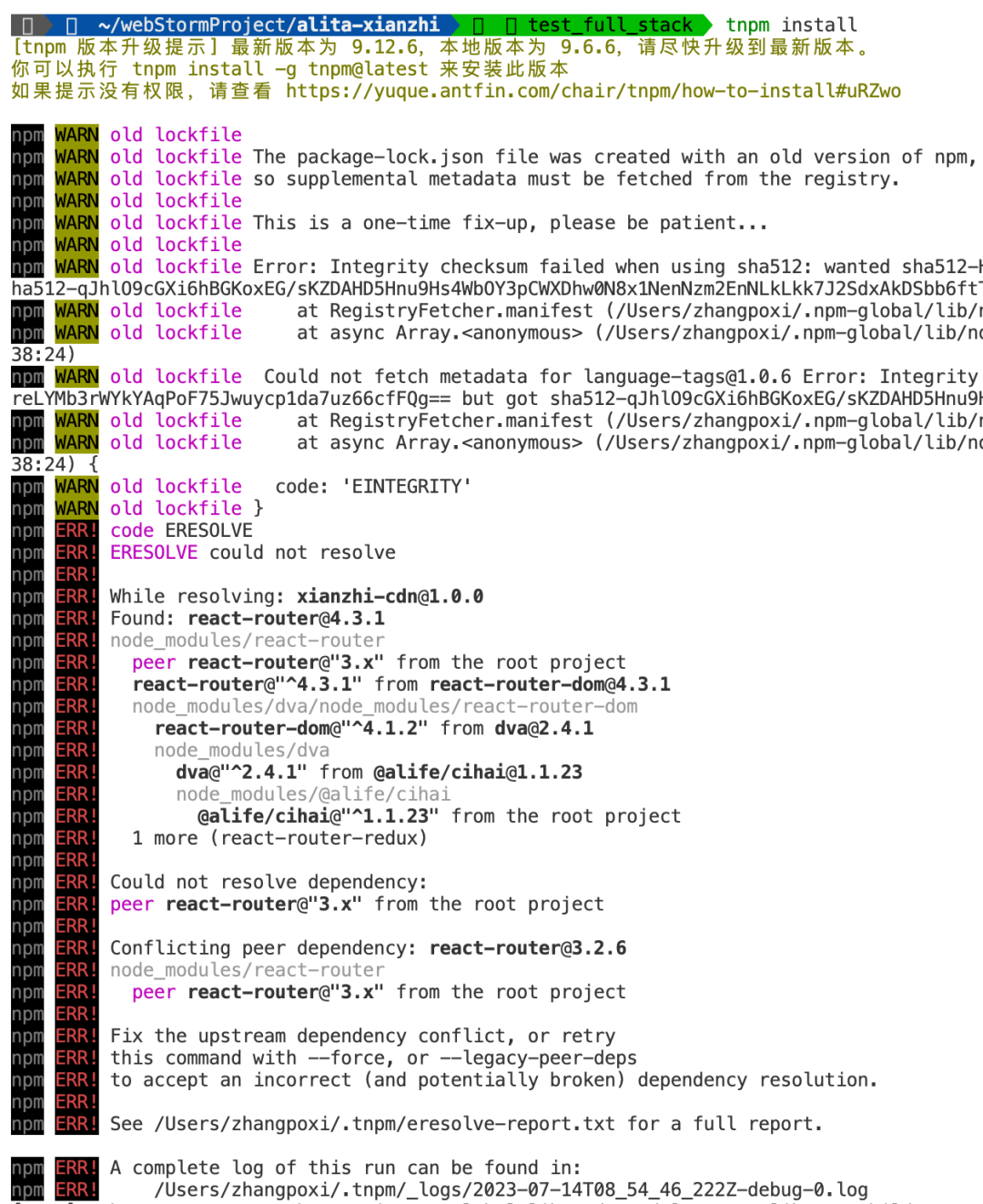
原因 npm本质上是一个类似于Maven的包管理器,如上报错是因为项目依赖版本出现冲突,导致npm不知道使用哪个版本,这时候可以直接强制安装,使用package.json中配置的版本即可 解决办法 使用命令行npm install –force替换tnpm install 3.6.2 代理不生效
现象 访问页面时本地修改代码不生效 原因 可能导致该现象的原因较多,比如: LigthProxy代理配置错误
LigthProxy代理失败或未启动
页面缓存导致代理不生效
解决办法 检查本地项目启动是否成功
访问路径是否正确
LightProxy开启是否成功
LightProxy中配置的本地资源路径是否正确
清空缓存,重启LightProxy,多刷新几次试试
四、全栈开发心得
培养全局视角,加深领域专业度
在传统的需求迭代交付中,开发总是站在某一个视角看整个业务,对业务整体框架缺乏认知。通过全栈交付,为开发同学提供更高的维度、更全局的视角,这样可以更好地理解业务模型、业务流程和不同模块之间的关系,从而更好地把握业务的本质和目标,提升领域理解,加深领域专业度,更快成为某个领域的专家。
降低沟通成本,提升交付效率
沟通成本在迭代需求交付过程中已经成为不可忽视的一部分,尤其是跨团队的需求对接,接口沟通、联调将会花费大量时间。通过全栈进行需求交付,省去了多人之间的沟通成本,让开发专注在需求上,而不是与外部沟通上。全栈交付也可以在一定程度上避免返工问题,比如在定义接口的时候,有些细节没考虑清楚,导致出入参的结构存在一些问题。如果是非全栈需求,需要重新跟前端同学对接,针对接口是否合理的讨论可能就会花费1个小时,然后前段再重新开发页面,浪费大量时间。而如果是全栈需求,我可以直接修改接口,不需要跟前端同学再去交流一遍,前端页面也可以在后端接口确认之后再开始搭建,不存在返工问题。
拓展技术广度,增强个人竞争力
当下,AI能力越来越强,降低了跨栈开发的门槛,人人都可以借助AI能力,进行跨栈开发,我们在深挖专业技能的同时,技术广度也是不可获取的一部分,全栈能力必然是大势所趋。目前先知的全栈实践局限在前端、后端,未来的全栈可以继续向数据开发、算法等方向发展,一人成军,让迭代需求交付没有卡点。未来的技术发展需要拥有全栈能力的人才能够更好地适应,跨界合作将成为趋势。因此,通过拓展技术广度,不仅可以增强个人竞争力,还能够在职场中获得更多的机会和挑战,实现自我价值的最大化。
作者|慕钦
本文来自博客园,作者:古道轻风,转载请注明原文链接:https://www.cnblogs.com/88223100/p/The-Technical-Practice-Path-of-a-Full-Stack-Engineer.html