前言
比较Hygon7280、Intel、AMD、鲲鹏920、飞腾2500的性能情况
| CPU型号 | Hygon 7280 | AMD 7H12 | AMD 7T83 | Intel 8163 | 鲲鹏920 | 飞腾2500 | 倚天710 |
|---|---|---|---|---|---|---|---|
| 物理核数 | 32 | 32 | 64 | 24 | 48 | 64 | 128core |
| 超线程 | 2 | 2 | 2 | 2 | |||
| 路 | 2 | 2 | 2 | 2 | 2 | 2 | 1 |
| NUMA Node | 8 | 2 | 4 | 2 | 4 | 16 | 2 |
| L1d | 32K | 32K | 32K | 32K | 64K | 32K | 64K |
| L2 | 512K | 512K | 512K | 1024K | 512K | 2048K | 1024K |
AMD 7T83 有8个Die, 每个Die L3大小 32M,L2 大小4MiB, 每个Die上 L1I/L1D 各256KiB,每个Die有8core,2、3代都是带有独立 IO Die
倚天710是一路服务器,单芯片2块对称的 Die

参与比较的几款CPU参数
IPC的说明:
IPC: insns per cycle insn/cycles 也就是每个时钟周期能执行的指令数量,越大程序跑的越快
程序的执行时间 = 指令数/(主频*IPC) //单核下,多核的话再除以核数
Hygon 7280
Hygon 7280 就是AMD Zen架构,最大IPC能到5.
| 123456789101112131415161718192021222324252627282930 | 架构: x86_64CPU 运行模式: 32-bit, 64-bit字节序: Little EndianAddress sizes: 43 bits physical, 48 bits virtualCPU: 128在线 CPU 列表: 0-127每个核的线程数: 2每个座的核数: 32座: 2NUMA 节点: 8厂商 ID: HygonGenuineCPU 系列: 24型号: 1型号名称: Hygon C86 7280 32-core Processor步进: 1CPU MHz: 2194.586BogoMIPS: 3999.63虚拟化: AMD-VL1d 缓存: 2 MiBL1i 缓存: 4 MiBL2 缓存: 32 MiBL3 缓存: 128 MiBNUMA 节点0 CPU: 0-7,64-71NUMA 节点1 CPU: 8-15,72-79NUMA 节点2 CPU: 16-23,80-87NUMA 节点3 CPU: 24-31,88-95NUMA 节点4 CPU: 32-39,96-103NUMA 节点5 CPU: 40-47,104-111NUMA 节点6 CPU: 48-55,112-119NUMA 节点7 CPU: 56-63,120-127 |
架构说明:
每个CPU有4个Die,每个Die有两个CCX(2 core-Complexes),每个CCX最多有4core(例如7280/7285)共享一个L3 cache;每个Die有两个Memory Channel,每个CPU带有8个Memory Channel,并且每个Memory Channel最多支持2根Memory;
海光7系列架构图:
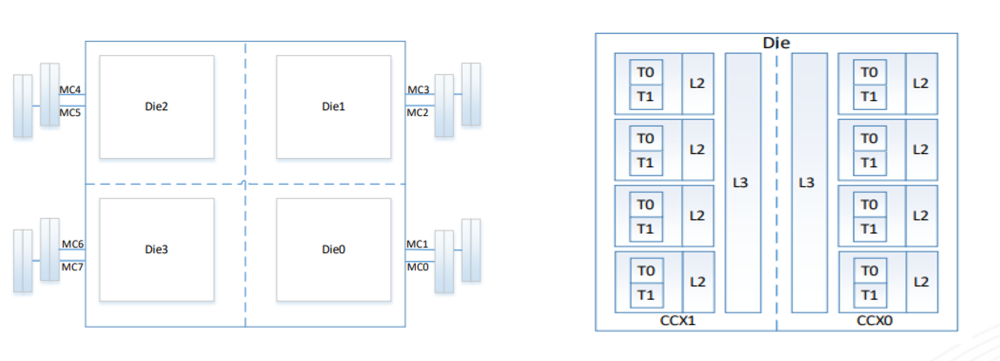
曙光H620-G30A 机型硬件结构,CPU是hygon 7280(截图只截取了Socket0)

AMD EPYC 7T83(NC)
两路服务器,4 numa node,Z3架构



详细信息:
| 1234567891011121314151617181920212223242526272829303132333435363738394041 | #lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 256On-line CPU(s) list: 0-255Thread(s) per core: 2Core(s) per socket: 64Socket(s): 2NUMA node(s): 4Vendor ID: AuthenticAMDCPU family: 25Model: 1Model name: AMD EPYC 7T83 64-Core ProcessorStepping: 1CPU MHz: 2154.005CPU max MHz: 2550.0000CPU min MHz: 1500.0000BogoMIPS: 5090.93Virtualization: AMD-VL1d cache: 32KL1i cache: 32KL2 cache: 512KL3 cache: 32768KNUMA node0 CPU(s): 0-31,128-159NUMA node1 CPU(s): 32-63,160-191NUMA node2 CPU(s): 64-95,192-223NUMA node3 CPU(s): 96-127,224-255#cat /sys/devices/system/cpu/cpu{0,1,8,16,30,31,32,128}/cache/index3/shared_cpu_map00000000,00000000,00000000,000000ff,00000000,00000000,00000000,000000ff00000000,00000000,00000000,000000ff,00000000,00000000,00000000,000000ff00000000,00000000,00000000,0000ff00,00000000,00000000,00000000,0000ff0000000000,00000000,00000000,00ff0000,00000000,00000000,00000000,00ff000000000000,00000000,00000000,ff000000,00000000,00000000,00000000,ff00000000000000,00000000,00000000,ff000000,00000000,00000000,00000000,ff00000000000000,00000000,000000ff,00000000,00000000,00000000,000000ff,0000000000000000,00000000,00000000,000000ff,00000000,00000000,00000000,000000ff#cat /sys/devices/system/cpu/cpu0/cache/index2/shared_cpu_map00000000,00000000,00000000,00000001,00000000,00000000,00000000,00000001 |
L3是8个物理核,16个超线程共享,相当于单核2MB,一块CPU有8个L3,总共是256MB
| 12345678910111213141516 | #cat cpu0/cache/index3/shared_cpu_list0-7,128-135#cat cpu0/cache/index3/size32768K#cat cpu0/cache/index2/shared_cpu_list0,128#cat /sys/devices/system/cpu/cpu{0,1,8,16,30,31,32,128}/cache/index3/shared_cpu_list0-7,128-1350-7,128-1358-15,136-14316-23,144-15124-31,152-15924-31,152-15932-39,160-1670-7,128-135 |
L1D、L1I各为 2MiB,单物理核为32KB
空跑nop的IPC为6(有点吓人)
| 12345678910111213141516 | #perf stat ./cpu/testPerformance counter stats for process id ‘449650’:2,574.29 msec task-clock # 1.000 CPUs utilized0 context-switches # 0.000 K/sec0 cpu-migrations # 0.000 K/sec0 page-faults # 0.000 K/sec8,985,622,182 cycles # 3.491 GHz (83.33%)4,390,929 stalled-cycles-frontend # 0.05% frontend cycles idle (83.34%)4,387,560,442 stalled-cycles-backend # 48.83% backend cycles idle (83.34%)53,711,907,863 instructions # 5.98 insn per cycle# 0.08 stalled cycles per insn (83.34%)418,902,363 branches # 162.725 M/sec (83.34%)15,036 branch-misses # 0.00% of all branches (83.32%)2.574347594 seconds time elapsed |
sysbench 测试7T83 比7H12 略好,可能是ECS、OS等带来的差异。
测试环境:4.19.91-011.ali4000.alios7.x86_64,5.7.34-log MySQL Community Server (GPL)
| 测试核数 | AMD EPYC 7H12 2.5G(QPS、IPC) | 说明 |
|---|---|---|
| 单核 | 24363 0.58 | CPU跑满 |
| 一对HT | 33519 0.40 | CPU跑满 |
| 2物理核(0-1) | 48423 0.57 | CPU跑满 |
| 2物理核(0,32) 跨node | 46232 0.55 | CPU跑满 |
| 2物理核(0,64) 跨socket | 45072 0.52 | CPU跑满 |
| 4物理核(0-3) | 97759 0.58 | CPU跑满 |
| 16物理核(0-15) | 367992 0.55 | CPU跑满,sys占比20%,si 10% |
| 32物理核(0-31) | 686998 0.51 | CPU跑满,sys占比20%, si 12% |
| 64物理核(0-63) | 1161079 0.50 | CPU跑到95%以上,sys占比20%, si 12% |
| 64物理核(0-31,64-95) | 964441 0.49 | socket2上的32核一直比较闲,数据无参考意义 |
| 64物理核(0-31,64-95) | 1147846 0.48 | 重启mysqld,立即绑核,sysbench 在32-63上,导致0-31的CPU只能跑到89% |
说明,压测过程动态通过taskset绑核,所以会有数据残留其它核的cache问题
跨socket taskset绑核的时候要压很久任务才会跨socket迁移过去,也就是刚taskset后CPU是跑不满的
| 1234567891011121314151617181920 | #numastat -p 437803Per-node process memory usage (in MBs) for PID 437803 (mysqld)Node 0 Node 1 Node 2————— ————— —————Huge 0.00 0.00 0.00Heap 1.15 0.00 5403.27Stack 0.00 0.00 0.09Private 1921.60 16.22 10647.66—————- ————— ————— —————Total 1922.75 16.22 16051.02Node 3 Total————— —————Huge 0.00 0.00Heap 0.03 5404.45Stack 0.00 0.09Private 16.20 12601.68—————- ————— —————Total 16.23 18006.22 |
AMD EPYC 7H12(ECS)
AMD EPYC 7H12 64-Core(ECS,非物理机),最大IPC能到5.
| 1234567891011121314151617181920212223242526 | # lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 64On-line CPU(s) list: 0-63Thread(s) per core: 2Core(s) per socket: 16座: 2NUMA 节点: 2厂商 ID: AuthenticAMDCPU 系列: 23型号: 49型号名称: AMD EPYC 7H12 64-Core Processor步进: 0CPU MHz: 2595.124BogoMIPS: 5190.24虚拟化: AMD-V超管理器厂商: KVM虚拟化类型: 完全L1d 缓存: 32KL1i 缓存: 32KL2 缓存: 512KL3 缓存: 16384KNUMA 节点0 CPU: 0-31NUMA 节点1 CPU: 32-63 |
AMD EPYC 7T83 ECS
| 123456789101112131415161718192021222324252627282930313233 | [root@bugu88 cpu0]# cd /sys/devices/system/cpu/cpu0[root@bugu88 cpu0]# cat cache/index0/size32K[root@bugu88 cpu0]# cat cache/index1/size32K[root@bugu88 cpu0]# cat cache/index2/size512K[root@bugu88 cpu0]# cat cache/index3/size32768K[root@bugu88 cpu0]# lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 16On-line CPU(s) list: 0-15Thread(s) per core: 2Core(s) per socket: 8座: 1NUMA 节点: 1厂商 ID: AuthenticAMDCPU 系列: 25型号: 1型号名称: AMD EPYC 7T83 64-Core Processor步进: 1CPU MHz: 2545.218BogoMIPS: 5090.43超管理器厂商: KVM虚拟化类型: 完全L1d 缓存: 32KL1i 缓存: 32KL2 缓存: 512KL3 缓存: 32768KNUMA 节点0 CPU: 0-15 |
stream:
| 12345678910111213141516171819 | [root@bugu88 lmbench-master]# for i in $(seq 0 15); do echo $i; numactl -C $i -m 0 ./bin/stream -W 5 -N 5 -M 64M; done0STREAM copy latency: 0.68 nanosecondsSTREAM copy bandwidth: 23509.84 MB/secSTREAM scale latency: 0.69 nanosecondsSTREAM scale bandwidth: 23285.51 MB/secSTREAM add latency: 0.96 nanosecondsSTREAM add bandwidth: 25043.73 MB/secSTREAM triad latency: 1.40 nanosecondsSTREAM triad bandwidth: 17121.79 MB/sec1STREAM copy latency: 0.68 nanosecondsSTREAM copy bandwidth: 23513.96 MB/secSTREAM scale latency: 0.68 nanosecondsSTREAM scale bandwidth: 23580.06 MB/secSTREAM add latency: 0.96 nanosecondsSTREAM add bandwidth: 25049.96 MB/secSTREAM triad latency: 1.35 nanosecondsSTREAM triad bandwidth: 17741.93 MB/sec |
Intel 8163
这次对比测试的Intel 8163 CPU信息如下,最大IPC 是4:
| 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253 | #lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 96On-line CPU(s) list: 0-95Thread(s) per core: 2Core(s) per socket: 24Socket(s): 2NUMA node(s): 1Vendor ID: GenuineIntelCPU family: 6Model: 85Model name: Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHzStepping: 4CPU MHz: 2499.121CPU max MHz: 3100.0000CPU min MHz: 1000.0000BogoMIPS: 4998.90Virtualization: VT-xL1d cache: 32KL1i cache: 32KL2 cache: 1024KL3 cache: 33792KNUMA node0 CPU(s): 0-95—–8269CY#lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 104On-line CPU(s) list: 0-103Thread(s) per core: 2Core(s) per socket: 26Socket(s): 2NUMA node(s): 2Vendor ID: GenuineIntelCPU family: 6Model: 85Model name: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHzStepping: 7CPU MHz: 3200.000CPU max MHz: 3800.0000CPU min MHz: 1200.0000BogoMIPS: 4998.89Virtualization: VT-xL1d cache: 32KL1i cache: 32KL2 cache: 1024KL3 cache: 36608KNUMA node0 CPU(s): 0-25,52-77NUMA node1 CPU(s): 26-51,78-103 |
不同 intel 型号的差异
如下图是8269CY和E5-2682上跑的MySQL在相同业务、相同流量下的差异:

CPU使用率差异(下图8051C是E5-2682,其它是 8269CY,主频也有30%的差异)
鲲鹏920
| 1234567891011121314151617181920212223242526272829303132333435363738394041424344 | [root@ARM 19:15 /root/lmbench3]#numactl -Havailable: 4 nodes (0-3)node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23node 0 size: 192832 MBnode 0 free: 146830 MBnode 1 cpus: 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47node 1 size: 193533 MBnode 1 free: 175354 MBnode 2 cpus: 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71node 2 size: 193533 MBnode 2 free: 175718 MBnode 3 cpus: 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95node 3 size: 193532 MBnode 3 free: 183643 MBnode distances:node 0 1 2 30: 10 12 20 221: 12 10 22 242: 20 22 10 123: 22 24 12 10#lscpuArchitecture: aarch64Byte Order: Little EndianCPU(s): 96On-line CPU(s) list: 0-95Thread(s) per core: 1Core(s) per socket: 48Socket(s): 2NUMA node(s): 4Model: 0CPU max MHz: 2600.0000CPU min MHz: 200.0000BogoMIPS: 200.00L1d cache: 64KL1i cache: 64KL2 cache: 512KL3 cache: 24576KNUMA node0 CPU(s): 0-23NUMA node1 CPU(s): 24-47NUMA node2 CPU(s): 48-71NUMA node3 CPU(s): 72-95Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fcma dcpop asimddp asimdfhm |
飞腾2500
飞腾2500用nop去跑IPC的话,只能到1,但是跑其它代码能到2.33
| 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990 | #lscpuArchitecture: aarch64Byte Order: Little EndianCPU(s): 128On-line CPU(s) list: 0-127Thread(s) per core: 1Core(s) per socket: 64Socket(s): 2NUMA node(s): 16Model: 3BogoMIPS: 100.00L1d cache: 32KL1i cache: 32KL2 cache: 2048KL3 cache: 65536KNUMA node0 CPU(s): 0-7NUMA node1 CPU(s): 8-15NUMA node2 CPU(s): 16-23NUMA node3 CPU(s): 24-31NUMA node4 CPU(s): 32-39NUMA node5 CPU(s): 40-47NUMA node6 CPU(s): 48-55NUMA node7 CPU(s): 56-63NUMA node8 CPU(s): 64-71NUMA node9 CPU(s): 72-79NUMA node10 CPU(s): 80-87NUMA node11 CPU(s): 88-95NUMA node12 CPU(s): 96-103NUMA node13 CPU(s): 104-111NUMA node14 CPU(s): 112-119NUMA node15 CPU(s): 120-127Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 cpuid#perf stat ./nopfailed to read counter stalled-cycles-frontendfailed to read counter stalled-cycles-backendfailed to read counter branchesPerformance counter stats for ‘./nop’:78638.700540 task-clock (msec) # 0.999 CPUs utilized1479 context-switches # 0.019 K/sec55 cpu-migrations # 0.001 K/sec37 page-faults # 0.000 K/sec165127619524 cycles # 2.100 GHz stalled-cycles-frontend stalled-cycles-backend165269372437 instructions # 1.00 insns per cycle branches3057191 branch-misses # 0.00% of all branches78.692839007 seconds time elapsed#dmidecode -t processor# dmidecode 3.0Getting SMBIOS data from sysfs.SMBIOS 3.2.0 present.# SMBIOS implementations newer than version 3.0 are not# fully supported by this version of dmidecode.Handle 0x0004, DMI type 4, 48 bytesProcessor InformationSocket Designation: BGA3576Type: Central ProcessorFamily: Manufacturer: PHYTIUMID: 00 00 00 00 70 1F 66 22Version: S2500Voltage: 0.8 VExternal Clock: 50 MHzMax Speed: 2100 MHzCurrent Speed: 2100 MHzStatus: Populated, EnabledUpgrade: OtherL1 Cache Handle: 0x0005L2 Cache Handle: 0x0007L3 Cache Handle: 0x0008Serial Number: N/AAsset Tag: No Asset TagPart Number: NULLCore Count: 64Core Enabled: 64Thread Count: 64Characteristics:64-bit capableMulti-CoreHardware ThreadExecute ProtectionEnhanced VirtualizationPower/Performance Control |
其它
2Die,2node
| 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475 | #lscpuArchitecture: aarch64Byte Order: Little EndianCPU(s): 128On-line CPU(s) list: 0-127Thread(s) per core: 1Core(s) per socket: 128Socket(s): 1NUMA node(s): 2Model: 0BogoMIPS: 100.00L1d cache: 64KL1i cache: 64KL2 cache: 1024KL3 cache: 65536K //64core shareNUMA node0 CPU(s): 0-63NUMA node1 CPU(s): 64-127Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fcma lrcpc dcpop sha3 sm3 sm4 asimddp sha512 sve asimdfhm dit uscat ilrcpc flagm ssbs sb dcpodp sve2 sveaes svepmull svebitperm svesha3 svesm4 flagm2 frint svei8mm svebf16 i8mm bf16 dgh#cat cpu{0,1,8,16,30,31,32,127}/cache/index3/shared_cpu_list0-630-630-630-630-630-630-6364-127#grep -E “core|64.000” lat.logcore:064.00000 59.653core:864.00000 62.265core:1664.00000 59.411core:2464.00000 55.836core:3264.00000 55.909core:4064.00000 56.176core:4864.00000 57.240core:5664.00000 59.485core:6464.00000 131.818core:7264.00000 127.182core:8064.00000 122.452core:8864.00000 121.673core:9664.00000 126.533core:10464.00000 125.673core:11264.00000 124.188core:12064.00000 130.202#numactl -Havailable: 2 nodes (0-1)node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63node 0 size: 515652 MBnode 0 free: 514913 MBnode 1 cpus: 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127node 1 size: 516086 MBnode 1 free: 514815 MBnode distances:node 0 10: 10 151: 15 10 |
单核以及HT计算Prime性能比较
以上两款CPU但从物理上的指标来看似乎AMD要好很多,从工艺上AMD也要领先一代(2年),从单核参数上来说是2.0 VS 2.5GHz,但是IPC 是5 VS 4,算下来理想的单核性能刚好一致(25=2.54)。
从外面的一些跑分结果显示也是AMD 要好,但是实际性能怎么样呢?
测试命令,这个测试命令无论在哪个CPU下,用2个物理核用时都是一个物理核的一半,所以这个计算是可以完全并行的
| 1 | taskset -c 1 /usr/bin/sysbench –num-threads=1 –test=cpu –cpu-max-prime=50000 run //单核用一个threads,绑核; HT用2个threads,绑一对HT |
测试结果为耗时,单位秒
| 测试项 | AMD EPYC 7H12 2.5G CentOS 7.9 | Hygon 7280 2.1GHz CentOS | Hygon 7280 2.1GHz 麒麟 | Intel 8269 2.50G | Intel 8163 CPU @ 2.50GHz | Intel E5-2682 v4 @ 2.50GHz |
|---|---|---|---|---|---|---|
| 单核 prime 50000 耗时 | 59秒 IPC 0.56 | 77秒 IPC 0.55 | 89秒 IPC 0.56; | 83 0.41 | 105秒 IPC 0.41 | 109秒 IPC 0.39 |
| HT prime 50000 耗时 | 57秒 IPC 0.31 | 74秒 IPC 0.29 | 87秒 IPC 0.29 | 48 0.35 | 60秒 IPC 0.36 | 74秒 IPC 0.29 |
相同CPU下的 指令数 基本= 耗时IPC核数
以上测试结果显示Hygon 7280单核计算能力是要强过Intel 8163的,但是超线程在这个场景下太不给力,相当于没有。
当然上面的计算Prime太单纯了,代表不了复杂的业务场景,所以接下来用MySQL的查询场景来看看。
如果是arm芯片在计算prime上明显要好过x86,猜测是除法取余指令上有优化
| 12 | #taskset -c 11 sysbench cpu –threads=1 –events=50000 runsysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2) |
测试结果为10秒钟的event
| 测试项 | FT2500 2.1G | 鲲鹏920-4826 2.6GHz | Intel 8163 CPU @ 2.50GHz | Hygon C86 7280 2.1GHz | AMD 7T83 |
|---|---|---|---|---|---|
| 单核 prime 10秒 events | 21626 IPC 0.89 | 30299 IPC 1.01 | 8435 IPC 0.41 | 10349 IPC 0.63 | 40112 IPC 1.38 |
对比MySQL sysbench和tpcc性能
分别将MySQL 5.7.34社区版部署到intel+AliOS以及hygon 7280+CentOS上,将mysqld绑定到单核,一样的压力配置均将CPU跑到100%,然后用sysbench测试点查, HT表示将mysqld绑定到一对HT核。
sysbench点查
测试命令类似如下:
| 1 | sysbench –test=’/usr/share/doc/sysbench/tests/db/select.lua’ –oltp_tables_count=1 –report-interval=1 –oltp-table-size=10000000 –mysql-port=3307 –mysql-db=sysbench_single –mysql-user=root –mysql-password=’Bj6f9g96!@#’ –max-requests=0 –oltp_skip_trx=on –oltp_auto_inc=on –oltp_range_size=5 –mysql-table-engine=innodb –rand-init=on –max-time=300 –mysql-host=x86.51 –num-threads=4 run |
测试结果(测试中的差异AMD、Hygon CPU跑在CentOS7.9, intel CPU、Kunpeng 920 跑在AliOS上, xdb表示用集团的xdb替换社区的MySQL Server, 麒麟是国产OS):
| 测试核数 | AMD EPYC 7H12 2.5G | Hygon 7280 2.1G | Hygon 7280 2.1GHz 麒麟 | Intel 8269 2.50G | Intel 8163 2.50G | Intel 8163 2.50G XDB5.7 | 鲲鹏 920-4826 2.6G | 鲲鹏 920-4826 2.6G XDB8.0 | FT2500 alisql 8.0 本地–socket |
|---|---|---|---|---|---|---|---|---|---|
| 单核 | 24674 0.54 | 13441 0.46 | 10236 0.39 | 28208 0.75 | 25474 0.84 | 29376 0.89 | 9694 0.49 | 8301 0.46 | 3602 0.53 |
| 一对HT | 36157 0.42 | 21747 0.38 | 19417 0.37 | 36754 0.49 | 35894 0.6 | 40601 0.65 | 无HT | 无HT | 无HT |
| 4物理核 | 94132 0.52 | 49822 0.46 | 38033 0.37 | 90434 0.69 350% | 87254 0.73 | 106472 0.83 | 34686 0.42 | 28407 0.39 | 14232 0.53 |
| 16物理核 | 325409 0.48 | 171630 0.38 | 134980 0.34 | 371718 0.69 1500% | 332967 0.72 | 446290 0.85 //16核比4核好! | 116122 0.35 | 94697 0.33 | 59199 0.6 8core:31210 0.59 |
| 32物理核 | 542192 0.43 | 298716 0.37 | 255586 0.33 | 642548 0.64 2700% | 588318 0.67 | 598637 0.81 CPU 2400% | 228601 0.36 | 177424 0.32 | 114020 0.65 |
- 麒麟OS下CPU很难跑满,大致能跑到90%-95%左右,麒麟上装的社区版MySQL-5.7.29;飞腾要特别注意mysqld所在socket,同时以上飞腾数据都是走–sock压测所得,32core走网络压测QPS为:99496(15%的网络损耗)[^说明]
Mysqld 二进制代码所在 page cache带来的性能影响
如果是飞腾跨socket影响很大,mysqld二进制跨socket性能会下降30%以上
对于鲲鹏920,双路服务器上测试,mysqld绑在node0, 但是分别将mysqld二进制load进不同的node上的page cache,然后执行点查
| mysqld | node0 | node1 | node2 | node3 |
|---|---|---|---|---|
| QPS | 190120 IPC 0.40 | 182518 IPC 0.39 | 189046 IPC 0.40 | 186533 IPC 0.40 |
以上数据可以看出这里node0到node1还是很慢的,居然比跨socket还慢,反过来说鲲鹏跨socket性能很好
绑定mysqld到不同node的page cache操作
| 123456789101112131415161718192021222324 | #systemctl stop mysql-server[root@poc65 /root/vmtouch]#vmtouch -e /usr/local/mysql/bin/mysqldFiles: 1Directories: 0Evicted Pages: 5916 (23M)Elapsed: 0.00322 seconds#vmtouch -v /usr/local/mysql/bin/mysqld/usr/local/mysql/bin/mysqld[ ] 0/5916Files: 1Directories: 0Resident Pages: 0/5916 0/23M 0%Elapsed: 0.000204 seconds#taskset -c 24 md5sum /usr/local/mysql/bin/mysqld#grep mysqld /proc/`pidof mysqld`/numa_maps //检查mysqld具体绑定在哪个node上00400000 default file=/usr/local/mysql/bin/mysqld mapped=3392 active=1 N0=3392 kernelpagesize_kB=40199b000 default file=/usr/local/mysql/bin/mysqld anon=10 dirty=10 mapped=134 active=10 N0=134 kernelpagesize_kB=401a70000 default file=/usr/local/mysql/bin/mysqld anon=43 dirty=43 mapped=120 active=43 N0=120 kernelpagesize_kB=4 |
网卡以及node距离带来的性能差异
在鲲鹏920+mysql5.7+alios,将内存分配锁在node0上,然后分别绑核在1、24、48、72core,进行sysbench点查对比
| Core1 | Core24 | Core48 | Core72 | |
|---|---|---|---|---|
| QPS | 10800 | 10400 | 7700 | 7700 |
以上测试的时候业务进程分配的内存全限制在node0上(下面的网卡中断测试也是同样内存结构)
| 12345678910 | #/root/numa-maps-summary.pl </proc/123853/numa_mapsN0 : 5085548 ( 19.40 GB)N1 : 4479 ( 0.02 GB)N2 : 1 ( 0.00 GB)active : 0 ( 0.00 GB)anon : 5085455 ( 19.40 GB)dirty : 5085455 ( 19.40 GB)kernelpagesize_kB: 2176 ( 0.01 GB)mapmax : 348 ( 0.00 GB)mapped : 4626 ( 0.02 GB) |
对比测试,将内存锁在node3上,重复进行以上测试结果如下:
| Core1 | Core24 | Core48 | Core72 | |
|---|---|---|---|---|
| QPS | 10500 | 10000 | 8100 | 8000 |
| 1234567891011 | #/root/numa-maps-summary.pl </proc/54478/numa_mapsN0 : 16 ( 0.00 GB)N1 : 4401 ( 0.02 GB)N2 : 1 ( 0.00 GB)N3 : 1779989 ( 6.79 GB)active : 0 ( 0.00 GB)anon : 1779912 ( 6.79 GB)dirty : 1779912 ( 6.79 GB)kernelpagesize_kB: 1108 ( 0.00 GB)mapmax : 334 ( 0.00 GB)mapped : 4548 ( 0.02 GB) |
机器上网卡eth1插在node0上,由以上两组对比测试发现网卡影响比内存跨node影响更大,网卡影响有20%。而内存的影响基本看不到(就近好那么一点点,但是不明显,只能解释为cache命中率很高了)
此时软中断都在node0上,如果将软中断绑定到node3上,第72core的QPS能提升到8500,并且非常稳定。同时core0的QPS下降到10000附近。
网卡软中断以及网卡远近的测试结论
测试机器只是用了一块网卡,网卡插在node0上。
一般网卡中断会占用一些CPU,如果把网卡中断挪到其它node的core上,在鲲鹏920上测试,业务跑在node3(使用全部24core),网卡中断分别在node0和node3,QPS分别是:179000 VS 175000 (此时把中断放到node0或者是和node3最近的node2上差别不大)
如果将业务跑在node0上(全部24core),网卡中断分别在node0和node1上得到的QPS分别是:204000 VS 212000
tpcc 1000仓
测试结果(测试中Hygon 7280分别跑在CentOS7.9和麒麟上, 鲲鹏/intel CPU 跑在AliOS、麒麟是国产OS):
tpcc测试数据,结果为1000仓,tpmC (NewOrders) ,未标注CPU 则为跑满了
| 测试核数 | Intel 8269 2.50G | Intel 8163 2.50G | Hygon 7280 2.1GHz 麒麟 | Hygon 7280 2.1G CentOS 7.9 | 鲲鹏 920-4826 2.6G | 鲲鹏 920-4826 2.6G XDB8.0 |
|---|---|---|---|---|---|---|
| 1物理核 | 12392 | 9902 | 4706 | 7011 | 6619 | 4653 |
| 一对HT | 17892 | 15324 | 8950 | 11778 | 无HT | 无HT |
| 4物理核 | 51525 | 40877 | 19387 380% | 30046 | 23959 | 20101 |
| 8物理核 | 100792 | 81799 | 39664 750% | 60086 | 42368 | 40572 |
| 16物理核 | 160798 抖动 | 140488 CPU抖动 | 75013 1400% | 106419 1300-1550% | 70581 1200% | 79844 |
| 24物理核 | 188051 | 164757 1600-2100% | 100841 1800-2000% | 130815 1600-2100% | 88204 1600% | 115355 |
| 32物理核 | 195292 | 185171 2000-2500% | 116071 1900-2400% | 142746 1800-2400% | 102089 1900% | 143567 |
| 48物理核 | 19969l | 195730 2100-2600% | 128188 2100-2800% | 149782 2000-2700% | 116374 2500% | 206055 4500% |
tpcc并发到一定程度后主要是锁导致性能上不去,所以超多核意义不大。
如果在Hygon 7280 2.1GHz 麒麟上起两个MySQLD实例,每个实例各绑定32物理core,性能刚好翻倍:
测试过程CPU均跑满(未跑满的话会标注出来),IPC跑不起来性能就必然低,超线程虽然总性能好了但是会导致IPC降低(参考前面的公式)。可以看到对本来IPC比较低的场景,启用超线程后一般对性能会提升更大一些。
CPU核数增加到32核后,MySQL社区版性能追平xdb, 此时sysbench使用120线程压性能较好(AMD得240线程压)
32核的时候对比下MySQL 社区版在Hygon7280和Intel 8163下的表现:

三款CPU的性能指标
| 测试项 | AMD EPYC 7H12 2.5G | Hygon 7280 2.1GHz | Intel 8163 CPU @ 2.50GHz |
|---|---|---|---|
| 内存带宽(MiB/s) | 12190.50 | 6206.06 | 7474.45 |
| 内存延时(遍历很大一个数组) | 0.334ms | 0.336ms | 0.429ms |
在lmbench上的测试数据
stream主要用于测试带宽,对应的时延是在带宽跑满情况下的带宽。
lat_mem_rd用来测试操作不同数据大小的时延。总的来说带宽看stream、时延看lat_mem_rd
飞腾2500
用stream测试带宽和latency,可以看到带宽随着numa距离不断减少、对应的latency不断增加,到最近的numa node有10%的损耗,这个损耗和numactl给出的距离完全一致。跨socket访问内存latency是node内的3倍,带宽是三分之一,但是socket1性能和socket0性能完全一致
| 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596 | time for i in $(seq 7 8 128); do echo $i; numactl -C $i -m 0 ./bin/stream -W 5 -N 5 -M 64M; done#numactl -C 7 -m 0 ./bin/stream -W 5 -N 5 -M 64MSTREAM copy latency: 2.84 nanosecondsSTREAM copy bandwidth: 5638.21 MB/secSTREAM scale latency: 2.72 nanosecondsSTREAM scale bandwidth: 5885.97 MB/secSTREAM add latency: 2.26 nanosecondsSTREAM add bandwidth: 10615.13 MB/secSTREAM triad latency: 4.53 nanosecondsSTREAM triad bandwidth: 5297.93 MB/sec#numactl -C 7 -m 1 ./bin/stream -W 5 -N 5 -M 64MSTREAM copy latency: 3.16 nanosecondsSTREAM copy bandwidth: 5058.71 MB/secSTREAM scale latency: 3.15 nanosecondsSTREAM scale bandwidth: 5074.78 MB/secSTREAM add latency: 2.35 nanosecondsSTREAM add bandwidth: 10197.36 MB/secSTREAM triad latency: 5.12 nanosecondsSTREAM triad bandwidth: 4686.37 MB/sec#numactl -C 7 -m 2 ./bin/stream -W 5 -N 5 -M 64MSTREAM copy latency: 3.85 nanosecondsSTREAM copy bandwidth: 4150.98 MB/secSTREAM scale latency: 3.95 nanosecondsSTREAM scale bandwidth: 4054.30 MB/secSTREAM add latency: 2.64 nanosecondsSTREAM add bandwidth: 9100.12 MB/secSTREAM triad latency: 6.39 nanosecondsSTREAM triad bandwidth: 3757.70 MB/sec#numactl -C 7 -m 3 ./bin/stream -W 5 -N 5 -M 64MSTREAM copy latency: 3.69 nanosecondsSTREAM copy bandwidth: 4340.24 MB/secSTREAM scale latency: 3.62 nanosecondsSTREAM scale bandwidth: 4422.18 MB/secSTREAM add latency: 2.47 nanosecondsSTREAM add bandwidth: 9704.82 MB/secSTREAM triad latency: 5.74 nanosecondsSTREAM triad bandwidth: 4177.85 MB/sec[root@101a05001.cloud.a05.am11 /root/lmbench3]#numactl -C 7 -m 7 ./bin/stream -W 5 -N 5 -M 64MSTREAM copy latency: 3.95 nanosecondsSTREAM copy bandwidth: 4051.51 MB/secSTREAM scale latency: 3.94 nanosecondsSTREAM scale bandwidth: 4060.63 MB/secSTREAM add latency: 2.54 nanosecondsSTREAM add bandwidth: 9434.51 MB/secSTREAM triad latency: 6.13 nanosecondsSTREAM triad bandwidth: 3913.36 MB/sec[root@101a05001.cloud.a05.am11 /root/lmbench3]#numactl -C 7 -m 10 ./bin/stream -W 5 -N 5 -M 64MSTREAM copy latency: 8.80 nanosecondsSTREAM copy bandwidth: 1817.78 MB/secSTREAM scale latency: 8.59 nanosecondsSTREAM scale bandwidth: 1861.65 MB/secSTREAM add latency: 5.55 nanosecondsSTREAM add bandwidth: 4320.68 MB/secSTREAM triad latency: 13.94 nanosecondsSTREAM triad bandwidth: 1721.76 MB/sec[root@101a05001.cloud.a05.am11 /root/lmbench3]#numactl -C 7 -m 11 ./bin/stream -W 5 -N 5 -M 64MSTREAM copy latency: 9.27 nanosecondsSTREAM copy bandwidth: 1726.52 MB/secSTREAM scale latency: 9.31 nanosecondsSTREAM scale bandwidth: 1718.10 MB/secSTREAM add latency: 5.65 nanosecondsSTREAM add bandwidth: 4250.89 MB/secSTREAM triad latency: 14.09 nanosecondsSTREAM triad bandwidth: 1703.66 MB/sec[root@101a05001.cloud.a05.am11 /root/lmbench3]#numactl -C 88 -m 11 ./bin/stream -W 5 -N 5 -M 64M //在另外一个socket上测试本numa,和node0性能完全一致STREAM copy latency: 2.93 nanosecondsSTREAM copy bandwidth: 5454.67 MB/secSTREAM scale latency: 2.96 nanosecondsSTREAM scale bandwidth: 5400.03 MB/secSTREAM add latency: 2.28 nanosecondsSTREAM add bandwidth: 10543.42 MB/secSTREAM triad latency: 4.52 nanosecondsSTREAM triad bandwidth: 5308.40 MB/sec[root@101a05001.cloud.a05.am11 /root/lmbench3]#numactl -C 7 -m 15 ./bin/stream -W 5 -N 5 -M 64MSTREAM copy latency: 8.73 nanosecondsSTREAM copy bandwidth: 1831.77 MB/secSTREAM scale latency: 8.81 nanosecondsSTREAM scale bandwidth: 1815.13 MB/secSTREAM add latency: 5.63 nanosecondsSTREAM add bandwidth: 4265.21 MB/secSTREAM triad latency: 13.09 nanosecondsSTREAM triad bandwidth: 1833.68 MB/sec |
Lat_mem_rd 用cpu7访问node0和node15对比结果,随着数据的加大,延时在加大,64M时能有3倍差距,和上面测试一致
下图 第一列 表示读写数据的大小(单位M),第二列表示访问延时(单位纳秒),一般可以看到在L1/L2/L3 cache大小的地方延时会有跳跃,远超过L3大小后,延时就是内存延时了

| 1 | numactl -C 7 -m 0 ./bin/lat_mem_rd -W 5 -N 5 -t 64M //-C 7 cpu 7, -m 0 node0, -W 热身 -t stride |
同样的机型,开关numa的测试结果,关numa 时延、带宽都差了几倍

关闭numa的机器上测试结果随机性很强,这应该是和内存分配在那里有关系,不过如果机器一直保持这个状态反复测试的话,快的core一直快,慢的core一直慢,这是因为物理地址分配有一定的规律,在物理内存没怎么变化的情况下,快的core恰好分到的内存比较近。
同时不同机器状态(内存使用率)测试结果也不一样
鲲鹏920
| 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849 | #for i in $(seq 0 15); do echo core:$i; numactl -N $i -m 7 ./bin/stream -W 5 -N 5 -M 64M; doneSTREAM copy latency: 1.84 nanosecondsSTREAM copy bandwidth: 8700.75 MB/secSTREAM scale latency: 1.86 nanosecondsSTREAM scale bandwidth: 8623.60 MB/secSTREAM add latency: 2.18 nanosecondsSTREAM add bandwidth: 10987.04 MB/secSTREAM triad latency: 3.03 nanosecondsSTREAM triad bandwidth: 7926.87 MB/sec#numactl -C 7 -m 1 ./bin/stream -W 5 -N 5 -M 64MSTREAM copy latency: 2.05 nanosecondsSTREAM copy bandwidth: 7802.45 MB/secSTREAM scale latency: 2.08 nanosecondsSTREAM scale bandwidth: 7681.87 MB/secSTREAM add latency: 2.19 nanosecondsSTREAM add bandwidth: 10954.76 MB/secSTREAM triad latency: 3.17 nanosecondsSTREAM triad bandwidth: 7559.86 MB/sec#numactl -C 7 -m 2 ./bin/stream -W 5 -N 5 -M 64MSTREAM copy latency: 3.51 nanosecondsSTREAM copy bandwidth: 4556.86 MB/secSTREAM scale latency: 3.58 nanosecondsSTREAM scale bandwidth: 4463.66 MB/secSTREAM add latency: 2.71 nanosecondsSTREAM add bandwidth: 8869.79 MB/secSTREAM triad latency: 5.92 nanosecondsSTREAM triad bandwidth: 4057.12 MB/sec#numactl -C 7 -m 3 ./bin/stream -W 5 -N 5 -M 64MSTREAM copy latency: 3.94 nanosecondsSTREAM copy bandwidth: 4064.25 MB/secSTREAM scale latency: 3.82 nanosecondsSTREAM scale bandwidth: 4188.67 MB/secSTREAM add latency: 2.86 nanosecondsSTREAM add bandwidth: 8390.70 MB/secSTREAM triad latency: 4.78 nanosecondsSTREAM triad bandwidth: 5024.25 MB/sec#numactl -C 24 -m 3 ./bin/stream -W 5 -N 5 -M 64MSTREAM copy latency: 4.10 nanosecondsSTREAM copy bandwidth: 3904.63 MB/secSTREAM scale latency: 4.03 nanosecondsSTREAM scale bandwidth: 3969.41 MB/secSTREAM add latency: 3.07 nanosecondsSTREAM add bandwidth: 7816.08 MB/secSTREAM triad latency: 5.06 nanosecondsSTREAM triad bandwidth: 4738.66 MB/sec |
海光7280
可以看到跨numa(一个numa也就是一个socket,等同于跨socket)RT从1.5上升到2.5,这个数据比鲲鹏920要好很多
| 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081 | [root@hygon8 14:32 /root/lmbench-master]#lscpu架构: x86_64CPU 运行模式: 32-bit, 64-bit字节序: Little EndianAddress sizes: 43 bits physical, 48 bits virtualCPU: 128在线 CPU 列表: 0-127每个核的线程数: 2每个座的核数: 32座: 2NUMA 节点: 8厂商 ID: HygonGenuineCPU 系列: 24型号: 1型号名称: Hygon C86 7280 32-core Processor步进: 1CPU MHz: 2194.586BogoMIPS: 3999.63虚拟化: AMD-VL1d 缓存: 2 MiBL1i 缓存: 4 MiBL2 缓存: 32 MiBL3 缓存: 128 MiBNUMA 节点0 CPU: 0-7,64-71NUMA 节点1 CPU: 8-15,72-79NUMA 节点2 CPU: 16-23,80-87NUMA 节点3 CPU: 24-31,88-95NUMA 节点4 CPU: 32-39,96-103NUMA 节点5 CPU: 40-47,104-111NUMA 节点6 CPU: 48-55,112-119NUMA 节点7 CPU: 56-63,120-127//可以看到7号core比15、23、31号core明显要快,就近访问node 0的内存,跨numa node(跨Die)没有内存交织分配[root@hygon8 14:32 /root/lmbench-master]#time for i in $(seq 7 8 64); do echo $i; numactl -C $i -m 0 ./bin/stream -W 5 -N 5 -M 64M; done7STREAM copy latency: 1.38 nanosecondsSTREAM copy bandwidth: 11559.53 MB/secSTREAM scale latency: 1.16 nanosecondsSTREAM scale bandwidth: 13815.87 MB/secSTREAM add latency: 1.40 nanosecondsSTREAM add bandwidth: 17145.85 MB/secSTREAM triad latency: 1.44 nanosecondsSTREAM triad bandwidth: 16637.18 MB/sec15STREAM copy latency: 1.67 nanosecondsSTREAM copy bandwidth: 9591.77 MB/secSTREAM scale latency: 1.56 nanosecondsSTREAM scale bandwidth: 10242.50 MB/secSTREAM add latency: 1.45 nanosecondsSTREAM add bandwidth: 16581.00 MB/secSTREAM triad latency: 2.00 nanosecondsSTREAM triad bandwidth: 12028.83 MB/sec23STREAM copy latency: 1.65 nanosecondsSTREAM copy bandwidth: 9701.49 MB/secSTREAM scale latency: 1.53 nanosecondsSTREAM scale bandwidth: 10427.98 MB/secSTREAM add latency: 1.42 nanosecondsSTREAM add bandwidth: 16846.10 MB/secSTREAM triad latency: 1.97 nanosecondsSTREAM triad bandwidth: 12189.72 MB/sec31STREAM copy latency: 1.64 nanosecondsSTREAM copy bandwidth: 9742.86 MB/secSTREAM scale latency: 1.52 nanosecondsSTREAM scale bandwidth: 10510.80 MB/secSTREAM add latency: 1.45 nanosecondsSTREAM add bandwidth: 16559.86 MB/secSTREAM triad latency: 1.92 nanosecondsSTREAM triad bandwidth: 12490.01 MB/sec39STREAM copy latency: 2.55 nanosecondsSTREAM copy bandwidth: 6286.25 MB/secSTREAM scale latency: 2.51 nanosecondsSTREAM scale bandwidth: 6383.11 MB/secSTREAM add latency: 1.76 nanosecondsSTREAM add bandwidth: 13660.83 MB/secSTREAM triad latency: 3.68 nanosecondsSTREAM triad bandwidth: 6523.02 MB/sec |
如果这种芯片在bios里设置Die interleaving,4块die当成一个numa node吐出来给OS
| 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182 | #lscpu架构: x86_64CPU 运行模式: 32-bit, 64-bit字节序: Little EndianAddress sizes: 43 bits physical, 48 bits virtualCPU: 128在线 CPU 列表: 0-127每个核的线程数: 2每个座的核数: 32座: 2NUMA 节点: 2厂商 ID: HygonGenuineCPU 系列: 24型号: 1型号名称: Hygon C86 7280 32-core Processor步进: 1CPU MHz: 2108.234BogoMIPS: 3999.45虚拟化: AMD-VL1d 缓存: 2 MiBL1i 缓存: 4 MiBL2 缓存: 32 MiBL3 缓存: 128 MiB//注意这里和真实物理架构不一致,bios配置了Die Interleaving Enable//表示每路内多个Die内存交织分配,这样整个一路就是一个大DieNUMA 节点0 CPU: 0-31,64-95NUMA 节点1 CPU: 32-63,96-127//enable die interleaving 后继续streaming测试//最终测试结果表现就是7/15/23/31 core性能一致,因为默认一个numa内内存交织分配//可以看到同一路下的四个die内存交织访问,所以4个node内存延时一样了(被平均),都不如就近快[root@hygon3 16:09 /root/lmbench-master]#time for i in $(seq 7 8 64); do echo $i; numactl -C $i -m 0 ./bin/stream -W 5 -N 5 -M 64M; done7STREAM copy latency: 1.48 nanosecondsSTREAM copy bandwidth: 10782.58 MB/secSTREAM scale latency: 1.20 nanosecondsSTREAM scale bandwidth: 13364.38 MB/secSTREAM add latency: 1.46 nanosecondsSTREAM add bandwidth: 16408.32 MB/secSTREAM triad latency: 1.53 nanosecondsSTREAM triad bandwidth: 15696.00 MB/sec15STREAM copy latency: 1.51 nanosecondsSTREAM copy bandwidth: 10601.25 MB/secSTREAM scale latency: 1.24 nanosecondsSTREAM scale bandwidth: 12855.87 MB/secSTREAM add latency: 1.46 nanosecondsSTREAM add bandwidth: 16382.42 MB/secSTREAM triad latency: 1.53 nanosecondsSTREAM triad bandwidth: 15691.48 MB/sec23STREAM copy latency: 1.50 nanosecondsSTREAM copy bandwidth: 10700.61 MB/secSTREAM scale latency: 1.27 nanosecondsSTREAM scale bandwidth: 12634.63 MB/secSTREAM add latency: 1.47 nanosecondsSTREAM add bandwidth: 16370.67 MB/secSTREAM triad latency: 1.55 nanosecondsSTREAM triad bandwidth: 15455.75 MB/sec31STREAM copy latency: 1.50 nanosecondsSTREAM copy bandwidth: 10637.39 MB/secSTREAM scale latency: 1.25 nanosecondsSTREAM scale bandwidth: 12778.99 MB/secSTREAM add latency: 1.46 nanosecondsSTREAM add bandwidth: 16420.65 MB/secSTREAM triad latency: 1.61 nanosecondsSTREAM triad bandwidth: 14946.80 MB/sec39STREAM copy latency: 2.35 nanosecondsSTREAM copy bandwidth: 6807.09 MB/secSTREAM scale latency: 2.32 nanosecondsSTREAM scale bandwidth: 6906.93 MB/secSTREAM add latency: 1.63 nanosecondsSTREAM add bandwidth: 14729.23 MB/secSTREAM triad latency: 3.36 nanosecondsSTREAM triad bandwidth: 7151.67 MB/sec47STREAM copy latency: 2.31 nanosecondsSTREAM copy bandwidth: 6938.47 MB/sec |
以华为泰山服务器(鲲鹏920芯片)配置为例:
Die Interleaving 控制是否使能DIE交织。使能DIE交织能充分利用系统的DDR带宽,并尽量保证各DDR通道的带宽均衡,提升DDR的利用率
hygon5280测试数据
| 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990 | —–hygon5280测试数据[root@localhost lmbench-master]# for i in $(seq 0 8 24); do echo $i; numactl -C $i -m 0 ./bin/stream -W 5 -N 5 -M 64M; done0STREAM copy latency: 1.22 nanosecondsSTREAM copy bandwidth: 13166.34 MB/secSTREAM scale latency: 1.13 nanosecondsSTREAM scale bandwidth: 14166.95 MB/secSTREAM add latency: 1.15 nanosecondsSTREAM add bandwidth: 20818.63 MB/secSTREAM triad latency: 1.39 nanosecondsSTREAM triad bandwidth: 17211.81 MB/sec8STREAM copy latency: 1.56 nanosecondsSTREAM copy bandwidth: 10273.07 MB/secSTREAM scale latency: 1.50 nanosecondsSTREAM scale bandwidth: 10701.89 MB/secSTREAM add latency: 1.20 nanosecondsSTREAM add bandwidth: 19996.68 MB/secSTREAM triad latency: 1.93 nanosecondsSTREAM triad bandwidth: 12443.70 MB/sec16STREAM copy latency: 2.52 nanosecondsSTREAM copy bandwidth: 6357.71 MB/secSTREAM scale latency: 2.48 nanosecondsSTREAM scale bandwidth: 6454.95 MB/secSTREAM add latency: 1.67 nanosecondsSTREAM add bandwidth: 14362.51 MB/secSTREAM triad latency: 3.65 nanosecondsSTREAM triad bandwidth: 6572.85 MB/sec24STREAM copy latency: 2.44 nanosecondsSTREAM copy bandwidth: 6554.24 MB/secSTREAM scale latency: 2.41 nanosecondsSTREAM scale bandwidth: 6642.80 MB/secSTREAM add latency: 1.44 nanosecondsSTREAM add bandwidth: 16695.82 MB/secSTREAM triad latency: 3.61 nanosecondsSTREAM triad bandwidth: 6639.18 MB/sec[root@localhost lmbench-master]# lscpu架构: x86_64CPU 运行模式: 32-bit, 64-bit字节序: Little EndianAddress sizes: 43 bits physical, 48 bits virtualCPU: 64在线 CPU 列表: 0-63每个核的线程数: 2每个座的核数: 16座: 2NUMA 节点: 4厂商 ID: HygonGenuineCPU 系列: 24型号: 1型号名称: Hygon C86 5280 16-core Processor步进: 1Frequency boost: enabledCPU MHz: 2799.311CPU 最大 MHz: 2500.0000CPU 最小 MHz: 1600.0000BogoMIPS: 4999.36虚拟化: AMD-VL1d 缓存: 1 MiBL1i 缓存: 2 MiBL2 缓存: 16 MiBL3 缓存: 64 MiBNUMA 节点0 CPU: 0-7,32-39NUMA 节点1 CPU: 8-15,40-47NUMA 节点2 CPU: 16-23,48-55NUMA 节点3 CPU: 24-31,56-63Vulnerability Itlb multihit: Not affectedVulnerability L1tf: Not affectedVulnerability Mds: Not affectedVulnerability Meltdown: Not affectedVulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccompVulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitizationVulnerability Spectre v2: Mitigation; Full AMD retpoline, IBPB conditional, STIBP disabled, RSBfillingVulnerability Srbds: Not affectedVulnerability Tsx async abort: Not affected标记: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid amd_dcmaperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacyabm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate sme ssbd sevibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat nptlbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca |
intel 8269CY
| 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374 | lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 104On-line CPU(s) list: 0-103Thread(s) per core: 2Core(s) per socket: 26Socket(s): 2NUMA node(s): 2Vendor ID: GenuineIntelCPU family: 6Model: 85Model name: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHzStepping: 7CPU MHz: 3200.000CPU max MHz: 3800.0000CPU min MHz: 1200.0000BogoMIPS: 4998.89Virtualization: VT-xL1d cache: 32KL1i cache: 32KL2 cache: 1024KL3 cache: 36608KNUMA node0 CPU(s): 0-25,52-77NUMA node1 CPU(s): 26-51,78-103[root@numaopen.cloud.et93 /home/ren/lmbench3]#time for i in $(seq 0 8 51); do echo $i; numactl -C $i -m 0 ./bin/stream -W 5 -N 5 -M 64M; done0STREAM copy latency: 1.15 nanosecondsSTREAM copy bandwidth: 13941.80 MB/secSTREAM scale latency: 1.16 nanosecondsSTREAM scale bandwidth: 13799.89 MB/secSTREAM add latency: 1.31 nanosecondsSTREAM add bandwidth: 18318.23 MB/secSTREAM triad latency: 1.56 nanosecondsSTREAM triad bandwidth: 15356.72 MB/sec16STREAM copy latency: 1.12 nanosecondsSTREAM copy bandwidth: 14293.68 MB/secSTREAM scale latency: 1.13 nanosecondsSTREAM scale bandwidth: 14162.47 MB/secSTREAM add latency: 1.31 nanosecondsSTREAM add bandwidth: 18293.27 MB/secSTREAM triad latency: 1.53 nanosecondsSTREAM triad bandwidth: 15692.47 MB/sec32STREAM copy latency: 1.52 nanosecondsSTREAM copy bandwidth: 10551.71 MB/secSTREAM scale latency: 1.52 nanosecondsSTREAM scale bandwidth: 10508.33 MB/secSTREAM add latency: 1.38 nanosecondsSTREAM add bandwidth: 17363.22 MB/secSTREAM triad latency: 2.00 nanosecondsSTREAM triad bandwidth: 12024.52 MB/sec40STREAM copy latency: 1.49 nanosecondsSTREAM copy bandwidth: 10758.50 MB/secSTREAM scale latency: 1.50 nanosecondsSTREAM scale bandwidth: 10680.17 MB/secSTREAM add latency: 1.34 nanosecondsSTREAM add bandwidth: 17948.34 MB/secSTREAM triad latency: 1.98 nanosecondsSTREAM triad bandwidth: 12133.22 MB/sec48STREAM copy latency: 1.49 nanosecondsSTREAM copy bandwidth: 10736.56 MB/secSTREAM scale latency: 1.50 nanosecondsSTREAM scale bandwidth: 10692.93 MB/secSTREAM add latency: 1.34 nanosecondsSTREAM add bandwidth: 17902.85 MB/secSTREAM triad latency: 1.96 nanosecondsSTREAM triad bandwidth: 12239.44 MB/sec |
Intel(R) Xeon(R) CPU E5-2682 v4
| 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364 | #time for i in $(seq 0 8 51); do echo $i; numactl -C $i -m 0 ./bin/stream -W 5 -N 5 -M 64M; done0STREAM copy latency: 1.59 nanosecondsSTREAM copy bandwidth: 10092.31 MB/secSTREAM scale latency: 1.57 nanosecondsSTREAM scale bandwidth: 10169.16 MB/secSTREAM add latency: 1.31 nanosecondsSTREAM add bandwidth: 18360.83 MB/secSTREAM triad latency: 2.28 nanosecondsSTREAM triad bandwidth: 10503.81 MB/sec8STREAM copy latency: 1.55 nanosecondsSTREAM copy bandwidth: 10312.14 MB/secSTREAM scale latency: 1.56 nanosecondsSTREAM scale bandwidth: 10283.70 MB/secSTREAM add latency: 1.30 nanosecondsSTREAM add bandwidth: 18416.26 MB/secSTREAM triad latency: 2.23 nanosecondsSTREAM triad bandwidth: 10777.08 MB/sec16STREAM copy latency: 2.02 nanosecondsSTREAM copy bandwidth: 7914.25 MB/secSTREAM scale latency: 2.02 nanosecondsSTREAM scale bandwidth: 7919.85 MB/secSTREAM add latency: 1.39 nanosecondsSTREAM add bandwidth: 17276.06 MB/secSTREAM triad latency: 2.92 nanosecondsSTREAM triad bandwidth: 8231.18 MB/sec24STREAM copy latency: 1.99 nanosecondsSTREAM copy bandwidth: 8032.18 MB/secSTREAM scale latency: 1.98 nanosecondsSTREAM scale bandwidth: 8061.12 MB/secSTREAM add latency: 1.39 nanosecondsSTREAM add bandwidth: 17313.94 MB/secSTREAM triad latency: 2.88 nanosecondsSTREAM triad bandwidth: 8318.93 MB/sec#lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 64On-line CPU(s) list: 0-63Thread(s) per core: 2Core(s) per socket: 16Socket(s): 2NUMA node(s): 2Vendor ID: GenuineIntelCPU family: 6Model: 79Model name: Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHzStepping: 1CPU MHz: 2500.000CPU max MHz: 3000.0000CPU min MHz: 1200.0000BogoMIPS: 5000.06Virtualization: VT-xL1d cache: 32KL1i cache: 32KL2 cache: 256KL3 cache: 40960KNUMA node0 CPU(s): 0-15,32-47NUMA node1 CPU(s): 16-31,48-63 |
AMD EPYC 7T83
| 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170171172173174175176177178179180181182183184185186187188189190191192193194195196197198199200201202203204205206207208209210211212213214215216217218219220221222223224225226227228229230231232233234235236237238239240241242243244245246247248249250251252253254255256257258259260261262263264265266267268269270271272273274275276277278279280281282283284285286287288289 | #time for i in $(seq 0 8 255); do echo $i; numactl -C $i -m 0 ./bin/stream -W 5 -N 5 -M 64M; done0STREAM copy latency: 0.49 nanosecondsSTREAM copy bandwidth: 32561.30 MB/secSTREAM scale latency: 0.49 nanosecondsSTREAM scale bandwidth: 32620.66 MB/secSTREAM add latency: 0.87 nanosecondsSTREAM add bandwidth: 27575.20 MB/secSTREAM triad latency: 0.70 nanosecondsSTREAM triad bandwidth: 34397.15 MB/sec8STREAM copy latency: 0.52 nanosecondsSTREAM copy bandwidth: 30764.47 MB/secSTREAM scale latency: 0.53 nanosecondsSTREAM scale bandwidth: 30056.59 MB/secSTREAM add latency: 0.87 nanosecondsSTREAM add bandwidth: 27575.20 MB/secSTREAM triad latency: 0.69 nanosecondsSTREAM triad bandwidth: 34789.45 MB/sec16STREAM copy latency: 0.53 nanosecondsSTREAM copy bandwidth: 30173.15 MB/secSTREAM scale latency: 0.54 nanosecondsSTREAM scale bandwidth: 29895.91 MB/secSTREAM add latency: 0.87 nanosecondsSTREAM add bandwidth: 27496.11 MB/secSTREAM triad latency: 0.70 nanosecondsSTREAM triad bandwidth: 34128.93 MB/sec24STREAM copy latency: 0.78 nanosecondsSTREAM copy bandwidth: 20417.69 MB/secSTREAM scale latency: 0.51 nanosecondsSTREAM scale bandwidth: 31354.70 MB/secSTREAM add latency: 0.87 nanosecondsSTREAM add bandwidth: 27548.79 MB/secSTREAM triad latency: 0.69 nanosecondsSTREAM triad bandwidth: 34589.22 MB/sec32STREAM copy latency: 0.60 nanosecondsSTREAM copy bandwidth: 26862.34 MB/secSTREAM scale latency: 0.58 nanosecondsSTREAM scale bandwidth: 27376.00 MB/secSTREAM add latency: 0.87 nanosecondsSTREAM add bandwidth: 27518.66 MB/secSTREAM triad latency: 0.78 nanosecondsSTREAM triad bandwidth: 30779.17 MB/sec40STREAM copy latency: 0.59 nanosecondsSTREAM copy bandwidth: 27230.21 MB/secSTREAM scale latency: 0.59 nanosecondsSTREAM scale bandwidth: 27284.18 MB/secSTREAM add latency: 0.87 nanosecondsSTREAM add bandwidth: 27503.63 MB/secSTREAM triad latency: 0.77 nanosecondsSTREAM triad bandwidth: 31242.48 MB/sec48STREAM copy latency: 0.59 nanosecondsSTREAM copy bandwidth: 27102.37 MB/secSTREAM scale latency: 0.59 nanosecondsSTREAM scale bandwidth: 27164.08 MB/secSTREAM add latency: 0.87 nanosecondsSTREAM add bandwidth: 27503.63 MB/secSTREAM triad latency: 0.76 nanosecondsSTREAM triad bandwidth: 31422.90 MB/sec56STREAM copy latency: 0.92 nanosecondsSTREAM copy bandwidth: 17453.54 MB/secSTREAM scale latency: 0.59 nanosecondsSTREAM scale bandwidth: 27267.55 MB/secSTREAM add latency: 0.87 nanosecondsSTREAM add bandwidth: 27488.61 MB/secSTREAM triad latency: 0.77 nanosecondsSTREAM triad bandwidth: 31169.92 MB/sec64STREAM copy latency: 0.88 nanosecondsSTREAM copy bandwidth: 18231.15 MB/secSTREAM scale latency: 0.84 nanosecondsSTREAM scale bandwidth: 18976.06 MB/secSTREAM add latency: 0.91 nanosecondsSTREAM add bandwidth: 26413.87 MB/secSTREAM triad latency: 1.08 nanosecondsSTREAM triad bandwidth: 22310.12 MB/sec72STREAM copy latency: 0.86 nanosecondsSTREAM copy bandwidth: 18552.45 MB/secSTREAM scale latency: 0.84 nanosecondsSTREAM scale bandwidth: 19113.88 MB/secSTREAM add latency: 0.91 nanosecondsSTREAM add bandwidth: 26375.81 MB/secSTREAM triad latency: 1.08 nanosecondsSTREAM triad bandwidth: 22151.79 MB/sec80STREAM copy latency: 0.89 nanosecondsSTREAM copy bandwidth: 18037.59 MB/secSTREAM scale latency: 0.87 nanosecondsSTREAM scale bandwidth: 18398.59 MB/secSTREAM add latency: 0.92 nanosecondsSTREAM add bandwidth: 26142.91 MB/secSTREAM triad latency: 1.08 nanosecondsSTREAM triad bandwidth: 22133.53 MB/sec88STREAM copy latency: 0.93 nanosecondsSTREAM copy bandwidth: 17119.60 MB/secSTREAM scale latency: 0.94 nanosecondsSTREAM scale bandwidth: 17030.54 MB/secSTREAM add latency: 0.92 nanosecondsSTREAM add bandwidth: 26146.30 MB/secSTREAM triad latency: 1.08 nanosecondsSTREAM triad bandwidth: 22159.10 MB/sec96STREAM copy latency: 1.39 nanosecondsSTREAM copy bandwidth: 11512.93 MB/secSTREAM scale latency: 0.87 nanosecondsSTREAM scale bandwidth: 18406.16 MB/secSTREAM add latency: 0.92 nanosecondsSTREAM add bandwidth: 25991.03 MB/secSTREAM triad latency: 1.09 nanosecondsSTREAM triad bandwidth: 22078.91 MB/sec104STREAM copy latency: 0.86 nanosecondsSTREAM copy bandwidth: 18546.04 MB/secSTREAM scale latency: 1.39 nanosecondsSTREAM scale bandwidth: 11518.85 MB/secSTREAM add latency: 0.91 nanosecondsSTREAM add bandwidth: 26300.01 MB/secSTREAM triad latency: 1.06 nanosecondsSTREAM triad bandwidth: 22599.38 MB/sec112STREAM copy latency: 0.88 nanosecondsSTREAM copy bandwidth: 18253.46 MB/secSTREAM scale latency: 0.85 nanosecondsSTREAM scale bandwidth: 18758.59 MB/secSTREAM add latency: 0.91 nanosecondsSTREAM add bandwidth: 26413.87 MB/secSTREAM triad latency: 1.06 nanosecondsSTREAM triad bandwidth: 22648.95 MB/sec120STREAM copy latency: 0.86 nanosecondsSTREAM copy bandwidth: 18607.75 MB/secSTREAM scale latency: 0.84 nanosecondsSTREAM scale bandwidth: 18957.30 MB/secSTREAM add latency: 0.91 nanosecondsSTREAM add bandwidth: 26427.74 MB/secSTREAM triad latency: 1.08 nanosecondsSTREAM triad bandwidth: 22313.83 MB/sec128STREAM copy latency: 0.82 nanosecondsSTREAM copy bandwidth: 19432.13 MB/secSTREAM scale latency: 0.87 nanosecondsSTREAM scale bandwidth: 18421.31 MB/secSTREAM add latency: 0.98 nanosecondsSTREAM add bandwidth: 24546.03 MB/secSTREAM triad latency: 1.06 nanosecondsSTREAM triad bandwidth: 22702.59 MB/sec136STREAM copy latency: 0.74 nanosecondsSTREAM copy bandwidth: 21568.01 MB/secSTREAM scale latency: 0.74 nanosecondsSTREAM scale bandwidth: 21668.99 MB/secSTREAM add latency: 0.90 nanosecondsSTREAM add bandwidth: 26697.59 MB/secSTREAM triad latency: 0.91 nanosecondsSTREAM triad bandwidth: 26320.64 MB/sec144STREAM copy latency: 0.79 nanosecondsSTREAM copy bandwidth: 20268.45 MB/secSTREAM scale latency: 0.66 nanosecondsSTREAM scale bandwidth: 24279.61 MB/secSTREAM add latency: 0.89 nanosecondsSTREAM add bandwidth: 26822.08 MB/secSTREAM triad latency: 0.84 nanosecondsSTREAM triad bandwidth: 28540.76 MB/sec152STREAM copy latency: 0.85 nanosecondsSTREAM copy bandwidth: 18903.90 MB/secSTREAM scale latency: 0.56 nanosecondsSTREAM scale bandwidth: 28734.25 MB/secSTREAM add latency: 0.88 nanosecondsSTREAM add bandwidth: 27335.58 MB/secSTREAM triad latency: 0.75 nanosecondsSTREAM triad bandwidth: 31911.01 MB/sec160STREAM copy latency: 0.64 nanosecondsSTREAM copy bandwidth: 25068.68 MB/secSTREAM scale latency: 0.63 nanosecondsSTREAM scale bandwidth: 25550.68 MB/secSTREAM add latency: 0.88 nanosecondsSTREAM add bandwidth: 27313.33 MB/secSTREAM triad latency: 0.82 nanosecondsSTREAM triad bandwidth: 29416.50 MB/sec168STREAM copy latency: 0.61 nanosecondsSTREAM copy bandwidth: 26232.33 MB/secSTREAM scale latency: 0.60 nanosecondsSTREAM scale bandwidth: 26717.96 MB/secSTREAM add latency: 0.88 nanosecondsSTREAM add bandwidth: 27398.82 MB/secSTREAM triad latency: 0.79 nanosecondsSTREAM triad bandwidth: 30411.86 MB/sec176STREAM copy latency: 0.58 nanosecondsSTREAM copy bandwidth: 27380.19 MB/secSTREAM scale latency: 0.58 nanosecondsSTREAM scale bandwidth: 27740.96 MB/secSTREAM add latency: 0.94 nanosecondsSTREAM add bandwidth: 25666.31 MB/secSTREAM triad latency: 0.77 nanosecondsSTREAM triad bandwidth: 31150.63 MB/sec184STREAM copy latency: 0.90 nanosecondsSTREAM copy bandwidth: 17730.21 MB/secSTREAM scale latency: 0.57 nanosecondsSTREAM scale bandwidth: 27918.40 MB/secSTREAM add latency: 0.87 nanosecondsSTREAM add bandwidth: 27458.61 MB/secSTREAM triad latency: 0.76 nanosecondsSTREAM triad bandwidth: 31457.27 MB/sec192STREAM copy latency: 0.91 nanosecondsSTREAM copy bandwidth: 17558.57 MB/secSTREAM scale latency: 0.88 nanosecondsSTREAM scale bandwidth: 18115.49 MB/secSTREAM add latency: 0.92 nanosecondsSTREAM add bandwidth: 26031.36 MB/secSTREAM triad latency: 1.12 nanosecondsSTREAM triad bandwidth: 21443.95 MB/sec200STREAM copy latency: 1.34 nanosecondsSTREAM copy bandwidth: 11911.40 MB/secSTREAM scale latency: 0.85 nanosecondsSTREAM scale bandwidth: 18893.26 MB/secSTREAM add latency: 0.91 nanosecondsSTREAM add bandwidth: 26306.88 MB/secSTREAM triad latency: 1.09 nanosecondsSTREAM triad bandwidth: 22013.73 MB/sec208STREAM copy latency: 1.36 nanosecondsSTREAM copy bandwidth: 11724.12 MB/secSTREAM scale latency: 0.86 nanosecondsSTREAM scale bandwidth: 18631.00 MB/secSTREAM add latency: 0.92 nanosecondsSTREAM add bandwidth: 26166.69 MB/secSTREAM triad latency: 1.10 nanosecondsSTREAM triad bandwidth: 21763.86 MB/sec216STREAM copy latency: 0.88 nanosecondsSTREAM copy bandwidth: 18270.85 MB/secSTREAM scale latency: 0.85 nanosecondsSTREAM scale bandwidth: 18848.15 MB/secSTREAM add latency: 0.92 nanosecondsSTREAM add bandwidth: 26176.90 MB/secSTREAM triad latency: 1.10 nanosecondsSTREAM triad bandwidth: 21799.20 MB/sec224STREAM copy latency: 0.89 nanosecondsSTREAM copy bandwidth: 18047.29 MB/secSTREAM scale latency: 0.86 nanosecondsSTREAM scale bandwidth: 18677.66 MB/secSTREAM add latency: 0.92 nanosecondsSTREAM add bandwidth: 26112.39 MB/secSTREAM triad latency: 1.09 nanosecondsSTREAM triad bandwidth: 21966.89 MB/sec232STREAM copy latency: 1.35 nanosecondsSTREAM copy bandwidth: 11818.58 MB/secSTREAM scale latency: 0.82 nanosecondsSTREAM scale bandwidth: 19568.11 MB/secSTREAM add latency: 0.91 nanosecondsSTREAM add bandwidth: 26469.44 MB/secSTREAM triad latency: 1.06 nanosecondsSTREAM triad bandwidth: 22702.59 MB/sec240STREAM copy latency: 0.87 nanosecondsSTREAM copy bandwidth: 18325.74 MB/secSTREAM scale latency: 0.83 nanosecondsSTREAM scale bandwidth: 19331.37 MB/secSTREAM add latency: 0.91 nanosecondsSTREAM add bandwidth: 26455.52 MB/secSTREAM triad latency: 1.06 nanosecondsSTREAM triad bandwidth: 22580.37 MB/sec248STREAM copy latency: 0.87 nanosecondsSTREAM copy bandwidth: 18418.79 MB/secSTREAM scale latency: 0.84 nanosecondsSTREAM scale bandwidth: 19019.09 MB/secSTREAM add latency: 0.91 nanosecondsSTREAM add bandwidth: 26483.37 MB/secSTREAM triad latency: 1.08 nanosecondsSTREAM triad bandwidth: 22148.13 MB/sec |
stream对比数据
总结下几个CPU用stream测试访问内存的RT以及抖动和带宽对比数据,重点关注带宽,这个测试中时延不重要
| 最小RT | 最大RT | 最大copy bandwidth | 最小copy bandwidth | |
|---|---|---|---|---|
| 申威3231(2numa node) | 7.09 | 8.75 | 2256.59 MB/sec | 1827.88 MB/sec |
| 飞腾2500(16 numa node) | 2.84 | 10.34 | 5638.21 MB/sec | 1546.68 MB/sec |
| 鲲鹏920(4 numa node) | 1.84 | 3.87 | 8700.75 MB/sec | 4131.81 MB/sec |
| 海光7280(8 numa node) | 1.38 | 2.58 | 11591.48 MB/sec | 6206.99 MB/sec |
| 海光5280(4 numa node) | 1.22 | 2.52 | 13166.34 MB/sec | 6357.71 MB/sec |
| Intel8269CY(2 numa node) | 1.12 | 1.52 | 14293.68 MB/sec | 10551.71 MB/sec |
| Intel E5-2682(2 numa node) | 1.58 | 2.02 | 10092.31 MB/sec | 7914.25 MB/sec |
| AMD EPYC 7T83(4 numa node) | 0.49 | 1.39 | 32561.30 MB/sec | 11512.93 MB/sec |
| Y | 1.83 | 3.48 | 8764.72 MB/sec | 4593.25 MB/sec |
从以上数据可以看出这5款CPU性能一款比一款好,飞腾2500慢的core上延时快到intel 8269的10倍了,平均延时5倍以上了。延时数据基本和单核上测试sysbench TPS一致。性能差不多就是:常数*主频/RT
lat_mem_rd对比数据
用不同的node上的core 跑lat_mem_rd测试访问node0内存的RT,只取最大64M的时延,时延和node距离完全一致
| RT变化 | |
|---|---|
| 飞腾2500(16 numa node) | core:0 149.976 core:8 168.805 core:16 191.415 core:24 178.283 core:32 170.814 core:40 185.699 core:48 212.281 core:56 202.479 core:64 426.176 core:72 444.367 core:80 465.894 core:88 452.245 core:96 448.352 core:104 460.603 core:112 485.989 core:120 490.402 |
| 鲲鹏920(4 numa node) | core:0 117.323 core:24 135.337 core:48 197.782 core:72 219.416 |
| 海光7280(8 numa node) | numa0 106.839 numa1 168.583 numa2 163.925 numa3 163.690 numa4 289.628 numa5 288.632 numa6 236.615 numa7 291.880 分割行 enabled die interleaving core:0 153.005 core:16 152.458 core:32 272.057 core:48 269.441 |
| 海光5280(4 numa node) | core:0 102.574 core:8 160.989 core:16 286.850 core:24 231.197 |
| 海光7260(1 numa node) | core:0 265 |
| Intel 8269CY(2 numa node) | core:0 69.792 core:26 93.107 |
| 申威3231(2numa node) | core:0 215.146 core:32 282.443 |
| AMD EPYC 7T83(4 numa node) | core:0 71.656 core:32 80.129 core:64 131.334 core:96 129.563 |
| Y7(2Die,2node,1socket) | core:8 42.395 core:40 36.434 core:104 105.745 core:88 124.384 core:24 62.979 133ns 205ns (待测) |
测试命令:
| 1 | for i in $(seq 0 8 127); do echo core:$i; numactl -C $i -m 0 ./bin/lat_mem_rd -W 5 -N 5 -t 64M; done >lat.log 2>&1 |
测试结果和numactl -H 看到的node distance完全一致,芯片厂家应该就是这样测试然后把这个延迟当做距离写进去了
AMD EPYC 7T83(4 numa node)的时延相对抖动有点大,这和架构多个小Die合并成一块CPU有关
| 12345678910111213 | #grep -E “core|64.00000” lat.logcore:064.00000 71.656core:3264.00000 80.129core:6464.00000 131.334core:8864.00000 136.774core:9664.00000 129.563core:12064.00000 140.151 |
AMD EPYC 7T83(4 numa node)比Intel 8269时延要大,但是带宽也高很多
龙芯测试数据
3A5000为龙芯,执行的命令为./lat_mem_rd 128M 4096,其中 4096 参数为跳步大小。其基本原理是,通过按 给定间隔去循环读一定大小的内存区域,测量每个读平均的时间。如果区域大小小于 L1 Cache 大 小,时间应该接近 L1 的访问延迟;如果大于 L1 小于 L2,则接近 L2 访问延迟;依此类推。图中横坐 标为访问的字节数,纵坐标为访存的拍数(cycles)。

基于跳步访问的 3A5000 和 Zen1、Skylake 各级延迟的比较(cycles)

下图给出了 LMbench 测试得到的访存操作的并发性,执行的命令为./par_mem。访存操作的并 发性是各级 Cache 和内存所支持并发访问的能力。在 LMbench 中,访存操作并发性的测试是设计一 个链表,不断地遍历访问下一个链表中的元素,链表所跳的距离和需要测量的 Cache 容量相关,在 一段时间能并发的发起对链表的追逐操作,也就是同时很多链表在遍历,如果发现这一段时间内 能同时完成 N 个链表的追逐操作,就认为访存的并发操作是 N。

下图列出了三款处理器的功能部件操作延迟数据,使用的命令是./lat_ops。

龙芯stream数据
LMbench 包含了 STREAM 带宽测试工具,可以用来测试可持续的内存访问带宽情况。图表12.25列 出了三款处理器的 STREAM 带宽数据,其中 STREAM 数组大小设置为 1 亿个元素,采用 OpenMP 版本 同时运行四个线程来测试满载带宽;相应测试平台均为 CPU 的两个内存控制器各接一根内存条, 3A5000 和 Zen1 用 DDR4 3200 内存条,Skylake 用 DDR4 2400 内存条(它最高只支持这个规格)。

从数据可以看到,虽然硬件上 3A5000 和 Zen1 都实现了 DDR4 3200,但 3A5000 的实测可持续带宽 还是有一定差距。用户程序看到的内存带宽不仅仅和内存的物理频率有关系,也和处理器内部的 各种访存队列、内存控制器的调度策略、预取器和内存时序参数设置等相关,需要进行更多分析 来定位具体的瓶颈点。像 STREAM 这样的软件测试工具,能够更好地反映某个子系统的综合能力, 因而被广泛采用。
对比结论
- AMD单核跑分数据比较好
- MySQL 查询场景下Intel的性能好很多
- xdb比社区版性能要好
- MySQL8.0比5.7在多核锁竞争场景下性能要好
- intel最好,AMD接近Intel,海光差的比较远但是又比鲲鹏好很多,飞腾最差,尤其是跨socket简直是灾难
- 麒麟OS性能也比CentOS略差一些
- 从perf指标来看 鲲鹏920的L1d命中率高于8163是因为鲲鹏L1 size大;L2命中率低于8163,同样是因为鲲鹏 L2 size小;同样L1i 鲲鹏也大于8163,但是实际跑起来L1i Miss Rate更高,这说明 ARM对 L1d 使用效率低
整体来说AMD用领先了一代的工艺(7nm VS 14nm),在MySQL查询场景中终于可以接近Intel了,但是海光、鲲鹏、飞腾还是不给力。
附表
鲲鹏920 和 8163 在 MySQL 场景下的 perf 指标对比
| 整体对比 | |||
|---|---|---|---|
| 指标 | X86 | ARM | 增加幅度 |
| IPC | 0.4979 | 0.495 | -0.6% |
| Branchs | 237606414772 | 415979894985 | 75.1% |
| Branch-misses | 8104247620 | 28983836845 | 257.6% |
| Branch-missed rate | 0.034 | 0.070 | 104.3% |
| 内存读带宽(GB/S) | 25.0 | 25.0 | -0.2% |
| 内存写带宽(GB/S) | 24.6 | 67.8 | 175.5% |
| 内存读写带宽(GB/S) | 49.7 | 92.8 | 86.8% |
| UNALIGNED_ACCESS | 1329146645 | 13686011901 | 929.7% |
| L1d_MISS_RATIO | 0.06055 | 0.04281 | -29.3% |
| L1d_MISS_RATE | 0.01645 | 0.01711 | 4.0% |
| L2_MISS_RATIO | 0.34824 | 0.47162 | 35.4% |
| L2_MISS_RATE | 0.00577 | 0.03493 | 504.8% |
| L1_ITLB_MISS_RATE | 0.0028 | 0.005 | 78.6% |
| L1_DTLB_MISS_RATE | 0.0025 | 0.0102 | 308.0% |
| context-switchs | 8407195 | 11614981 | 38.2% |
| Pagefault | 228371 | 741189 | 224.6% |
参考资料
CPU的制造和概念
CPU 性能和Cache Line
Perf IPC以及CPU性能
Intel、海光、鲲鹏920、飞腾2500 CPU性能对比
飞腾ARM芯片(FT2500)的性能测试的性能测试/)
十年后数据库还是不敢拥抱NUMA?
一次海光物理机资源竞争压测的记录
Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的
lmbench测试要考虑cache等
comment:
Intel 8163 IPC是0.67,和在PostgreSQL下测得数据基本一致。Oracle可以达到更高的IPC。从8163的perf结果中,看不出来访存在总周期中的占比。可以添加几个cycle_activity.cycles_l1d_miss、cycle_activity.stalls_mem_any,看看访存耗用的周期占比。
作者|plantegg
本文来自博客园,作者:古道轻风,转载请注明原文链接:https://www.cnblogs.com/88223100/p/Large-PK-of-different-CPU-performance.html