现象
最近收到一个慢sql工单,慢sql大概是这样:“select xxx from tabel where type = 1”。
咦,type字段明明有索引啊,为啥是慢sql呢?
原因
通过执行explain,发现实际上数据库执行了全表扫描,从而被系统判定为慢sql。这时有一定开发经验的同事会说:“字段区分度不够,这种字段作单独索引是没有意义的”。那么为什么会产生索引失效这种情况呢?索引失效都有哪些情况呢?
索引失效概括
下面总结了若干索引失效的情况:
不满足最左匹配
假如表中有个组合索引,idx_start_org_code_start_province_id_trans_type,它的索引顺序如下:
start_org_code,
start_province_id,
trans_type

当我们从第二个索引字段开始查询时就不会走索引:
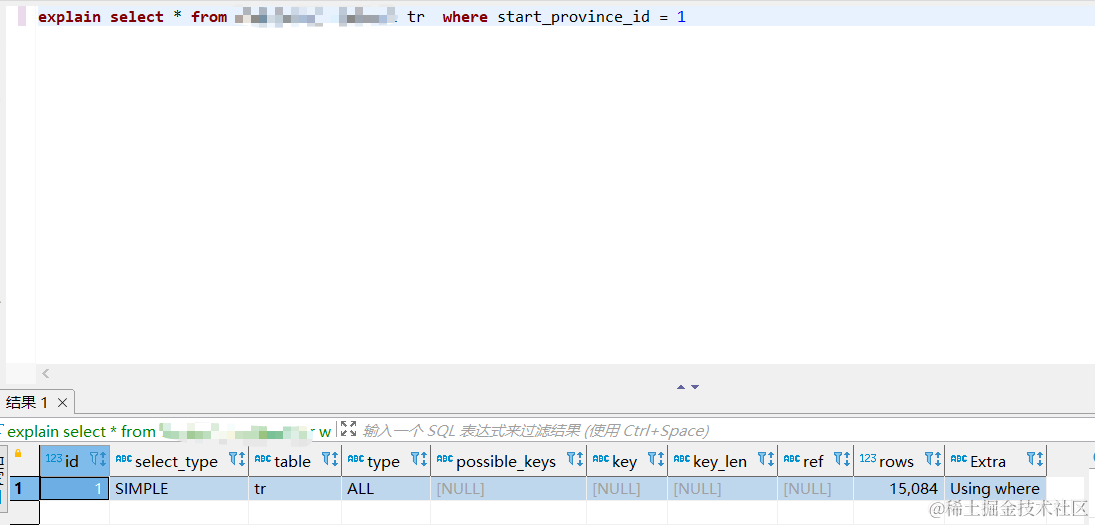
因为索引是BTree结构的,不能跳过第一个索引直接走第二个索引
索引列上有计算
当我们用主键做条件时,走索引了:

而当id列上面有计算,比如:

可以看到走了全表扫描
索引列上有函数
有时候我们在某条sql语句的查询条件中,需要使用函数,比如:截取某个字段的长度:

你有没有发现,在使用该函数之后,该sql语句竟然走了全表扫描,索引失效了
字段类型不同
在sql语句中因为字段类型不同,而导致索引失效的问题,很容易遇到,可能是我们日常工作中最容易忽略的问题。
到底怎么回事呢?
我们看下表里的start_org_code字段,它是varchar字符类型的
在sql语句查询数据时,查询条件我们可以写成这样:

从上图中看到,该字段走了索引
但如果在写sql时,不小心把引号丢了:

咦,该sql语句居然变成全表扫描了,为什么索引失效了?
答:因为这个索引列是varchar类型,而传参的类型是int,mysql在比较两种不同类型的字段时会尝试把这两个转化为同一种类型,再进行比较。这样就可以理解为在字段上加了函数,根据上面分析,索引列加了函数会索引失效。
比较有意思的是,如果int类型的id字段,在查询时加了引号条件,却还可以走索引:

从图中看出该sql语句确实走了索引。int类型的参数,不管在查询时加没加引号,都能走索引。
这还科学吗?有没有王法了?
答:MySQL发现如果是int类型字段作为查询条件时,它会自动将该字段的传参进行隐式转换,把字符串转换成int类型。
MySQL会把上面列子中的字符串12348,转换成数字12348,所以仍然能走索引。
事实上,索引列上对字段做任何操作都会导致索引失效,因为mysq认为任何计算或者函数都会改变索引的实际效果,如果继续使用索引可能会造成结果不准确。
like左边包含%
这个相信有点编程经验的同学都知道,这里就不举例说明了。但是为什么索引会失效呢?
答:其实很好理解,索引就像字典中的目录。一般目录是按字母或者拼音从小到大,从左到右排序,是有顺序的。
我们在查目录时,通常会先从左边第一个字母进行匹对,如果相同,再匹对左边第二个字母,如果再相同匹对其他的字母,以此类推。
通过这种方式我们能快速锁定一个具体的目录,或者缩小目录的范围。
但如果你硬要跟目录的设计反着来,先从字典目录右边匹配第一个字母,这画面你可以自行脑补一下,你眼中可能只剩下绝望了,哈哈
列对比
假如我们现在有这样一个需求:过滤出表中某两列值相同的记录。例如:

索引失效了吧?惊不惊喜?
答:表里create_time和update_time都建了索引,单独查询某一字段时都会走索引。但如果把两个单独建了索引的列,用来做列对比时索引会失效。这其实和在索引列上加函数一个原理,MySQL认为索引无法满足需求。
or和in和exist和not in和not exist
这几个有异曲同工之处,就放一起说了。这里就不像上面几种情况100%不走索引了,而是有时候会走索引,有时候不走索引。到底走不走?成本计算说了算。
成本计算
查询优化器是 MySQL 的核心子系统之一,成本计算又是查询优化器的核心逻辑。
全表扫描成本作为参照物,用于和表的其它访问方式的成本做对比。任何一种访问方式,只要成本超过了全表扫描成本,就不会被使用。
基于全表扫描成本的重要地位,要讲清楚 MySQL 的成本计算逻辑,从全表扫描成本计算开始是个不错的选择。
全表扫描成本计算定义
我们先来看一下Mysql源码里成本计算的定义:
class Cost_estimate { private: // cost of I/O operations double io_cost; // cost of CPU operations double cpu_cost; // cost of remote operations double import_cost; // memory used (bytes) double mem_cost; ......}从上面代码可以看到,MySQL 成本计算模型定义了四种成本:
- IO 成本:从磁盘或内存读取数据页的成本。
- CPU 成本:访问记录需要消耗的 CPU 成本。
- 导入成本:这一项一直没被使用,先忽略。
- 内存成本:这一项指的是占用内存字节数,计算 MRR(Multi Range Read)方式读取数据的成本时才会用到,也先忽略。
全表扫描的成本就只剩 IO 成本、CPU 成本这两项了
计算成本
我们先从整体计算公式开始,然后逐步拆解。
全表扫描成本 =io_cost+ 1.1 +cpu_cost+ 1。
io_cost 后面的1.1是硬编码直接加到 IO 成本上的;cpu_cost 后面的1也是硬编码的,直接加到 CPU 成本上。代码里长这样:
int test_quick_select(...) { ...... double scan_time = cost_model->row_evaluate_cost(static_cast(records)) + 1 /* cpu_cost 后面的 + 1 */; Cost_estimate cost_est = table->file->table_scan_cost(); // io_cost 后面的 + 1.1 cost_est.add_io(1.1); ......}关于这两个硬编码的值,代码里没有注释为什么要加,不过它们是个固定值,不影响我们理解成本计算逻辑,先忽略它们。
io_cost =cluster_page_count*avg_single_page_cost。
cluster_page_count 是主键索引数据页数量,从表的统计信息中得到,在统计信息小节会介绍。
avg_single_page_cost 是读取一个数据页的平均成本,通过计算得到,公式如下:
avg_single_page_cost =pages_in_memory_percent 0.25 +pages_on_disk_percent 1.0**。
pages_in_memory_percent 是主键索引已经加载到 Buffer Pool中的叶结点占所有叶结点的比例,用小数表示(取值范围 0.0 ~ 1.0),例如:80% 表示为 0.8。数据页在内存中的比例小节会介绍具体计算逻辑。
pages_on_disk_percent 是主键索引在磁盘文件中的叶结点占所有叶结点的比例,通过1 – pages_in_memory_percent计算得到。
0.25是成本常数 memory_block_read_cost的默认值,表示从 Buffer Pool 中的一个数据页读取数据的成本。
1.0是成本常数io_block_read_cost的默认值,表示把磁盘文件中的一个数据页加载到 Buffer Pool 的成本,加上从 Buffer Pool 中的该数据页读取数据的成本。
cpu_cost = n_rows * 0.1。
n_rows 是表中记录的数量,从表的统计信息中得到,在统计信息小节会介绍。
0.1是成本常数row_evaluate_cost的默认值,表示访问一条记录的 CPU 成本。
有了上面这些公式,我们通过一个具体例子走一遍全表扫描成本计算的过程。
假设一个表有 15228 条记录,主键索引数据页的数量为 739,主键索引数据页已经全部加载到 Buffer Pool(pages_in_memory_percent = 1.0),下面我们开始计算过程:
- pages_on_disk_percent = 1 -pages_in_memory_percent(1.0) =0.0。
- avg_single_page_cost =pages_in_memory_percent(1.0) *0.25+pages_on_disk_percent(0.0) *1.0=0.25。
- io_cost =cluster_page_count(739) *avg_single_page_cost(0.25) =184.75。
- cpu_cost =n_rows(15228) * 0.1 =1522.8。
- 全表扫描成本 =io_cost(184.75) +1.1+cpu_cost(1522.8) +1=1709.55
统计信息
全表扫描成本计算过程中,用到了主键索引数据页数量、表中记录数量,这两个数据都来源 InnoDB 的表统计信息。

clustered_index_size就是主键索引数据页数量,n_rows是表中记录数量。
数据页在内存中的比例
avg_single_page_cost =pages_in_memory_percent 0.25 +pages_on_disk_percent 1.0**。
上面的公式用于计算读取一个数据页的平均成本,pages_in_memory_percent 是主键索引已经加载到 Buffer Pool 中的叶结点占所有叶结点的比例。
计算代码如下:
inline double index_pct_cached(const dict_index_t *index) { // 索引叶结点数量 const ulint n_leaf = index->stat_n_leaf_pages; ...... // 已经加载到 Buffer Pool 中的叶结点数量 const uint64_t n_in_mem = buf_stat_per_index->get(index_id_t(index->space, index->id)); // 已加载到 Buffer Pool 中的叶结点 [除以] 索引叶结点数量 const double ratio = static_cast(n_in_mem) / n_leaf; // 取值只能在 0.0 ~ 1.0 之间 return (std::max(std::min(ratio, 1.0), 0.0));}InnoDB 在内存中维护了一个哈希表(buf_stat_per_index->m_store),key 是表名,value 是表的主键索引已经加载到 Buffer Pool 中的叶子结点数量。
每次从磁盘加载某个表的主键索引的一个叶子结点数据页到 Buffer Pool 中,该表在buf_stat_per_index->m_store中对应的 value 值就加一。
从 Buffer Pool 的 LRU 链表淘汰某个表的主键索引叶子结点时,该表在buf_stat_per_index->m_store中对应的 value 值就减一。
还有其它场景,buf_stat_per_index->m_store 中的 value 值也会发生变化,不展开了。
成本常数
memory_block_read_cost 和 io_block_read_cost 这两个成本常数从系统表mysql.engine_cost中读取,默认分别是1.0和0.25
索引成本计算
以如下sql为例

列resource_type的搜索条件是 BETWEEN 1 AND 2,形成的扫描区间就是[1,2]。**优化器规定,读取二级索引的一个扫描区间的IO成本,和读取一个页面的IO成本相同,无论它占用多少页面。(这个是规定,大家记住就好了)因此二级索引页的IO成本就是1.0。
接下来就是估算二级索引过滤后的记录数量了,也就是满足resource_type BETWEEN 1 AND 2的记录数量。MySQL是这样预估的:
- 找到索引树中resource_type=1的第一条记录,称为该区间的最左记录,这个过程是极快的。
- 找到索引树中resource_type=2的最后一条记录,称为该区间的最右记录,这个过程也是极快的。
- 从最左记录向右最多读10个页面,如果读到了最右记录,则精确计算区间的记录数。
- 如果读不到最右记录,说明中间记录比较多,则采用预估法。对10个页面中的记录数取平均值,用平均值乘以区间的页面数量即可。
索引页的Page Header部分有PAGE_N_RECS属性记录了页中的记录数,因此不用遍历每个页里的记录
又带来一个新的问题,如何计算这个区间的页面数量呢?还记得B+树的结构吗?该区间的第0层的叶子节点数虽然很多,难以统计,但是我们可以看它们的父节点啊,这两个索引页的目录项大概率是会在同一个父节点页中的,在父节点页中统计区间内有多少页面就非常容易了,其实就是统计两个目录项之间隔了多少个目录项记录。
这里,我们假设满足resource_type BETWEEN 1 AND 2的记录数是15000个,则二级索引记录的CPU成本是15000 * 0.2 + 0.01 = 3000.01
接下来就是这15000条记录回表的IO成本了,MySQL规定,每次回表的IO成本相当于读取一个页面的IO成本,二级索引过滤出的记录数量就是回表的次数。因此,回表的IO成本是15000 * 1.0 = 15000.0。
综上所述,使用索引的执行成本是:
- IO成本:15000.0+1.0= 15001.0
- CPU成本:3000.01
- 总索引成本:15001.0+3000.01=18001.01
通过和全表扫描对比,孰优孰劣一目了然。这下是不是清楚多了?
小结
MySQL执行一条查询语句的流程是这样的,先找到所有可能用到的索引,然后计算全表扫描的成本,然后分别计算使用不同索引的成本,最终选择成本最低的方案来执行查询。这里说的成本其实是由IO成本和CPU成本组成的,对于InnoDB引擎来说,读取一个页的IO成本是1.0,读取一条记录并检测是否符合搜索条件的CPU成本是0.2。全表扫描的成本计算非常简单,根据表的统计数据即可预估出聚簇索引占用的页面数和表的总记录数。对于二级索引的辅助查询,除了过滤二级索引本身的IO成本+CPU成本,还有回表的IO成本+CPU成本,
作者:京东物流 刘海运