面积图,或称区域图,是一种随有序变量的变化,反映数值变化的统计图表。
面积图也可用于多个系列数据的比较。
这时,面积图的外观看上去类似层叠的山脉,在错落有致的外形下表达数据的总量和趋势。
面积图不仅可以清晰地反映出数据的趋势变化,也能够强调不同类别的数据间的差距对比。
面积图的特点在于,折线与自变量坐标轴之间的区域,会由颜色或者纹理填充。
但它的劣势在于,填充会让形状互相遮盖,反而看不清变化。一种解决方法,是使用有透明度的颜色,来“让”出覆盖区域。
1. 主要元素
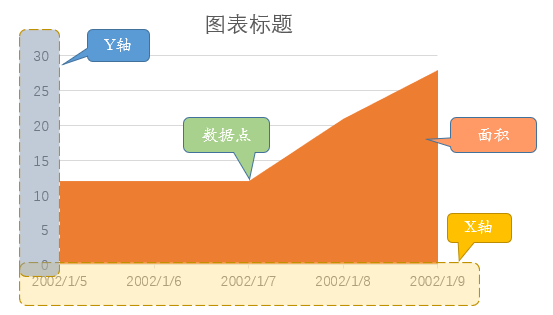
面积图是一种用于展示数据分布或密度的图表类型,主要由数据点、面积、以及X轴和Y轴组成。
面积图可以直观地反映数据的分布情况。
面积图的主要构成元素包括:
- 数据点:表示数据的具体位置和大小
- 面积:表示数据的分布或密度
- X轴:一般是有序变量,表示数据点的变化区间
- Y轴:数据点在不同时刻的值
2. 适用的场景
面积图适用于以下分析场景:
- 数据分布分析:帮助分析人员了解数据的分布情况,如城市的大小、人口分布等。
- 市场需求分析:帮助企业了解市场需求的变化趋势,如销售额的增长情况等。
- 健康状况分析:帮助医生了解患者的健康状况,如体温、血压等数据的变化趋势。
3. 不适用的场景
面积图不适用于以下分析场景:
- 数据的精确性要求较高的分析场景:面积图无法精确地反映数据的分布情况,在需要精确数据的场景中不适用。
- 需要显示数据细节的分析场景:面积图无法直观地显示数据的细节和变化趋势,在需要显示数据细节的场景中不适用。
- 需要进行多维数据分析的场景:面积图无法直接展示多维数据,在需要进行多维数据分析的场景中不适用。
4. 分析实战
这次使用国内生产总值相关数据来实战面积图的分析。
4.1. 数据来源
数据来源国家统计局公开数据,已经整理好的csv文件在:https://databook.top/nation/A02
本次分析使用其中的 A0201.csv 文件(国内生产总值数据)。
下面的文件路径 fp 要换成自己实际的文件路径。
fp = "d:/share/A0201.csv"df = pd.read_csv(fp)df
4.2. 数据清理
从中过滤出国内生产总值(亿元)和人均国内生产总值(元),然后绘制面积图看看有什么发现。
key1 = "国民总收入(亿元)"df[df["zbCN"]==key1].head()
key2 = "人均国内生产总值(元)"df[df["zbCN"]==key2].head()
4.3. 分析结果可视化
国内生产总值(亿元)的面积图:
from matplotlib.ticker import MultipleLocatorwith plt.style.context("seaborn-v0_8"): fig = plt.figure() ax = fig.add_axes([0.1, 0.1, 0.8, 0.8]) ax.xaxis.set_major_locator(MultipleLocator(4)) ax.xaxis.set_minor_locator(MultipleLocator(2)) data = df[df["zbCN"] == key1].copy() data["value"] = data["value"] / 10000 data = data.sort_values(by="sj") ax.fill_between(data["sjCN"], data["value"], label="国民总收入(万亿元)") ax.legend(loc="upper left")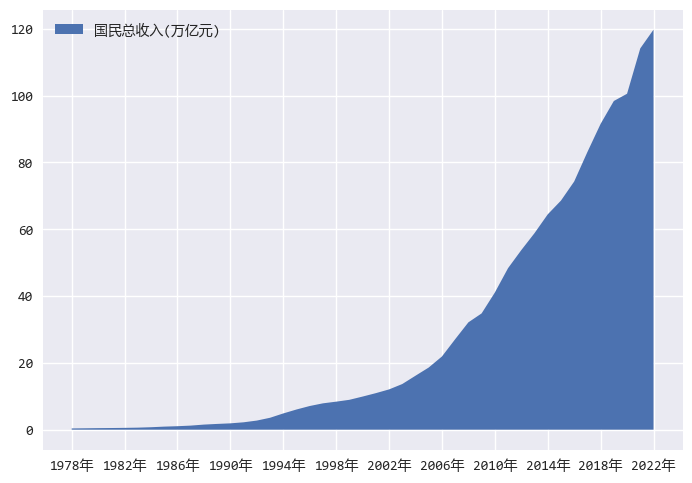
上面的代码把Y轴的单位改成了万亿元,原先的亿元作为单位,数值太大。
用面积图来展示分析结果,不像折线图那样,仅仅只是变化趋势的感觉;
通过折线下的面积不断扩大,会感觉到国民总收入的总量在不断变大,且2006年之后,总量增速明显提高。
同样分析步骤,人均收入的面积图如下:
from matplotlib.ticker import MultipleLocatorwith plt.style.context("seaborn-v0_8"): fig = plt.figure() ax = fig.add_axes([0.1, 0.1, 0.8, 0.8]) ax.xaxis.set_major_locator(MultipleLocator(4)) ax.xaxis.set_minor_locator(MultipleLocator(2)) data = df[df["zbCN"] == key2].copy() data = data.sort_values(by="sj") ax.fill_between(data["sjCN"], data["value"], label=key2) ax.legend(loc="upper left")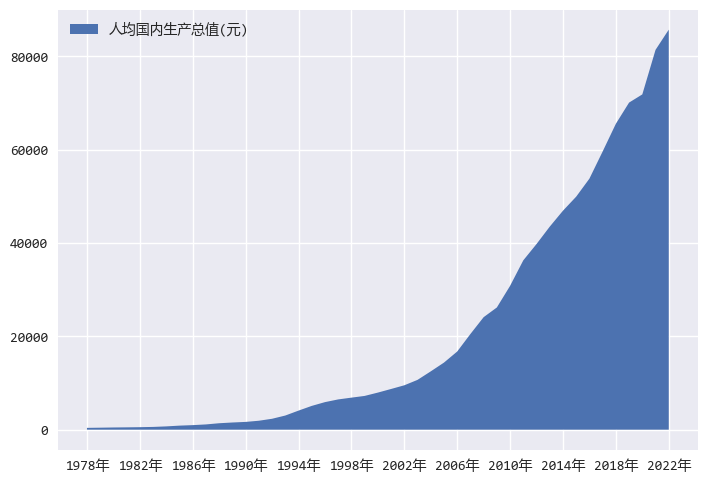
接下来,我们把国民总收入和人均收入放在一起看,但是,这两组数据的单位不一样(一个是万亿元,一个是元)。
所以要用到之前 matplotlib基础系列中介绍的双坐标轴技巧来展示。
from matplotlib.ticker import MultipleLocatorwith plt.style.context("seaborn-v0_8"): fig = plt.figure() ax = fig.add_axes([0.1, 0.1, 0.8, 0.8]) ax.xaxis.set_major_locator(MultipleLocator(4)) ax.xaxis.set_minor_locator(MultipleLocator(2)) ax_twinx = ax.twinx() data = df[df["zbCN"] == key1].copy() data["value"] = data["value"] / 10000 data = data.sort_values(by="sj") ax.fill_between(data["sjCN"], data["value"], alpha=0.5, label="国民总收入(万亿元)") data = df[df["zbCN"] == key2].copy() data = data.sort_values(by="sj") ax_twinx.fill_between(data["sjCN"], data["value"], color='r', alpha=0.2, label=key2) ax.legend(loc="upper left") ax_twinx.legend(loc="upper right")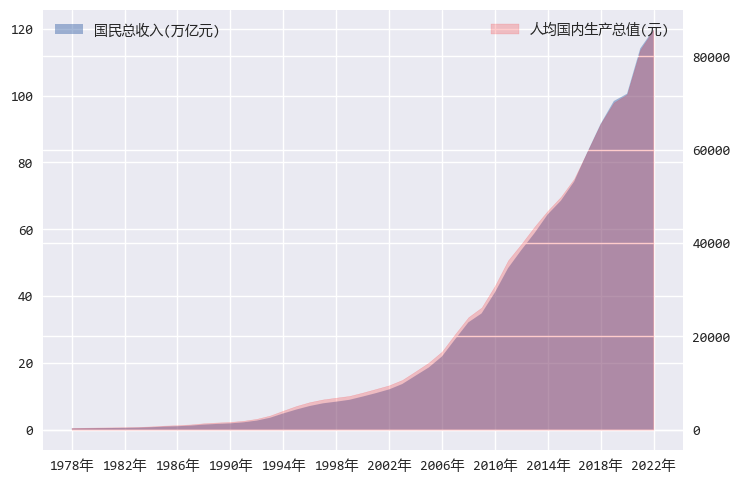
两个面积图用了不同颜色,并加了透明度(即alpha 参数),不加透明度,颜色会互相覆盖。
左边的Y轴是国民总收入,右边的Y轴是人均收入。
这两个面积图几乎完全重合,正说明了国民总收入和人均收入是强相关的。