一 、Ribbon概述
Netflixfa 发布的一个负载均衡器,有助于控制HTTP和TCP客户端行为。在SpringCloud中,Ribbon提供了客户端负载均衡的功能,Ribbon自动从服务注册中心Eureka中读取到的服务提供者的列表信息(动态获取服务列表方式),在调用服务节点提供的服务时,基于内置的负载均衡算法,合理进行负载。
1、Ribbon的主要作用
(1)服务调用 基于Ribbon实现服务调用, 是通过拉取到的所有服务列表组成(服务名-请求路径的)映射关系。借助RestTemplate最终进行调用;
(2)负载均衡 当有多个服务提供者时,Ribbon可以根据负载均衡的算法自动的选择需要调用的服务地址。
2、服务调用Ribbon高级
(1)负载均衡概述
在搭建网站时,如果单节点的 web服务性能和可靠性都无法达到要求;或者是在使用外网服务时,经常担心被人攻破,一不小心就会有打开外网端口的情况,通常这个时候加入负载均衡就能有效解决服务问题。 负载均衡是一种基础的网络服务,其原理是通过运行在前面的负载均衡服务,按照指定的负载均衡算法,将流量分配到后端服务集群上,从而为系统提供并行扩展的能力。 负载均衡的应用场景包括流量包、转发规则以及后端服务,由于该服务有内外网个例、健康检查等功 能,能够有效提供系统的安全性和可用性。
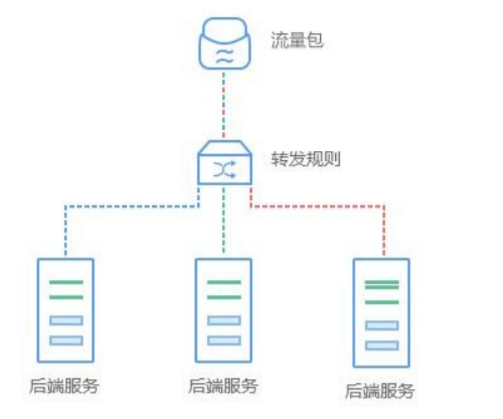
(2) 客户端负载均衡与服务端负载均衡
服务端负载均衡:先发送请求到负载均衡服务器或者软件,然后通过负载均衡算法,在多个服务器之间选择一个进行访 问;即在服务器端再进行负载均衡算法分配。
客户端负载均衡:客户端会有一个服务器地址列表,在发送请求前通过负载均衡算法选择一个服务器,然后进行访问,这是客户端负载均衡;即在客户端就进行负载均衡算法分配。
3、Feign简介
Feign是Netflix开发的声明式,模板化的HTTP客户端,其灵感来自Retrofit、JAXRS-2.0以及WebSocket. Feign可帮助我们更加便捷、优雅的调用HTTP API。 在SpringCloud中,使用Feign非常简单。 Feign支持多种注解,例如Feign自带的注解或者JAX-RS注解等。 SpringCloud对Feign进行了增强,使Feign支持了SpringMVC注解,并整合了Ribbon和Eureka, 从而让Feign的使用更加方便。
3.1 基于Feign的服务调用
(1)引入依赖 在服务消费者 shop_service_order 添加Fegin依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId></dependency>
(2)启动类添加Feign的支持
@SpringBootApplication(scanBasePackages="cn.itcast.order")@EntityScan("cn.itcast.entity")@EnableFeignClientspublic class OrderApplication { public static void main(String[] args) { SpringApplication.run(OrderApplication.class, args); }}
通过@EnableFeignClients注解开启Spring Cloud Feign的支持功能
(3)启动类激活FeignClient
创建一个Feign接口,此接口是在Feign中调用微服务的核心接口 在服务消费者 shop_service_order 添加一个 ProductFeginClient 接口
//指定需要调用的微服务名称@FeignClient(name="shop-service-product")public interface ProductFeginClient {//调用的请求路径@RequestMapping(value = "/product/{id}",method = RequestMethod.GET)public Product findById(@PathVariable("id") Long id);}
定义各参数绑定时,@PathVariable、@RequestParam、@RequestHeader等可以指定参数属性,在Feign中绑定参数必须通过value属性来指明具体的参数名,不然会抛出异常 @FeignClient:注解通过name指定需要调用的微服务的名称,用于创建Ribbon的负载均衡器。 所以Ribbon会把shop-service-product解析为注册中心的服务。
3.2 Feign和Ribbon的联系
Ribbon是一个基于HTTP和TCP客户端的负载均衡的工具。可以在客户端配置 RibbonServerList(服务端列表),使用 HttpClient 或 RestTemplate 模拟http请求,步骤相当繁琐。
Feign是在Ribbon的基础上进行了一次改进,是一个使用起来更加方便的HTTP客户端。采用接口的方式,只需要创建一个接口,然后在上面添加注解即可,将需要调用的其他服务的方法定义成抽象方法即可,不需要自己构建http请求。然后就像是调用自身工程的方法调用,而感觉不到是调用远程方法,使得编写客户端变得非常容易。
3.3 负载均衡
Feign中本身已经集成了Ribbon依赖和自动配置,因此我们不需要额外引入依赖,也不需要再注册 RestTemplate 对象。
二、服务熔断Hystrix入门
1、服务容错的核心知识
(1)雪崩效应
在微服务架构中,一个请求需要调用多个服务是非常常见的。如客户端访问A服务,而A服务需要调用B服务,B服务需要调用C服务,由于网络原因或者自身的原因,如果B服务或者C服务不能及时响应,A服务将处于阻塞状态,直到B服务C服务响应。此时若有大量的请求涌入,容器的线程资源会被消耗完毕, 导致服务瘫痪。服务与服务之间的依赖性,故障会传播,造成连锁反应,会对整个微服务系统造成灾难 性的严重后果,这就是服务故障的“雪崩”效应。
雪崩是系统中的蝴蝶效应导致其发生的原因多种多样,有不合理的容量设计,或者是高并发下某一个方 法响应变慢,亦或是某台机器的资源耗尽。从源头上我们无法完全杜绝雪崩源头的发生,但是雪崩的根本原因来源于服务之间的强依赖,所以我们可以提前评估,做好熔断、隔离、限流。
(2) 服务隔离
顾名思义,它是指将系统按照一定的原则划分为若干个服务模块,各个模块之间相对独立,无强依赖。 当有故障发生时,能将问题和影响隔离在某个模块内部,而不扩散风险,不波及其它模块,不影响整体的系统服务。
(3)熔断降级
在互联网系统中,当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫做熔断。
所谓降级,就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的 fallback回调,返回一个缺省值。
(4)服务限流
限流可以认为服务降级的一种,限流就是限制系统的输入和输出流量已达到保护系统的目的。一般来说系统的吞吐量是可以被测算的,为了保证系统的稳固运行,一旦达到的需要限制的阈值,就需要限制流 量并采取少量措施以完成限制流量的目的。比如:推迟解决,拒绝解决,或者部分拒绝解决等等。
2、Hystrix介绍
Hystrix是由Netflix开源的一个延迟和容错库,用于隔离访问远程系统、服务或者第三方库,防止级联失败,从而提升系统的可用性与容错性。Hystrix主要通过以下几点实现延迟和容错。
包裹请求:使用HystrixCommand包裹对依赖的调用逻辑,每个命令在独立线程中执行。这使用了设计模式中的“命令模式”。
跳闸机制:当某服务的错误率超过一定的阈值时,Hystrix可以自动或手动跳闸,停止请求该服务一段时间。
资源隔离:Hystrix为每个依赖都维护了一个小型的线程池(或者信号量)。如果该线程池已满, 发往该依赖的请求就被立即拒绝,而不是排队等待,从而加速失败判定。
监控:Hystrix可以近乎实时地监控运行指标和配置的变化,例如成功、失败、超时、以及被拒绝 的请求等。
回退机制:当请求失败、超时、被拒绝,或当断路器打开时,执行回退逻辑。回退逻辑由开发人员自行提供,例如返回一个缺省值。
自我修复:断路器打开一段时间后,会自动进入“半开”状态。
3、 Rest实现服务熔断
(2)配置依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId></dependency>
(3)开启熔断
在启动类 OrderApplication 中添加 @EnableCircuitBreaker 注解开启对熔断器的支持。
@EntityScan("cn.itcast.entity")
//@EnableCircuitBreaker //开启熔断器
//@SpringBootApplication
@SpringCloudApplicationpublic class OrderApplication {//创建RestTemplate对象@Bean@LoadBalancedpublic RestTemplate restTemplate() {return new RestTemplate();}public static void main(String[] args) {SpringApplication.run(OrderApplication.class, args);}}
可以看到,我们类上的注解越来越多,在微服务中,经常会引入上面的三个注解,于是Spring就提供了 一个组合注解:@SpringCloudApplication
4)配置熔断降级业务逻辑
@RestController@RequestMapping("/order")public class OrderController {@Autowiredprivate RestTemplate restTemplate;//下订单@GetMapping("/product/{id}")@HystrixCommand(fallbackMethod = "orderFallBack")public Product findProduct(@PathVariable Long id) {return restTemplate.getForObject("http://shop-serviceproduct/product/1", Product.class);}//降级方法public Product orderFallBack(Long id) {Product product = new Product();product.setId(-1l);product.setProductName("熔断:触发降级方法");return product;}}
为 findProduct方法编写一个回退方法findProductFallBack,该方法与 findProduct 方法具有相同的参数与返回值类型,该方法返回一个默认的错误信息。 在 Product 方法上,使用注解@HystrixCommand的fallbackMethod属性,指定熔断触发的降级方法是findProductFallBack 。因为熔断的降级逻辑方法必须跟正常逻辑方法保证相同的参数列表和返回值声明。在findProduct 方法上HystrixCommand(fallbackMethod = “findProductFallBack”) 用来声明一个降级逻辑的方法。
4、断路器聚合监控Turbine
在微服务架构体系中,每个服务都需要配置Hystrix DashBoard监控。如果每次只能查看单个实例的监控数据,就需要不断切换监控地址,这显然很不方便。要想看这个系统的Hystrix Dashboard数据就需要用到Hystrix Turbine。Turbine是一个聚合Hystrix 监控数据的工具,它可以将所有相关微服务的 Hystrix 监控数据聚合到一起,方便使用。引入Turbine后,整个监控系统架构如下:
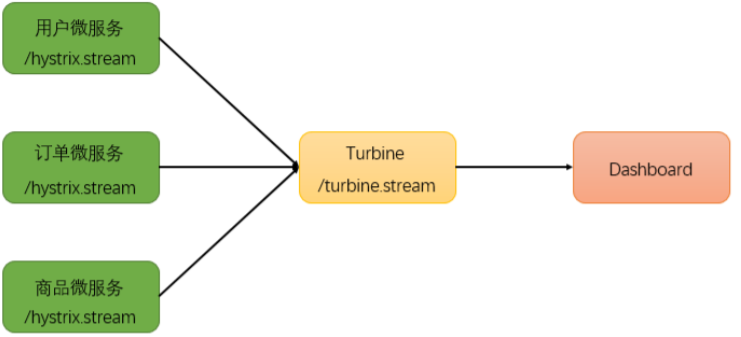
(1) 搭建TurbineServer 创建工程 shop_hystrix_turbine 引入相关坐标
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-turbine</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId></dependency>
(2) 配置多个微服务的hystrix监控 在application.yml的配置文件中开启turbine并进行相关配置
server:port: 8031spring:application:name: microservice-hystrix-turbineeureka:client:service-url:defaultZone: http://localhost:8761/eureka/instance:prefer-ip-address: trueturbine:# 要监控的微服务列表,多个用,分隔appConfig: shop-service-orderclusterNameExpression: "'default'"eureka相关配置 : 指定注册中心地址
turbine相关配置:指定需要监控的微服务列表
turbine会自动的从注册中心中获取需要监控的微服务,并聚合所有微服务中的 /hystrix.stream 数据
(3)配置启动类
@SpringBootApplication@EnableTurbine@EnableHystrixDashboardpublic class TurbineServerApplication {public static void main(String[] args) {SpringApplication.run(TurbineServerApplication.class, args);}}
作为一个独立的监控项目,需要配置启动类,开启HystrixDashboard监控平台,并激活Turbine
5、熔断器的状态
熔断器有三个状态 CLOSED 、 OPEN 、 HALF_OPEN 熔断器默认关闭状态,当触发熔断后状态变更为 OPEN ,在等待到指定的时间,Hystrix会放请求检测服务是否开启,这期间熔断器会变为 HALF_OPEN 半 开启状态,熔断探测服务可用则继续变更为 CLOSED 关闭熔断器。
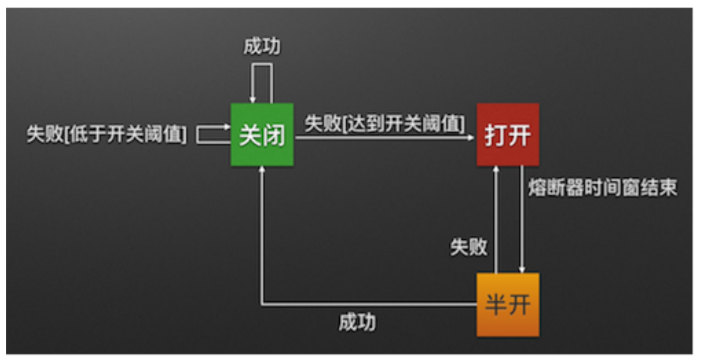
Closed:关闭状态(断路器关闭),所有请求都正常访问。代理类维护了最近调用失败的次数, 如果某次调用失败,则使失败次数加1。如果最近失败次数超过了在给定时间内允许失败的阈值, 则代理类切换到断开(Open)状态。此时代理开启了一个超时时钟,当该时钟超过了该时间,则切换到半断开(Half-Open)状态。该超时时间的设定是给了系统一次机会来修正导致调用失败的错误。
Open:打开状态(断路器打开),所有请求都会被降级。Hystix会对请求情况计数,当一定时间 内失败请求百分比达到阈值,则触发熔断,断路器会完全关闭。默认失败比例的阈值是50%,请求 次数最少不低于20次。
Half Open:半开状态,open状态不是永久的,打开后会进入休眠时间(默认是5S)。随后断路 器会自动进入半开状态。此时会释放1次请求通过,若这个请求是健康的,则会关闭断路器,否则 继续保持打开,再次进行5秒休眠计时。
熔断器的默认触发阈值是20次请求,不好触发。休眠时间时5秒,时间太短,不易观察,为了测试方便,我们可以通过配置修改熔断策略:
circuitBreaker.requestVolumeThreshold=5circuitBreaker.sleepWindowInMilliseconds=10000circuitBreaker.errorThresholdPercentage=50requestVolumeThreshold:触发熔断的最小请求次数,默认20
errorThresholdPercentage:触发熔断的失败请求最小占比,默认50%
sleepWindowInMilliseconds:熔断多少秒后去尝试请求
6、熔断器的隔离策略
微服务使用Hystrix熔断器实现了服务的自动降级,让微服务具备自我保护的能力,提升了系统的稳定性,也较好的解决雪崩效应。其使用方式目前支持两种策略:
(1)线程池隔离策略:使用一个线程池来存储当前的请求,线程池对请求作处理,设置任务返回处理超时时间,堆积的请求堆积入线程池队列。这种方式需要为每个依赖的服务申请线程池,有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队里慢慢处理)。
(2)信号量隔离策略:使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,请求来先判断计数器的数值,若超过设置的最大线程个数则丢弃该类型的新请求,若不超过则执行计数操作请求来计数器+1,请求返回计数器-1。这种方式是严格的控制线程且立即返回模式,无法应对突发流量(流量洪峰来临时,处理的线程超过数量,其他的请求会直接返回,不继续去请求依赖的服务)。
线程池和型号量两种策略功能支持对比如下:

hystrix.command.default.execution.isolation.strategy : 配置隔离策略
ExecutionIsolationStrategy.SEMAPHORE 信号量隔离
ExecutionIsolationStrategy.THREAD 线程池隔离
hystrix.command.default.execution.isolation.maxConcurrentRequests : 最大信号量上限
7、Hystrix的核心源码
Hystrix 底层基于 RxJava,RxJava 是响应式编程开发库,因此Hystrix的整个实现策略简单说即:把一个HystrixCommand封装成一个Observable(待观察者),针对自身要实现的核心功能,对Observable进行各种装饰,并在订阅各步装饰的Observable,以便在指定事件到达时,添加自己的业务。
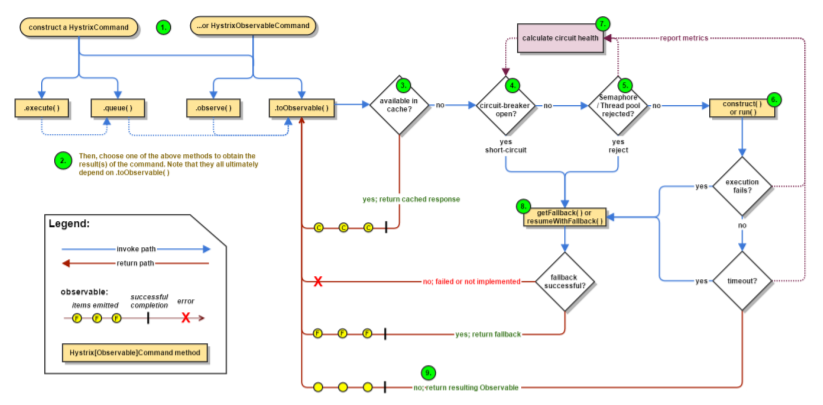
Hystrix主要有4种调用方式:
toObservable() 方法 :未做订阅,只是返回一个Observable ;
observe() 方法 :调用 #toObservable() 方法,并向 Observable 注册 rx.subjects.ReplaySubject 发起订阅;
queue() 方法 :调用 #toObservable() 方法的基础上,调用:Observable#toBlocking() 和 BlockingObservable#toFuture() 返回 Future 对象;
execute() 方法 :调用 #queue() 方法的基础上,调用 Future#get() 方法,同步返回 #run() 的执行结果。
主要的执行逻辑:
1). 每次调用创建一个新的HystrixCommand,把依赖调用封装在run()方法中.
2). 执行execute()/queue做同步或异步调用.
3). 判断熔断器(circuit-breaker)是否打开,如果打开跳到步骤8,进行降级策略,如果关闭进入步骤4
4). 判断线程池/队列/信号量是否跑满,如果跑满进入降级步骤8,否则继续后续步骤5
5). 调用HystrixCommand的run方法.运行依赖逻辑,依赖逻辑调用超时,执行步骤6
6). 判断逻辑是否调用成功。返回成功调用结果;调用出错,执行步骤7
7). 计算熔断器状态,所有的运行状态(成功, 失败, 拒绝,超时)上报给熔断器,用于统计从而判断熔断器状态.
8). getFallback()降级逻辑。
以下四种情况将触发getFallback调用:
1). run()方法抛出非HystrixBadRequestException异常。
2). run()方法调用超时
3). 熔断器开启拦截调用
4). 线程池/队列/信号量是否跑满
5). 没有实现getFallback的Command将直接抛出异常,fallback降级逻辑调用成功直接返回,降 级逻辑调用失败抛出异常.
9). 返回执行成功结果
8、请求合并
Hystrix支持将多个请求自动合并为一个请求,通过合并可以减少HystrixCommand并发执行所需的线程和网络连接数量,极大地节省了开销,提高了系统效率。请求合并是由Hystrix自动合并进行的,并不需要在开发时进行代码介入(注意,这里只是说合并请求不需要代码介入,但对于批量请求的处理,还是需要写一些代码的)。需要注意的是,多个请求能自动合并的前提是请求之间要足够“近”,即执行的间隔时长要足够小(默认为10ms,可通过hystrix.collapser.default.timerDelayInMilliseconds进行设置),即执行间隔超过10ms的请求不会合并执行。
如果没有启用请求合并,那么在HystrixCommand执行的线程池和后端业务执行中都会存在大量的并发,很可能会造成性能瓶颈。另外,如果要让Hystrix能够使用到请求合并,那么业务代码必须提供能够批量处理的接口。
9、服务熔断Hystrix的替换方案
18年底Netflix官方宣布Hystrix 已经足够稳定,不再积极开发 Hystrix,该项目将处于维护模式。就目前来看Hystrix是比较稳定的,并且Hystrix只是停止开发新的版本,并不是完全停止维护,Bug什么的依然会维护的。因此短期内,Hystrix依然是继续使用的。但从长远来看,Hystrix总会达到它的生命周期。
(1)替换方案介绍
Alibaba Sentinel
Sentinel 是阿里巴巴开源的一款断路器实现,目前在Spring Cloud的孵化器项目Spring Cloud Alibaba 中的一员Sentinel本身在阿里内部已经被大规模采用,非常稳定。因此可以作为一个较好的替代品。
Resilience4J
Resilicence4J 一款非常轻量、简单,并且文档非常清晰、丰富的熔断工具,这也是Hystrix官方推荐的替代产品。不仅如此,Resilicence4j还原生支持Spring Boot 1.x/2.x,而且监控也不像Hystrix一样弄 Dashboard/Hystrix等一堆轮子,而是支持和Micrometer(Pivotal开源的监控门面,Spring Boot 2.x 中的Actuator就是基于Micrometer的)、prometheus(开源监控系统,来自谷歌的论文)、以及 Dropwizard metrics(Spring Boot曾经的模仿对象,类似于Spring Boot)进行整合。
(1.1) Sentinel概述
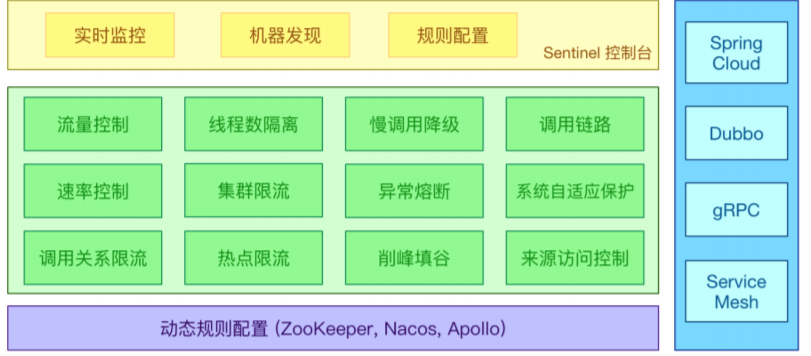
Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Sentinel 具有以下特征:
丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即 突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用 应用等。
完备的实时监控:Sentinel 同时提供实时的监控功能。可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。 完善的SPI扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
Sentinel 的主要特性:
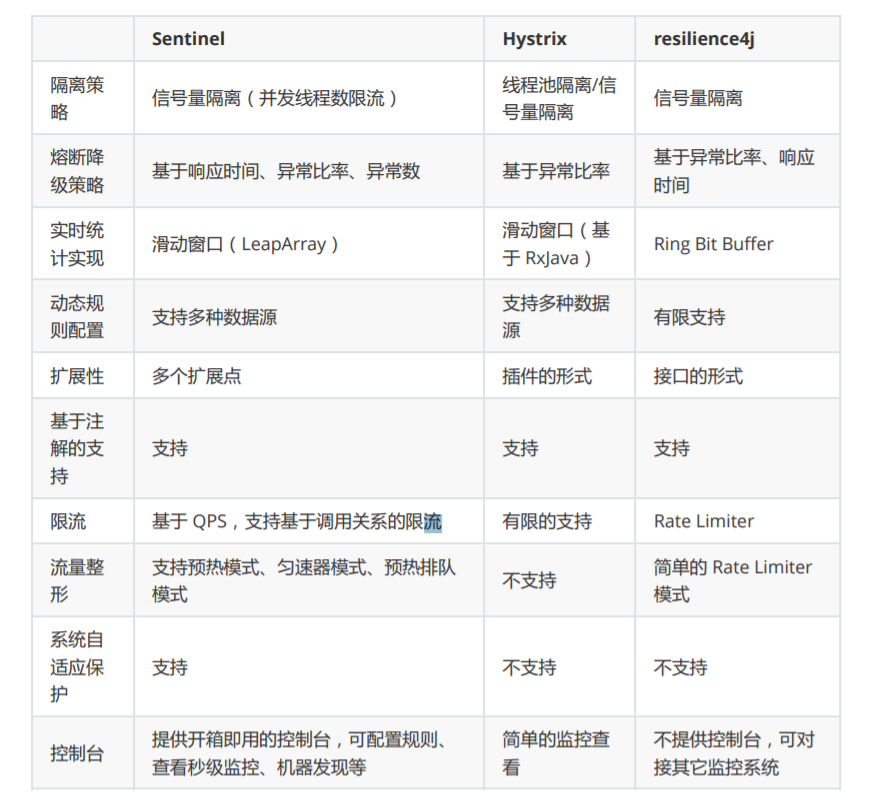
(1.2) Sentinel与Hystrix的区别
(1.3) 迁移方案
Sentinel官方提供了详细的由Hystrix 迁移到Sentinel 的方法

感谢阅读,借鉴了不少大佬资料,如需转载,请注明出处,谢谢!https://www.cnblogs.com/huyangshu-fs/p/13882618.html