本文是 eBPF 系列的第二篇文章,我们来学习 eBPF BCC 框架的进阶用法,对上一篇文章中的代码进行升级,动态输出进程运行时的参数情况。
主要内容包括:
- 通过
kprobe挂载内核事件的 eBPF 程序要如何编写?- 通过
tracepoint挂载内核事件的 eBPF 程序要如何编写?- eBPF 的程序事件类型有哪些?
在开始之前,我们来回顾一下前一篇文章的内容。
前一篇文章介绍了如何通过 BCC 框架来编写一个简单的 eBPF 程序。在内核空间,使用 c 程序实现 eBPF 的核心逻辑;在用户空间,使用 python 脚本作为 eBPF 程序的控制、加载和展示。其中,内核态通过若干 eBPF helper 函数,获取内核观测数据,并通过 PERF 区域,将这些数据传递到用户空间;用户态使用attach_kprobe() 将内核 eBPF 函数绑定到某个内核事件上。
整个流程如下图所示:
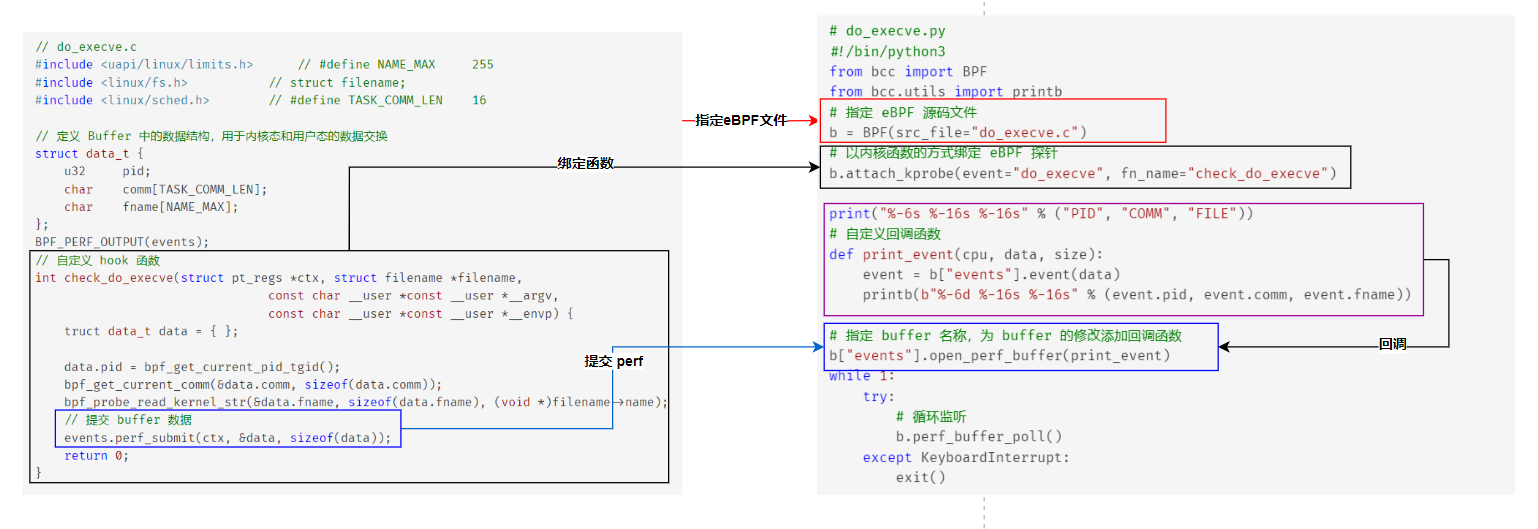
在上面的实现过程中,用户态通过 kprobe 的方式,为某个内核事件挂载自定义处理逻辑(图中是指定了内核中 do_execve 函数)。通过这种方式,我们能够监测绝大部分的内核函数,这正是 eBPF 技术牛逼的原因。
对于这种 kprobe 类型的 eBPF 程序,我们再来看一个例子(改编自 Brendan Gregg 大神的 execsnoop 工具:https://github.com/iovisor/bcc/blob/master/tools/execsnoop.py )
1 进程执行参数的监控
接下来,我们要对上图中的工具再次进行功能升级,我希望这个工具在运行时,能够输出当前执行进程的参数信息。
如果将 eBPF 程序等同于 C 程序来看,这个问题似乎没那么困难。何以见得?
1.1 分析
sys_execve 系统调用的函数签名为:int execve(const char *filename, char *const argv[], char *const envp[]), 其中,argv[]便记录了进程执行的参数。我们大可以像提取 filename 的方式那样,提取 argv[],并将其传入到用户空间中。
但实际上,eBPF 程序与 C 程序并不等同。eBPF 编程中有 “两座大山” 般的限制,分别是:
限制一:eBPF 程序运行栈仅有 512 字节。
限制二:eBPF 程序可以调用的接口极其有限。
因此,如果我们想尝试在 512 字节的 eBPF 运行栈中完整拼接整理不定长的 argv[] 参数列表,是根本不可能的。
基于以上分析,本文给出一个比较合理的解决方案:
Q:如何防止运行栈爆栈?
1)既然运行栈有大小限制,不如直接将拼接操作转移到用户态完成。eBPF 程序只需要将 argv[] 数组中每个 argv 传输到用户态程序中。
2)对于长度过长的 argv,没办法了,只能手动截断了。
Q:用户态何时进行参数拼接?何时进行参数展示?
1)既然需要用户态完成拼接,那么,可以分为两个阶段。STEP-1,仅专注字符串的拼接;STEP-2,仅专注字符串展示。
2)对于 execve 系统调用,我们可以在 enter 时执行 STEP-1 操作,在 exit 是执行 STEP-2 操作。
接下来更新代码。
1.2 定义
首先,对于用于交互的结构体,增加两个个字段,其一用于记录 execve 调用的每个参数,其二用于记录 eBPF 执行的阶段;同时,去掉冗余字段 fname
#define ARGSIZE 128#define MAXARG 60enum event_step {STEP_1,// STEP 1: 执行 argv 拼接STEP_2,// STEP 2: 执行 argv 展示};struct data_t {u32pid;enumevent_step step;// 记录 eBPF 执行阶段charcomm[TASK_COMM_LEN];charargv[ARGSIZE];// 记录每一个参数};定义 BPF_PERF_OUTPUT:
BPF_PERF_OUTPUT(events);1.3 处理
实现 execve 系统调用 enter 和 exit 回调函数:
// exter execveint syscall__execve(struct pt_regs *ctx, const char __user *filename,const char __user *const __user *__argv,const char __user *const __user *__envp) {struct data_t data = {};// 设置 step = STEP 1data.step = STEP_1;// 设置 piddata.pid = bpf_get_current_pid_tgid() >> 32;// 设置 commbpf_get_current_comm(&data.comm, sizeof(data.comm));// 设置每一个 argv,并导出...return 0;}// exit execveint do_ret_sys_execve(struct pt_regs *ctx) {struct data_t data = {};// 设置 step = STEP 1data.step = STEP_2;// 设置 piddata.pid = bpf_get_current_pid_tgid() >> 32;// 设置 commbpf_get_current_comm(&data.comm, sizeof(data.comm));// 提交 perfevents.perf_submit(ctx, &data, sizeof(data)); return 0;}注意,这里 bpf_get_current_pid_tgid() 辅助函数返回值高 32 为内核视角下的 process ID(用户视角下为 TID),低 32 位为内核视角下的 thread group ID(用户视角下的 PID)。这里右移 32 位,是获取用户视角的 PID。
1.4 绑定
用户态绑定 kprobe 事件:
b = BPF(src_file="execsnoop.c")execve_fnname = b.get_syscall_fnname("execve")# enter 事件b.attach_kprobe(event=execve_fnname, fn_name="syscall__execve")# exit 事件b.attach_kretprobe(event=execve_fnname, fn_name="do_ret_sys_execve")1.5 难点
内核态如何设置并导出每一个 argv[]?
// 字符串提交static int __submit_arg(struct pt_regs *ctx, void *ptr, struct data_t *data) {// 提交 perf 之前,需要拷贝到用户态变量中bpf_probe_read_user(data->argv, sizeof(data->argv), ptr);// 将这个 argv 提交events.perf_submit(ctx, data, sizeof(struct data_t));return 1;}// 字符串控制static int submit_arg(struct pt_regs *ctx, void *ptr, struct data_t *data) {const char *argp = NULL;bpf_probe_read_user(&argp, sizeof(argp), ptr);// 是否到达末尾字符串if (argp) {return __submit_arg(ctx, (void *)(argp), data);}return 0;}int syscall__execve(struct pt_regs *ctx, const char __user *filename,const char __user *const __user *__argv,const char __user *const __user *__envp) {// 设置过程...// (A) 设置每一个 argv,并导出#pragma unrollfor (int i = 1; i < MAXARG; i++) {if (submit_arg(ctx, (void *)&__argv[i], &data) == 0)goto out;}// (B) 如果当前的 argv[] 太长了,进行截断操作char ellipsis[] = "...";__submit_arg(ctx, (void *)ellipsis, &data);out:return 0;}关注核心的两个步骤:
(A) MAXARG 代表一个 argv[] 的最大监测数量。首先要遍历这个 argv[] 的每一个字符串,如果这个字符不为 NULL(说明没有到当前 argv[] 结尾)或不超过最大值 MAXARG,那么将每个字符串提交到 PERF 区域。
注意:
低版本(5.3 以前)的 eBPF 程序不支持循环。5.3 版本后也仅支持有界循环。在低版本的 eBPF 中使用循环有一个小技巧,那就是通过#pragma unroll进行编译器循环展开预处理。
(B) 如果超过了这个最大数量 MAXARG,后面及时再有参数,也进行截断处理。
1.6 拼接
用户态获取和拼接参数列表是基于 eBPF 阶段的。
from collections import defaultdictargv = defaultdict(list)class EventStep(object):STEP_1 = 0STEP_2 = 1# PERF 事件回调处理def print_event(cpu, data, size):event = b["events"].event(data)# STEP 1:拼接if event.step == EventStep.STEP_1:argv[event.pid].append(event.argv)# STEP 2:显示elif event.step == EventStep.STEP_2:argv_text = b' '.join(argv[event.pid]).replace(b'\n', b'\\n')printb(b"%-16s %-7d %s" % (event.comm, event.pid, argv_text))try:del(argv[event.pid])except Exception:pass# 绑定 PERF 事件回调处理b["events"].open_perf_buffer(print_event)while 1:try:b.perf_buffer_poll()except KeyboardInterrupt:exit()用户态程序需要注意:event 事件通过 PERF 获取的结构数据为 Byte 类型,需要通过 decode('utf-8')/encode() 与 str 类型进行转换。
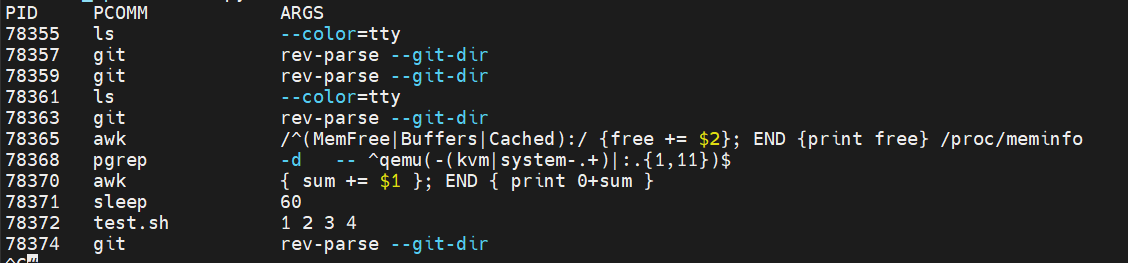
1.7 完整代码和运行效果
// execsnoop.c#include #include #define ARGSIZE 128#define MAXARG 60enum event_step {STEP_1,STEP_2,};struct data_t {u32pid;enumevent_step step;charcomm[TASK_COMM_LEN];charargv[ARGSIZE];};BPF_PERF_OUTPUT(events);static int __submit_arg(struct pt_regs *ctx, void *ptr, struct data_t *data) {bpf_probe_read_user(data->argv, sizeof(data->argv), ptr);events.perf_submit(ctx, data, sizeof(struct data_t));return 1;}static int submit_arg(struct pt_regs *ctx, void *ptr, struct data_t *data) {const char *argp = NULL;bpf_probe_read_user(&argp, sizeof(argp), ptr);if (argp) {return __submit_arg(ctx, (void *)(argp), data);}return 0;}// exter execveint syscall__execve(struct pt_regs *ctx, const char __user *filename,const char __user *const __user *__argv,const char __user *const __user *__envp) {struct data_t data = {};data.step = STEP_1;data.pid = bpf_get_current_pid_tgid() >> 32;bpf_get_current_comm(&data.comm, sizeof(data.comm));#pragma unrollfor (int i = 1; i > 32;bpf_get_current_comm(&data.comm, sizeof(data.comm));events.perf_submit(ctx, &data, sizeof(data));return 0;}# execsnoop.py#!/usr/bin/python3from bcc import BPFfrom bcc.utils import printbfrom collections import defaultdictargv = defaultdict(list)class EventStep(object):STEP_1 = 0STEP_2 = 1b = BPF(src_file="execsnoop.c")execve_fnname = b.get_syscall_fnname("execve")b.attach_kprobe(event=execve_fnname, fn_name="syscall__execve")b.attach_kretprobe(event=execve_fnname, fn_name="do_ret_sys_execve")print("%-7s %-16s %s" % ("PID", "PCOMM", "ARGS"))# process eventdef print_event(cpu, data, size):event = b["events"].event(data)fname = ""if event.step == EventStep.STEP_1:argv[event.pid].append(event.argv)elif event.step == EventStep.STEP_2:argv_text = b' '.join(argv[event.pid]).replace(b'\n', b'\\n')printb(b"%-7d %-16s %s" % (event.pid, event.comm, argv_text))try:del(argv[event.pid])except Exception:pass# loop with callback to print_eventb["events"].open_perf_buffer(print_event)while 1:try:b.perf_buffer_poll()except KeyboardInterrupt:exit()运行效果:
2 Tracepoint 追踪点
前文提到过,kprobe 方式,几乎可以使 eBPF 挂载到内核中任意一个函数事件上,随着内核函数的执行而触发。但是,由于不同的内核版本,其某个具体函数的定义、参数和实现可能会有所不同(kprobe 实现的事件处理函数要求和挂载点函数拥有相同的参数)。因此,使用 kprobe 方式实现的 eBPF 程序可能无法在其他内核的主机上运行。此外,kprobe 无法挂载到静态函数或内联函数上。而出于性能考虑,大部分网络相关的内层函数都是内联或者静态的,因此,kprobe 方式在这些领域也只能望洋兴叹了。
上述两点,均为 kprobe 方式的局限性,它并不具备很好的可移植性。于是,从 Linux 内核 4.7 开始,能让 eBPF 使用的 tracepoint 出现了(官方文档)。tracepoint 是由内核开发人员在代码中设置的静态 hook 点,具有稳定的 API 接口,不会随着内核版本的变化而变化。但由于 tracepoint 是需要内核研发人员参数编写,其数量有限,并不是所有的内核函数中都具有类似的跟踪点,所以从灵活性上不如 kprobes 这种方式。
2.1 kprobe 和 tracepoint 对比
在 3.10 内核中,kprobe 与 tracepoint 方式对比如下:
| 内容 | kprobe | tracepoint |
|---|---|---|
| 追踪类型 | 动态 | 静态 |
| Hook 点数量 | 100000+ | 1200+ |
| 稳定的 API | 否 | 是 |
可以使用以下命令查看系统支持的 tracepoint,支持 grep 检索。
perf listperf list | grep execve
上面的执行结果可以看到,execve系统调用具有两个 syscalls 类型的静态跟踪点,并且,tracepoint 已经对 enter 和 exit 做了区分,其功能基本等同于 kprobe/kretprobe。
在使用 tracepoint 之前,我们需要了解 tracepoint 相关参数的格式。syscalls:sys_enter_execve 格式定义在 /sys/kernel/debug/tracing/events/syscalls/sys_enter_execve/format 文件中。
# 查看 syscalls:sys_enter_execve 参数cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_execve/format2.2 重构代码
接下来,使用 tracepoint 方式重构第 1 节的代码,如下:
// execsnoop.c#include #include #define ARGSIZE 128#define MAXARG 60enum event_step {STEP_1,STEP_2,};struct data_t {u32 pid;char comm[TASK_COMM_LEN];enum event_step step;char argv[ARGSIZE];};BPF_PERF_OUTPUT(events);static int __submit_arg(struct pt_regs *ctx, void *ptr, struct data_t *data) {bpf_probe_read_user(data->argv, sizeof(data->argv), ptr);events.perf_submit(ctx, data, sizeof(struct data_t));return 1;}static int submit_arg(struct pt_regs *ctx, void *ptr, struct data_t *data) {const char *argp = NULL;bpf_probe_read_user(&argp, sizeof(argp), ptr);if (argp) {return __submit_arg(ctx, (void *)(argp), data);}return 0;}// (A) sys_enter_execve tracepointTRACEPOINT_PROBE(syscalls, sys_enter_execve) {struct data_t data = {};const char **argv = (const char **) (args->argv);data.step = STEP_1;data.pid = bpf_get_current_pid_tgid() >> 32;bpf_get_current_comm(&data.comm, sizeof(data.comm));#pragma unrollfor (int i = 1; i > 32;bpf_get_current_comm(&data.comm, sizeof(data.comm));events.perf_submit(args, &data, sizeof(data));return 0;}# execsnoop.py#!/usr/bin/python3from bcc import BPFfrom bcc.utils import printbfrom collections import defaultdictargv = defaultdict(list)class EventStep(object):STEP_1 = 0STEP_2 = 1# (C) 不再通过 kprobe 绑定 b = BPF(src_file="execsnoop.c")print("%-7s %-16s %s" % ("PID", "PCOMM", "ARGS"))# process eventdef print_event(cpu, data, size):event = b["events"].event(data)if event.step == EventStep.STEP_1:argv[event.pid].append(event.argv)elif event.step == EventStep.STEP_2:argv_text = b' '.join(argv[event.pid]).replace(b'\n', b'\\n')printb(b"%-7d %-16s %s" % (event.pid, event.comm, argv_text))try:del(argv[event.pid])except Exception:pass# loop with callback to print_eventb["events"].open_perf_buffer(print_event)while 1:try:b.perf_buffer_poll()except KeyboardInterrupt:exit()注意:
A)一个 tracepoint 定义接收两个参数,TRACEPOINT_PROBE(syscalls, sys_enter_execve) 第一个为子系统名称,第二个为事件名称。
B)tracepoint 中的所有参数都会包含在一个固定名称的 args 的结构体中。args 类型为 struct tracepoint__syscalls__sys_enter_open,其第一个字段为 u64 __do_not_use__;,该字段为 ctx 的保留位置。因此,args 可以被强制转换为 ctx。
ctx是啥?在《Linux 内核观测技术 BPF》一书中,
ctx被称为“上下文”,提供了访问内核正在处理的信息。我们可以通过PT_REGS_RC(ctx)来获取当前函数的返回值。
C)用户态代码不再需要 attach_kprobe 手动绑定。
3 eBPF 程序事件类型
像是 kprobe、tracepoint 将 eBPF 程序挂载到内核事件的方式,可以暂且被称为 eBPF 事件类型。事实上,除了以上列出的两种,eBPF 事件类型还有很多,选取其中一些列举如下:
kprobes/kretprobes:内核函数事件。不再赘述。tracepoint:内核跟踪点事件。不再赘述。uprobes/uretprobes:用户空间函数事件,可以绑定监听一个用户空间的函数。USDT probes:用户自定义的静态追踪点。用户可以在用户空间的程序中插入静态追踪点,用于挂载 eBPF。LSM Probes:LSM Hook 挂载点。需要内核版本 5.7 以上。
由于篇幅限制,不再列举其他 eBPF 事件类型了,后面如果有精力,再补一篇文章。
4 总结
本文在前一篇文章的基础上,对进程执行监控工具(execsnoop)进行了升级,实时打印进程执行时传入的参数列表;并通过 kprobe 和 tracepoint 两种方式,绑定 eBPF 程序,给出了代码实现。同时,对这两种 eBPF 事件类型进行了简单比较。显然,在你手动开发一个 eBPF 程序时,建议使用 tracepoint,以追求更好的稳定性和可移植性。文章的最后,简单列出了一些支持的 eBPF 事件类型。
以上抛砖引玉,如有不正确指出,请大家及时斧正。如果你喜欢这篇文章,请点个推荐吧!