1 幂律分布和指数分布
我们在博客中《图数据挖掘(二):网络的常见度量属性 》提到,节点度分布\(p(k)\)为关于\(k\)的函数,表示网络中度为\(k\)的节点占多大比例。我们发现,现实世界许多网络的节点度分布与幂函数乘正比:
\[p(k) \propto k^{-\alpha}\]
比如下图就是对Flick社交网络中\(p(k)\)的概率分布图像的可视化:
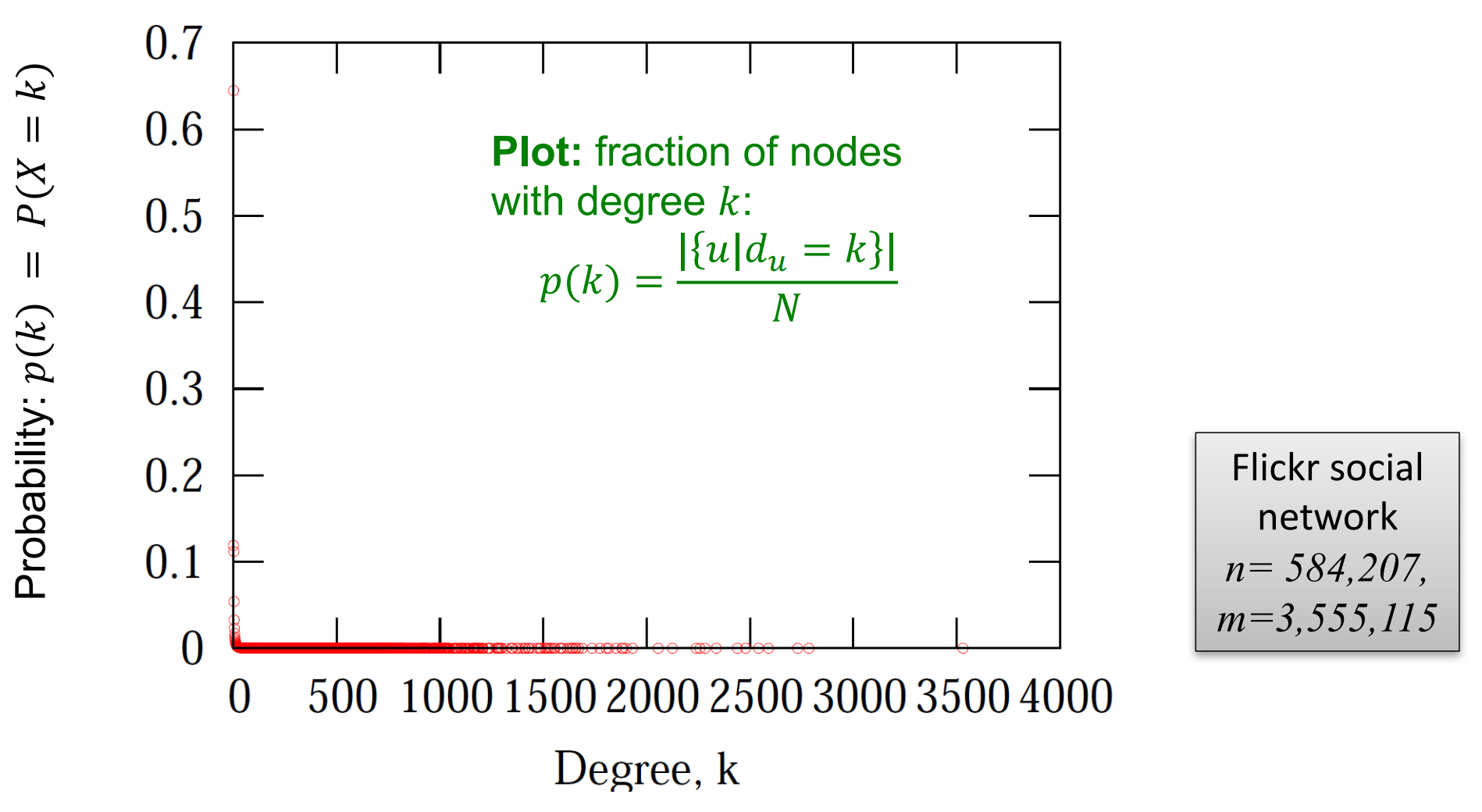
由于对\(y=x^{-\alpha}\)两边取对数可以得到\(\log(y)=-\alpha \log(x)\),因此我们使用原数据在log-log尺度上绘制图像得到:

可以看到此时幂律分布像一条斜率为\(-\alpha\)的直线。事实上,我们可以用该方法快速检测一个数据集是否服从幂律分布。像与幂律分布\(p(k) \propto \exp (-k)\)和指数分布\(p(k) \propto k^{-\alpha}\)就可以使用取对数的方法进行区分,因为对\(y=f(x)=e^{-x}\)两边取对数我们得到的是\(\log(y)=-x\)。
我们继续看在原始坐标轴下,幂律分布和指数分布的对比图:

可以看到,当\(x\)值高于某个特定的值后,幂律分布图像会高于指数分布。如果我们在log-log或者半log(log-lin)尺度上绘制图像则可以看到
我们再来看一下现实生活中的幂律分布和其它分布的对比。事实上,航空网络的度分布常常满足幂律分布;而高速公路网络的度分布则常常满足泊松分布(指数族分布的一种),其均值为平均度\(\bar{k}\)。它们的对比如下图所示:
 2 幂律分布的数学性质2.1 重尾分布
2 幂律分布的数学性质2.1 重尾分布
如果分布\(p(x)\)对应的互补累计分布函数(complementary cumulative distribution function,CCDF)\(P(X>x)\)满足:
\[\lim _{x \rightarrow \infty} \frac{P(X>x)}{e^{-\lambda x}}=\infty\]
则我们称分布\(p(x)\)是重尾分布(heavy tailed distribution)。

幂律分布就是一种典型的重尾分布(就像我们前面所展示的节点度高度倾斜)。但需要注意的事,以下分布不是重尾分布:
- 正态分布:\(p(x)=\frac{1}{\sqrt{2 \pi \sigma}} e^{-\frac{(x-\mu)^2}{2 \sigma^2}}\)
- 指数分布:\(p(x)=\lambda e^{-\lambda x}\)(\(P(X>x)=1-P(X \leq x)=e^{-\lambda x}\))。
事实上,重尾分布有着不同的变种和形式,包括:长尾分布(long tailed distribution),齐夫定律(Zipf’s law),帕累托定律(Pareto law,也就是所谓的“二八法则”)等。
对于重尾分布而言,其概率密度函数\(p(x)\)正比于:
- 幂律分布: \(p(x) \propto x^{-\alpha}\)
- 具有指数截止的幂律分布(power law with exponential cutoff):\(x^{-\alpha} e^{-\lambda x}\)
- 扩展指数分布(stretched exponential):\(x^{\beta-1} e^{-\lambda x^\beta}\)
- 对数正态分布(log-normal):\(\frac{1}{x} \exp \left[-\frac{(\ln x-\mu)^2}{2 \sigma^2}\right]\)
2.2 归一化常数
接下来我们考虑幂律分布
\[p(x)=Z x^{-\alpha}\]
的归一化常数\(Z\)应该怎么取。由于要让\(p(x)\)是一个概率分布的话则需要满足:\(\int p(x) d x=1\)。由于\(p(x)\)在\(x \rightarrow 0\)的时候是发散的,我们取一个最小值\(x_m\),接着我们有:
\[\begin{aligned}&1=\int_{x_m}^{\infty} p(x) d x=Z \int_{x_m}^{\infty} x^{-\alpha} d x \\&=-\frac{Z}{\alpha-1}\left[x^{-\alpha+1}\right]_{x_m}^{\infty}=-\frac{Z}{\alpha-1}\left[\infty^{1-\alpha}-x_m^{1-\alpha}\right]\end{aligned}\]
当\(\alpha>1\)时,我们有\(Z=(\alpha-1) x_m^{\alpha-1}\)。于是,可以得到归一化后的幂律分布形式:
\[p(x)=\frac{\alpha-1}{x_m}\left(\frac{x}{x_m}\right)^{-\alpha}\]2.3 数学期望
幂律分布随机变量\(X\)的期望值
\[\begin{aligned}&E[X]=\int_{x_m}^{\infty} x p(x) d x=Z \int_{x_m}^{\infty} x^{-\alpha+1} d x \\&=\frac{Z}{2-\alpha}\left[x^{2-\alpha}\right]_{x_m}^{\infty}=\frac{(\alpha-1) x_m^{\alpha-1}}{-(\alpha-2)}\left[\infty^{2-\alpha}-x_m^{2-\alpha}\right]\end{aligned}\]
当\(\alpha>2\)时,我们有
\[E[X]=\frac{\alpha-1}{\alpha-2} x_m\]
若\(\alpha \leq 2\),则\(E[X]=\infty\),若\(\alpha\leq3\),则\(Var[X]=\infty\)。事实上当方差太大时均值就没有意义了。
在真实的网络中\(2<\alpha<3\),所以\(E[X]=\text{const}\),\(Var[X]=\infty\)。
为了印证我们上面的理论,我们通过实验模拟当幂律分布的指数\(\alpha\)的取不同值时,从分布中所采的\(n\)个样本的均值和方差随着\(n\rightarrow \infty\)的变化情况:

可以看到,和我们上面的理论符合。
3 无标度网络3.1 随机和无标度网络的对比
网络度分布遵循幂律分布的网络我们称为无标度(scale-free)网络(也称无尺度网络)。所谓无标度(Scale-Free),其实来源于统计物理学里的相转移理。网络一阶矩是平均度,二阶矩是度的方差。我们在博客《图数据挖掘:Erdos-Renyi随机图的生成方式及其特性》中说过,ER随机网络的平均度\(\bar{k}\)与度方差\(\sigma^2\)都是可以估计的,这就是所谓“有尺度”。但正如我们前面所分析的,在幂律分布网络中,方差和期望都可能不存在,这也是Barabási等人将其称为“无尺度”的原因[2][3]。
我们下面展示了随机网络(Erdos-Eenyi随机图)和无标度网络的对比:
 3.2 网络的弹性
3.2 网络的弹性
网络的弹性(resilience)意为网络对攻击的抵抗能力,而这可以通过网络的一些度量属性随攻击的变化来体现。
节点的移除方式包括两种:
- 随机事故(random failure): 均匀随机地移除节点
- 针对性攻击(targeted attack): 按照度的降序来移除节点。

网络的弹性分析对互联网的鲁棒性和流行病学都非常重要。接下来我们就来看几种经典网络类型的弹性分析实验。我们采取的度量属性包括:
- 在巨大连通分量(gaint connected component)中的节点所占的比例
- 最大连通分量中的节点之间的平均路径长度。
可以看到,无标度网络对随机攻击具有弹性,但是对针对性攻击敏感:

接下来的实验展示了对于无标度网络而言,如需让巨连通分量\(S\)消失,有多大比例的随机节点必须要被移除。

\(\gamma<3\)的无限大的无标度网络在随机攻击下永远不会被解体。
下面是无标度网络和随机网络的平均路径长度在针对性攻击和随机攻击下的变化图:

可见无标度网络对于随机事故是有弹性的,而\(G_{np}\)对于针对性攻击有着更好的弹性。
在现实网络中的弹性试验情况如下图所示(来源于[5]):
对上述图像进行放大的结果如下图所示,图中E是指\(G_{np}\)而SF是指scale-free,横坐标表示百分之多少的节点被移除。这里我们可以看到针对性攻击是怎样快速地让网络变得不连通的。
 3.3 优先连接模型和富者更富现象
3.3 优先连接模型和富者更富现象
最后,我们来看幂律分布形成的原因。而这需要从整个网络的形成过程来思考。

我们设节点以顺序\(1,2,\cdots, n\)到达。在第\(j\)步,一个新的节点\(j\)到达了并创建了\(m\)个出链接(out-links),则节点\(j\)链接到之前的节点\(i\)(\(i<j\))的概率正比于\(i\)的度\(d_i\):
\[P(j \rightarrow i)=\frac{d_i}{\sum_k d_k}\]
这被称之为择优链接模型(Preferentialattachment)[3],或富者更富现象,就是指新来的节点更倾向于去链接度已经很高的节点。而幂律就是从“富者更富”(累计优势)中产生。现实中中常见的例子就是在论文引用中,论文新增的引用量和它已经有的引用量成正比(博客文章的点赞也是这个道理,所以如果你看到我这篇文章赞同量很少,不要犹豫帮我点个赞啦o(╥﹏╥)o)。
为了推导幂律分布的形式,我们分析下列模型:节点以顺序\(1,2,3\cdots,n\)到达。当节点\(j\)被创建时它用一个链接指向一个更早的节点\(i\),节点\(i\)是按以下规则选择的:
- \(j\)以概率\(p\)从更早的节点中均匀随机选择\(i\)。
- \(j\)以概率\(1-p\)链接到节点\(l\),其中\(l\)被选择的概率正比于\(d_l\)(\(l\)的入度)。

注意,因为我们的图是有向图,每个节点的出度都为\(1\)。
则在我们上述模型产生的网络中,入度为\(k\)的节点所占的比例满足:
\[P\left(d_i=k\right) \propto k^{-\left(1+\frac{1}{q}\right)}\]
这里\(q=1-p\)。这样,我们就得到了指数\(\alpha=1+\frac{1}{1-p}\)的幂律度分布。
参考
- [1] Broder A, Kumar R, Maghoul F, et al. Graph structure in the web[J]. Computer networks, 2000, 33(1-6): 309-320.
- [2] wiki:无标度网络
- [3] Barabási A L, Albert R. Emergence of scaling in random networks[J]. science, 1999, 286(5439): 509-512.
- [4] Albert R, Jeong H, Barabási A L. Error and attack tolerance of complex networks[J]. nature, 2000, 406(6794): 378-382.
- [5] http://web.stanford.edu/class/cs224w/
- [6] Easley D, Kleinberg J. Networks, crowds, and markets: Reasoning about a highly connected world[M]. Cambridge university press, 2010.
- [7] Barabási A L. Network science[J]. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 2013, 371(1987): 20120375.
数学是符号的艺术,音乐是上界的语言。