作者:周可强
一、责任链模式简介1、责任链模式定义
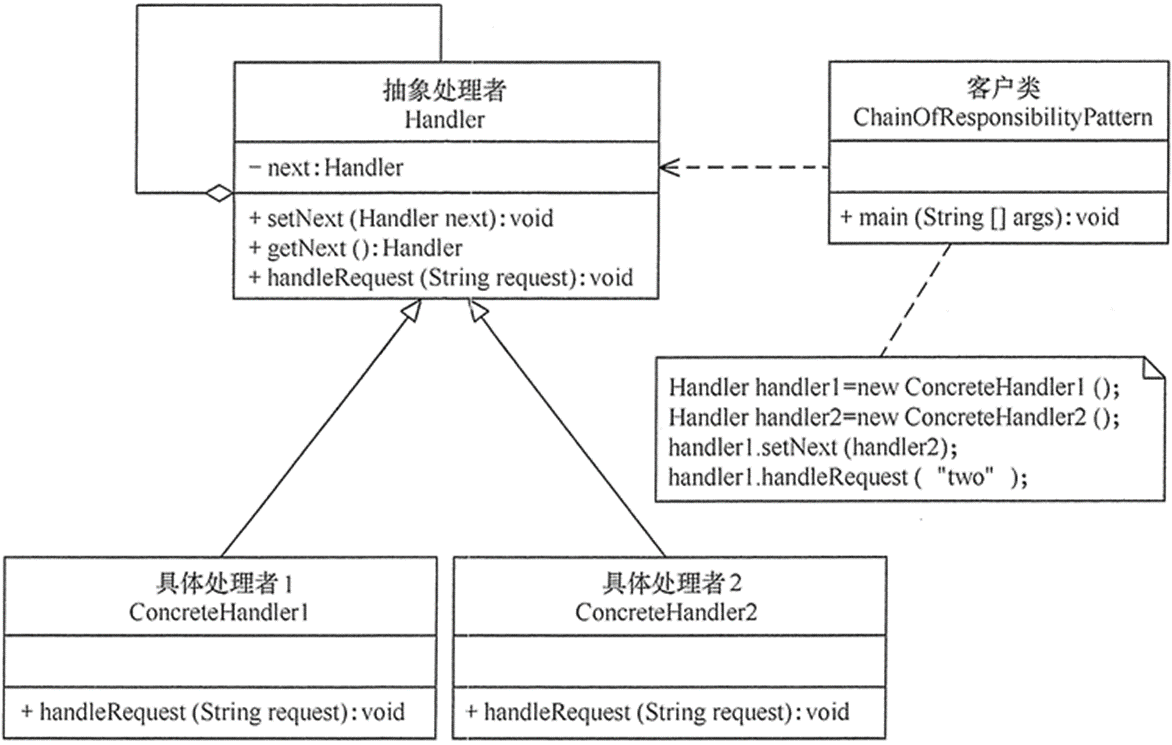
责任链(Chain of Responsibility)模式的定义:为了避免请求发送者与多个请求处理者耦合在一起,于是将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止。在责任链模式中,客户只需要将请求发送到责任链上即可,无须关心请求的处理细节和请求的传递过程,请求会自动进行传递。所以责任链将请求的发送者和请求的处理者解耦了。
2、责任链特点
责任链模式是一种对象行为型模式,
其主要优点如下。
1).降低了对象之间的耦合度。该模式使得一个对象无须知道到底是哪一个对象处理其请求以及链的结构,发送者和接收者也无须拥有对方的明确信息。
2).增强了系统的可扩展性。可以根据需要增加新的请求处理类,满足开闭原则。
3).增强了给对象指派职责的灵活性。当工作流程发生变化,可以动态地改变链内的成员或者调动它们的次序,也可动态地新增或者删除责任。责任链简化了对象之间的连接。每个对象只需保持一个指向其后继者的引用,不需保持其他所有处理者的引用,这避免了使用众多的 if 或者 if···else 语句。
4).责任分担。每个类只需要处理自己该处理的工作,不该处理的传递给下一个对象完成,明确各类的责任范围,符合类的单一职责原则。
其主要缺点如下。
1).不能保证每个请求一定被处理。由于一个请求没有明确的接收者,所以不能保证它一定会被处理,该请求可能一直传到链的末端都得不到处理。
2).对比较长的职责链,请求的处理可能涉及多个处理对象,系统性能将受到一定影响。
3).职责链建立的合理性要靠客户端来保证,增加了客户端的复杂性,可能会由于职责链的错误设置而导致系统出错,如可能会造成循环调用。
3、责任链结构图

二、Dubbo中的责任链模式1、过滤器日志
通过打印过滤器的日志,我们可以看到在发布服务的过程中,会依次经过dubbo的每个过滤器类,以此来保证服务的完善。
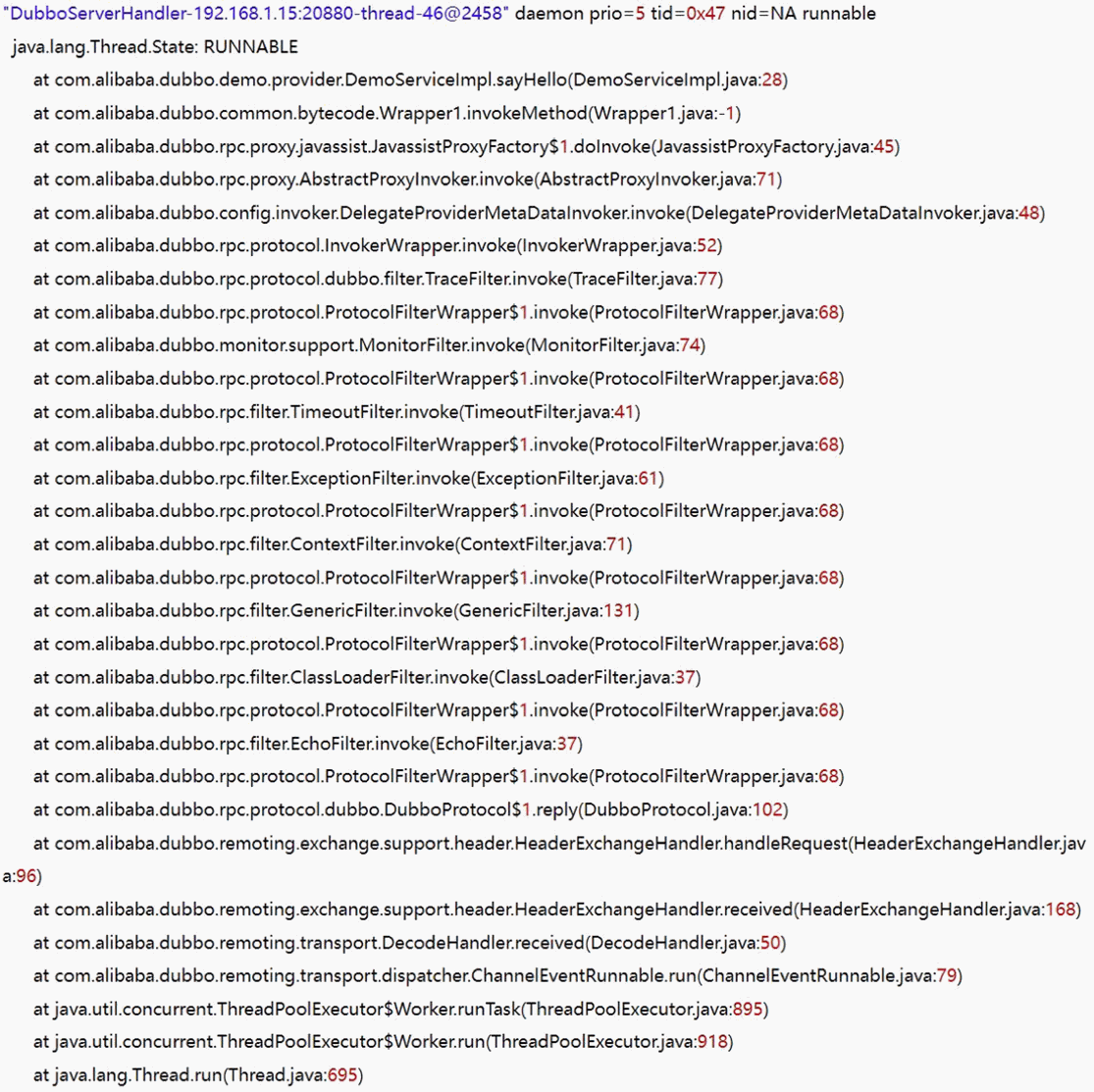
2、过滤器简图
dubbo通过将每个过滤器类filter封装成dubbo的核心模型invoker进行组装,最终形成晚上的过滤器责任链filterChain。

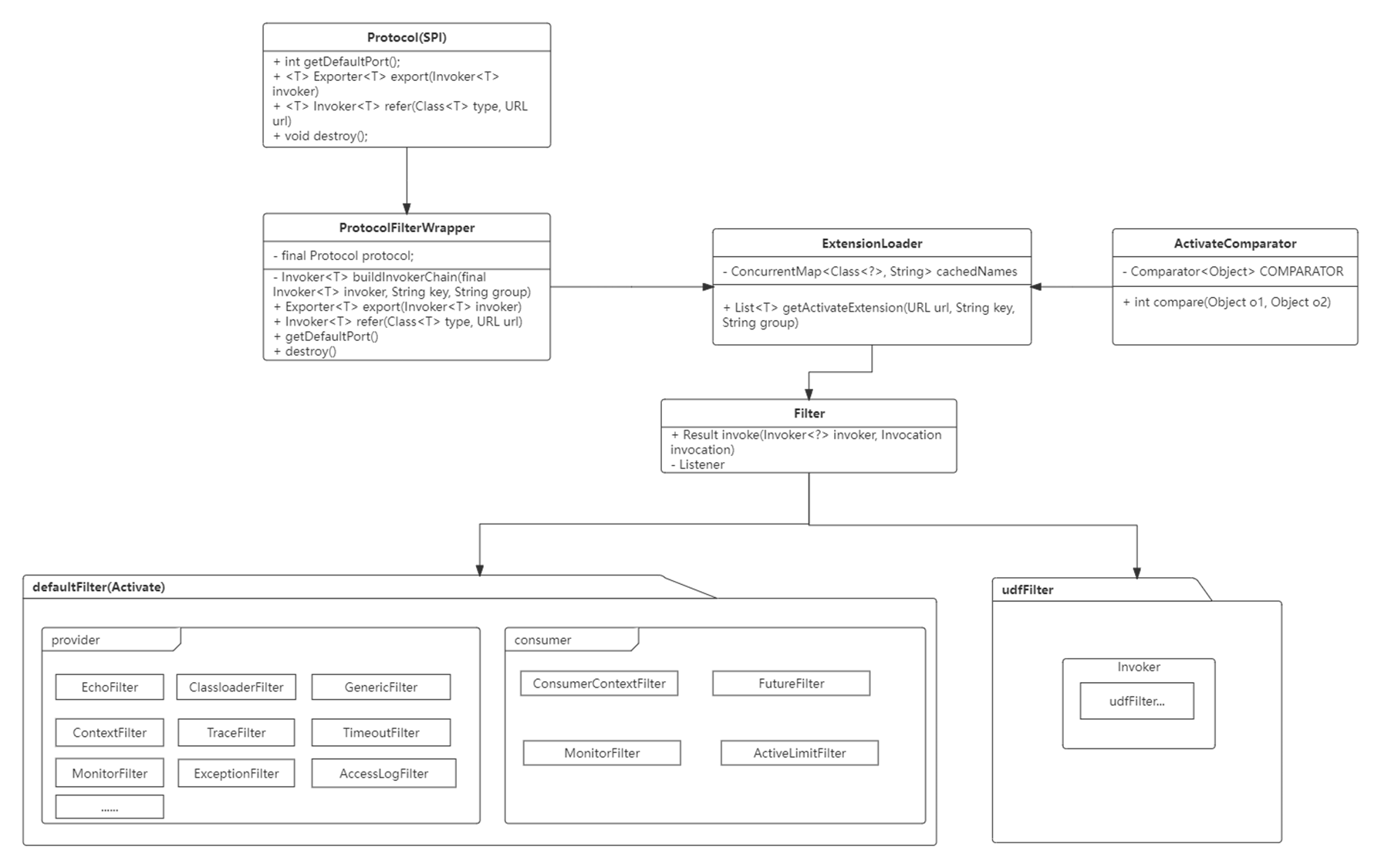
3、过滤器类图
Protocol是核心模型invoker暴露和引用的主功能入口,采用SPI的接口,他的两个方法export和refer分别对应provider和consumer端的服务功能,ProtocolFilterWapper则是Dubbo的过滤器的主要实现类,通过重写的export和refer指向buildInvokerChain方法,在buildInvokerChain中进行责任链的获取与组装,在extensionLoader中通过SPI获取Filter的各实现类,并通过ActivateComparator进行排序,最终形成完整的责任链。
三、Dubbo中各Filter责任介绍1、provider用到的filter
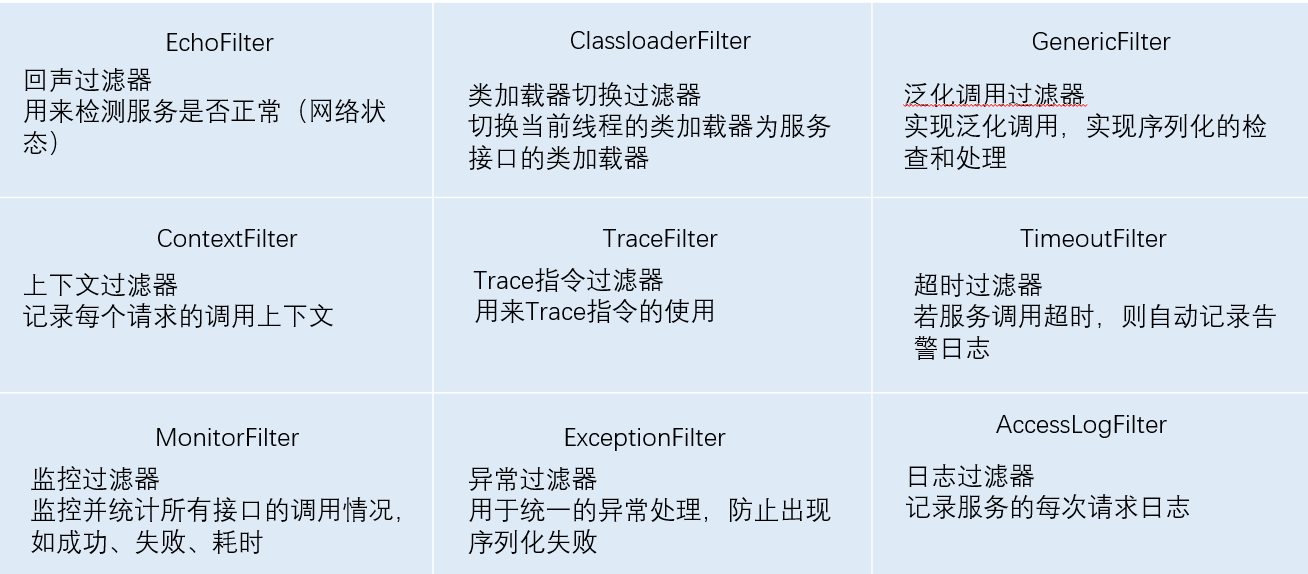
2、consumer用到的filter

四、源码探析
进入到核心类ProtocolFilterWrapper中,在实现类中export和refer,都采用相同的构造责任链方法buildInvokerChain,只是通过参数group进行区分

在buildInvokerChain中,通过getActivateExtension获取过滤器数组,并在之后封装成核心模型invoker并组装成责任链
private static Invoker buildInvokerChain(final Invoker invoker, String key, String group) { Invoker last = invoker; // 获得过滤器数组 (已经排好序的) List filters = ExtensionLoader.getExtensionLoader(Filter.class).getActivateExtension(invoker.getUrl(), key, group); // 创建带 Filter 链的 Invoker 对象 if (!filters.isEmpty()) { for (int i = filters.size() - 1; i >= 0; i--) { final Filter filter = filters.get(i); final Invoker next = last; last = new Invoker() { @Override public Class getInterface() { return invoker.getInterface(); } @Override public URL getUrl() { return invoker.getUrl(); } @Override public boolean isAvailable() { return invoker.isAvailable(); } @Override public Result invoke(Invocation invocation) throws RpcException { return filter.invoke(next, invocation); } @Override public void destroy() { invoker.destroy(); } @Override public String toString() { return invoker.toString(); } }; } } System.out.println("group:" + group); for (Filter filter : filters) { System.out.println(filter.getClass()); } return last; }getActivateExtension是主要的组装逻辑,他包含获取与排序等逻辑
首先进行判断是否采用系统默认的Filter过滤器,并对每一个系统过滤器进行校验是否移除,然后对系统过滤器排序,再通过指定的参数,增加用户自定义的过滤器组装责任链
public List getActivateExtension(URL url, String key, String group) { // 从 Dubbo URL 获得参数值 String value = url.getParameter(key); // 获得符合自动激活条件的拓展对象数组 return getActivateExtension(url, value == null || value.length() == 0 ? null : Constants.COMMA_SPLIT_PATTERN.split(value), group); }public List getActivateExtension(URL url, String[] values, String group) { List exts = new ArrayList(); //所有用户自己配置的filter信息(有些Filter是默认激活的,有些是配置激活的,这里的names就指的配置激活的filter信息) List names = values == null ? new ArrayList(0) : Arrays.asList(values); // 处理自动激活的拓展对象们 // 判断不存在配置 `"-name"` 。例如, ,代表移除所有默认过滤器。 if (!names.contains(Constants.REMOVE_VALUE_PREFIX + Constants.DEFAULT_KEY)) { // 获得拓展实现类数组 getExtensionClasses(); // 循环 for (Map.Entry entry : cachedActivates.entrySet()) { //name指的是SPI读取的配置文件的key String name = entry.getKey(); Activate activate = entry.getValue(); if (isMatchGroup(group, activate.group())) { // 匹配分组 // 获得拓展对象 T ext = getExtension(name); if (!names.contains(name) // 不包含在自定义配置里。如果包含,会在下面的代码处理。 && !names.contains(Constants.REMOVE_VALUE_PREFIX + name) // 判断是否配置移除。例如 ,则 MonitorFilter 会被移除 && isActive(activate, url)) { // 判断是否激活 exts.add(ext); } } } // 排序 Collections.sort(exts, ActivateComparator.COMPARATOR); } // 处理自定义配置的拓展对象们。例如在 ,代表需要加入 DemoFilter List usrs = new ArrayList(); for (int i = 0; i < names.size(); i++) { String name = names.get(i); if (!name.startsWith(Constants.REMOVE_VALUE_PREFIX) && !names.contains(Constants.REMOVE_VALUE_PREFIX + name)) { // 判断非移除的 // 将配置的自定义在自动激活的拓展对象们前面。例如, ,则 DemoFilter 就会放在默认的过滤器前面。 if (Constants.DEFAULT_KEY.equals(name)) { if (!usrs.isEmpty()) { exts.addAll(0, usrs); usrs.clear(); } } else { // 获得拓展对象 T ext = getExtension(name); usrs.add(ext); } } } // 添加到结果集 if (!usrs.isEmpty()) { exts.addAll(usrs); } return exts; }系统默认的过滤器和udf过滤器进行区分
以ContextFilter为例,系统默认过滤器包含Activate注解,用于指定所属分组与排序权重,用户自己实现的过滤器则不能添加Activate注解通过发布时指定所需的过滤器

我们看下具体的排序比较方法,首先判断Activate注解是否指定before和after参数用来指定排序,若不存在则采用order权重进行排序
ActivateComparator.classpublic int compare(Object o1, Object o2) { // 基本排序 if (o1 == null && o2 == null) { return 0; } if (o1 == null) { return -1; } if (o2 == null) { return 1; } if (o1.equals(o2)) { return 0; } Activate a1 = o1.getClass().getAnnotation(Activate.class); Activate a2 = o2.getClass().getAnnotation(Activate.class); // 使用注解的 `after` 和 `before` 属性,排序 if ((a1.before().length > 0 || a1.after().length > 0 || a2.before().length > 0 || a2.after().length > 0) // (a1 或 a2) 存在 (`after` 或 `before`) 属性。 && o1.getClass().getInterfaces().length > 0 && o1.getClass().getInterfaces()[0].isAnnotationPresent(SPI.class)) { // 实现的接口,有 @SPI 注解。 // 获得拓展加载器 ExtensionLoader extensionLoader = ExtensionLoader.getExtensionLoader(o1.getClass().getInterfaces()[0]); // 以 a1 的视角,进行一次比较 if (a1.before().length > 0 || a1.after().length > 0) { String n2 = extensionLoader.getExtensionName(o2.getClass()); for (String before : a1.before()) { if (before.equals(n2)) { return -1; } } for (String after : a1.after()) { if (after.equals(n2)) { return 1; } } } // 以 a2 的视角,进行一次比较。 if (a2.before().length > 0 || a2.after().length > 0) { String n1 = extensionLoader.getExtensionName(o1.getClass()); for (String before : a2.before()) { if (before.equals(n1)) { return 1; } } for (String after : a2.after()) { if (after.equals(n1)) { return -1; } } } } // 使用注解的 `order` 属性,排序。 int n1 = a1 == null ? 0 : a1.order(); int n2 = a2 == null ? 0 : a2.order(); // never return 0 even if n1 equals n2, otherwise, o1 and o2 will override each other in collection like HashSet return n1 > n2 ? 1 : -1; }总结:
责任链模式是设计模式中简单且常见的设计模式,可能我们日常中也会经常应用责任链模式,dubbo中的责任链模式将灵活性发挥的很充分,不论是从分组概念、通过注解指定排序的优先级、每个filter的是否移除 等,将每个filter做成了可插拔的,减少对代码的侵入性,这点是非常值得我们学习的。