目录
- 什么是RabbitMQ?
- 为什么使用MQ?MQ的优点
- 消息中间件比对
- RabbitMQ
- RocketMQ
- Kafka
- 选型建议
- MQ 有哪些常见问题?ranbbitMQ如何解决这些问题?
- MQ 有哪些常见问题?
- 消息的顺序问题
- 消息的重复问题
- 消息积压
- rabbitMQ如何解决这些问题?
- rabbitMQ解决消息的顺序方案
- rabbitMQ解决消息的重复问题方案
- rabbitMQ解决消息积压方案
- RabbitMQ消息的可靠传输?消息丢失怎么办?
- 生产者的消息确认机制
- 消费者的消息确认机制
- 消息队列的持久化
- RabbitMQ高可用
- MQ 有哪些常见问题?
什么是RabbitMQ?
RabbitMQ是一款开源的,Erlang编写的,基于AMQP协议的消息中间件
为什么使用MQ?MQ的优点
异步处理 – 相比于传统的串行、并行方式,提高了系统的吞吐量。
应用解耦 – 系统间通过消息通信,不用关心其他系统的处理。
流量削锋 – 可以通过消息队列长度控制请求量,可以缓解短时间内的高并发请求。
消息通讯 – 消息队列一般都内置了高效的通信机制,因此也可以用在纯消息通讯上。比如实现点对点消息队列,或者聊天室等。
日志处理 – 解决大量日志传输。
消息中间件比对
ActiveMQ、RabbitMQ、RocketMQ、Kafka有什么优缺点?
| ActiveMQ | RabbitMQ | RocketMQ | Kafka | ZeroMQ | |
|---|---|---|---|---|---|
| 单机吞吐量 | 比RabbitMQ低 | 2.6w/s(消息做持久化) | 11.6w/s | 17.3w/s | 29w/s |
| 开发语言 | Java | Erlang | Java | Scala/Java | C |
| 主要维护者 | Apache | Mozilla/Spring | Alibaba | Apache | iMatix,创始人已去世 |
| 成熟度 | 成熟 | 成熟 | 开源版本不够成熟 | 比较成熟 | 只有C、PHP等版本成熟 |
| 订阅形式 | 点对点(p2p)、广播(发布-订阅) | 提供了4种:direct, topic ,Headers和fanout。fanout就是广播模式 | 基于topic/messageTag以及按照消息类型、属性进行正则匹配的发布订阅模式 | 基于topic以及按照topic进行正则匹配的发布订阅模式 | 点对点(p2p) |
| 持久化 | 支持少量堆积 | 支持少量堆积 | 支持大量堆积 | 支持大量堆积 | 不支持 |
| 顺序消息 | 不支持 | 不支持 | 支持 | 支持 | 不支持 |
| 性能稳定性 | 好 | 好 | 一般 | 较差 | 很好 |
| 集群方式 | 支持简单集群模式,比如’主-备’,对高级集群模式支持不好。 | 支持简单集群,’复制’模式,对高级集群模式支持不好。 | 常用 多对’Master-Slave’ 模式,开源版本需手动切换Slave变成Master | 天然的‘Leader-Slave’无状态集群,每台服务器既是Master也是Slave | 不支持 |
| 管理界面 | 一般 | 较好 | 一般 | 无 | 无 |
RabbitMQ
可以支撑高并发、高吞吐量、性能很高,同时有非常完善便捷的后台管理界面可以使用。
另外,他还支持集群化、高可用部署架构、消息高可靠支持,功能较为完善。
RabbitMQ的开源社区很活跃,较高频率的版本迭代,来修复发现的bug以及进行各种优化,因此综合考虑过后,公司采取了RabbitMQ。
RabbitMQ也有一点缺陷,就是他自身是基于erlang语言开发的,所以导致较为难以分析里面的源码,也较难进行深层次的源码定制和改造,需要较为扎实的erlang语言功底。
RocketMQ
开源的,经过阿里生产环境的超高并发、高吞吐的考验,性能卓越,同时还支持分布式事务等特殊场景。
RocketMQ是基于Java语言开发的,适合深入阅读源码,有需要可以站在源码层面解决线上问题,包括源码的二次开发和改造。
Kafka
Kafka提供的消息中间件的功能明显较少一些,相对上述几款MQ中间件要少很多。
Kafka的优势在于专为超高吞吐量的实时日志采集、实时数据同步、实时数据计算等场景。
Kafka在大数据领域中配合实时计算技术(比如Spark Streaming、Storm、Flink)使用的较多。但是在传统的MQ中间件使用场景中较少采用。
选型建议
RabbitMQ, erlang 语言阻止了大量的 Java 工程师去深入研究和掌控它,对公司而言,几乎处于不可控的状态,但是确实人家是开源的,比较稳定的支持,活跃度也高;
RocketMQ, 越来越多的公司会去用 RocketMQ,确实很不错,毕竟是阿里出品,但社区可能有突然黄掉的风险(目前 RocketMQ 已捐给 Apache,但 GitHub 上的活跃度其实不算高)对自己公司技术实力有绝对自信的,推荐用 RocketMQ
中小型公司,技术实力较为一般,技术挑战不是特别高,用 RabbitMQ 是不错的选择;大型公司,基础架构研发实力较强,用 RocketMQ 是很好的选择
如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范
MQ 有哪些常见问题?ranbbitMQ如何解决这些问题?MQ 有哪些常见问题?消息的顺序问题
消息有序指的是可以按照消息的发送顺序来消费。
假如生产者产生了 2 条消息:M1、M2,假定 M1 发送到 S1,M2 发送到 S2,要保证 M1 先于 M2 被消费顺序。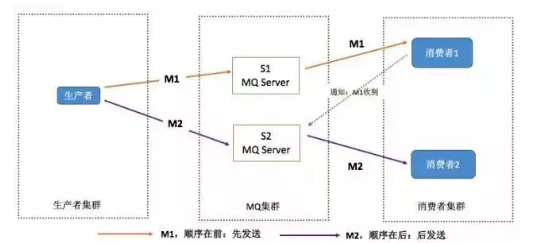
消息的重复问题
造成消息重复的常见原因是:网络不可达,重试机制造成。
所以解决这个问题的办法就是绕过这个问题。那么问题就变成了:如果消费端收到两条一样的消息,应该怎样处理?
消息积压
由于消费者速率远低于生产者,或者是消费者宕机,消息中间件中有大量消息积压到队列中
rabbitMQ如何解决这些问题?rabbitMQ解决消息的顺序方案
RabbitMQ:拆分多个 queue,每个 queue 一个 consumer,就是多一些 queue 而已,确实是麻烦点;或者就一个 queue 但是对应一个 consumer,然后这个 consumer 内部用内存队列做排队,然后分发给底层不同的 worker 来处理。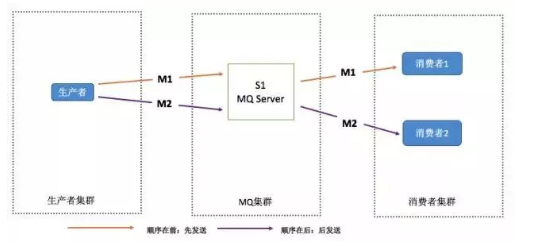
缺陷:
并行度就会成为消息系统的瓶颈(吞吐量不够)
更多的异常处理,比如:只要消费端出现问题,就会导致整个处理流程阻塞,我们不得不花费更多的精力来解决阻塞的问题。通过合理的设计或者将问题分解来规避。
不关注顺序的应用实际大量存在
队列无序并不意味着消息无序,所以从业务层面来保证消息的顺序而不仅仅是依赖于消息系统,是一种更合理的方式。
其他解决方案
方案一:消费端使用redis存储消息记录表,通过redis锁,控制消费者按照顺序消费。
方案三:采用RocketMQ顺序消费机制;(不建议使用,会降低系统吞吐量)
rabbitMQ解决消息的重复问题方案
消费端处理消息的业务逻辑需要保持幂等性。使用redis存储消息id作为日志表,只要保持幂等性,不管来多少条重复消息,最后处理的结果都一样。保证每条消息都有唯一编号和redis添加一张日志表来记录已经处理成功的消息的 ID,如果新到的消息 ID 已经在日志表中,那么就不再处理这条消息。
rabbitMQ解决消息积压方案
出现消息积压的问题,首先要排除掉消费者宕机的问题。其次,再根据监控面板,观察消费者和生产者消费消息及生产消息的速率。
- 生产者速率增加:一般电商系统大促时,比较常见,往往的应对手段是扩容消费端的实例数或服务降级。
- 消费者速率减少:检查一下日志是否有大量的消费错误,或是消费线程卡死或是等待资源锁死。
- 速率无变化:可能是消费失败导致的一条消息反复消费,从而拖慢整个系统的消费速度
RabbitMQ消息的可靠传输?消息丢失怎么办?
RabbitMQ提供了消息确认机制来确保消息的可靠传输
消息消息确认机制包括两部分:生产者到消息中间件,即消息的发布确认。消息中间件到消费者,即消息的消费确认。
生产者的消息确认机制
rabbit的生产者客户端提供了消息发布的回调接口,一旦生产者消息到交换机失败,则会触发回调。同理,交换机到消息队列也有回调接口,一旦交换机向消息队列投递消息失败,则会触发回调。
/** * 消息->交换机 回调函数 * ack:true 发送成功 false: 发送失败 */ private final RabbitTemplate.ConfirmCallback confirmCallback = (correlationData, ack, cause) -> { //可以增加补偿机制if (!ack) { log.error("sendMsg:=======> Msg To Exchange Failed! Cause:{}", cause); } }; /** * 交换机->消息队列 回调函数 * 发送失败:触发returnCallback回调函数 */ private final RabbitTemplate.ReturnCallback returnCallback = (message, replyCode, replyText, exchange, routingKey) -> //可以增加补偿机制 log.error("sendMsg:=======> Exchange To Queue Failed! Message:{} Exchange:{} RoutingKey:{} Replay:{}", message.toString(), exchange, routingKey, replyText);消费者的消息确认机制
rabbitMQ开启手动确认消息,消费端需要收到消息之后,手动ack才可表示消息消费成功。否则可以投递到死信队列或者消息重试。
消息队列的持久化
还有一种常见情况是,我们经常会遇到需要重启中间件,或者是中间件宕机的问题,那么就需要开启消息持久化,否则会发生消息还没来得及消费会丢失的问题。
将queue的持久化标识durable设置为true,则代表是一个持久的队列
发送消息的时候将deliveryMode=2
RabbitMQ高可用
rabbitMQ有三种模式:单机模式、普通集群模式、镜像集群模式
- 单机模式:就是部署一个rabbitMQ实例
- 集群模式:意思就是在多台机器上启动多个 RabbitMQ 实例,每个机器启动一个。你创建的 queue,只会放在一个 RabbitMQ 实例上,但是每个实例都同步 queue 的元数据(元数据可以认为是 queue 的一些配置信息,通过元数据,可以找到 queue 所在实例)。你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个 queue 的读写操作。
- 镜像集群模式:这种模式,才是所谓的 RabbitMQ 的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。这样的话,好处在于,你任何一个机器宕机了,没事儿,其它机器(节点)还包含了这个 queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。坏处在于,第一,这个性能开销也太大了吧,消息需要同步到所有机器上,导致网络带宽压力和消耗很重!RabbitMQ 一个 queue 的数据都是放在一个节点里的,镜像集群下,也是每个节点都放这个 queue 的完整数据。
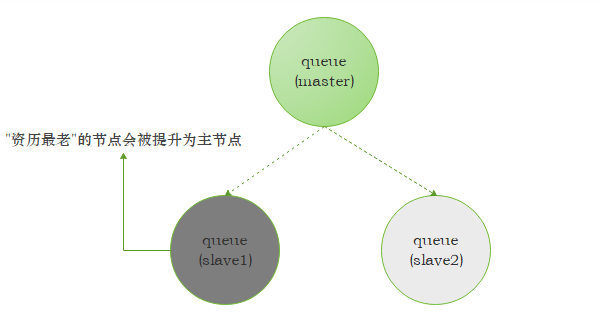
镜像集群节点图
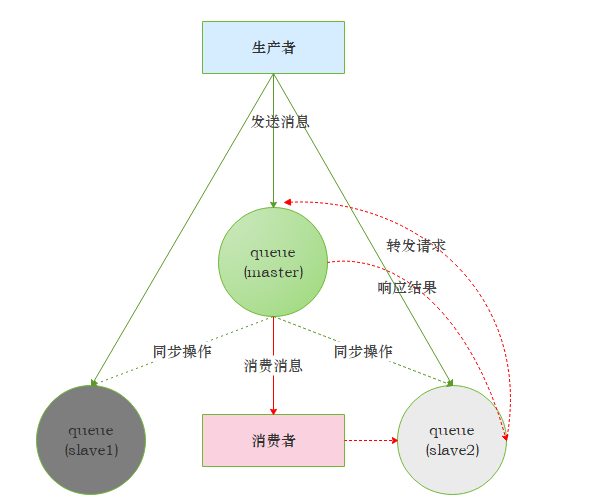
slave 会准确地按照 master 执行命令顺序进行动作,故 slave 和 master 上维护的状态应该也是相同的。如果master 由于某种原因宕机了,那么”资源最老”的slave会被提升为新的master。
根据slave 加入的时间排序,时间最长的 slave 即为”资历最老”。发送到镜像队列的所有的消息会被同时发往 master 和所有的slave,如果此时 master 挂掉了,消息还会在 slave 上,这样 slave 提升为 master 的时候消息也不会丢失
镜像集群工作模式图
除发送消息(Basic.Publish)外的所有动作都只会向 master 发送,然后再由 master 将命令执行的结果广播给各个 slave。如果消费者与 slave 建立连接并进行订阅消息,其实质上都是从 master 上获取消息,只不过看似是从 slave 上消费而已。比如:消费者与 slave 建立了 TCP 连接之后执行一个 Basic.GET 的操作,那么首先是由 slave 将 Basic.GET 请求发往 master,再由 master 准备好数据返回给 slave,最后由 slave投递给消费者。