今日内容概要
- 昨日回顾
- 反序列化类校验部分源码解析(了解)
- 断言
- drf之请求(配置解析类)
- drf之响应(配置响应类,Resposne的源码的属性)
- 视图组件介绍及两个视图基类与五个视图扩展类的用法介绍
.
.
.
.
昨日回顾
# 1 序列化类的常用字段 -CharField 。。。。 -ListField -DictField-------------------------------# 2 字段参数 -max_length。。。 -min_value。。。 -required,default。。。 -read_only,write_only-------------------------------# 3 定制序列化字段(改名字) -source这个字段参数 -如果是表模型自己的字段,直接写 -如果是关联表字段,通过外键.的方式 拿到-------------------------------# 4 定制序列化字段(格式更丰富) -在序列化类中使用:SerializerMethodField,配合一个 get_字段名的方法,方法返回什么,这个字段就是什么----》这种字段以后不能用来,做反序列化了!!! -在表模型中使用,写方法的方式,方法返回什么,这个字段前端显示的就是啥,序列化类中需要配合ListField,DictField----》这种字段以后不能用来,做反序列化了!!! -方法可以包装成数据属性加@property,也可以不加@property-------------------------------# 5 反序列化校验几层 -1 字段自己的校验规则:序列化类字段参数控制的 -2 每个字段单独设置校验方法(了解) -3 局部钩子 -4 全局钩子ser调用is_valid方法的时候,就会将4层校验从上往下依次执行ser调用save方法,触发的是create或者update方法的执行!!-------------------------------# 6 ModelSerializer:继承自Serializer class BookSerializer(ModelSerializer): # 如果字段是映射过来的,也会把字段属性[反序列化校验规则],也会映射过来,有可能会校验失败,不能写入 # 咱们重写这个字段,不加任何规则,取消掉它 name = serializer.CharField() class Meta: model=Author # fields="__all__" # 只要是序列化的字段和反序列化的任何字段,都要在这注册 # 序列化的字段,可能不是表模型的字段,是在表模型中写的方法名# 序列化的字段,也可能是在序列化类里面的,写的定制化字段,SerializerMethodField,也要注册 fields=['name','photo','gender','addr'] extra_kwargs={'name':{'max_length': 8}} # 给字段类增加属性,read_only 和write_only用的多 gender=serializer.CharField() addr=serializer.CharField() # 局部钩子,全局钩子 和原来的用法完全一样 # 在序列化类里面写定制化字段方法的SerializerMethodField的用法和 原来也一样 def create(self, validated_data): pass def update(self, instance, validated_data): pass-------------------------------# 7 反序列化的字段,一定跟表模型的字段是对应的吗? 不一定,随意写。# 因为反序列化的字段,可能是要存到两张表里面去的。注意因为现在BookSerializer类继承了ModelSerializer,前端提交过来的数据包含了两个表里面的数据,但是序列化类只和Book模型表建立了关联只要反序列化,就必须要在fields里面注册一下。但是在将book表里面的字段映射的序列化表里面的时候,是不可能将另一个表里面的字段也映射过来的。所以需要在序列化表里面,把该字段重写一下就行了,如果需要字段校验也一样在括号里面写字段的校验参数,如果需要其他的逻辑校验,就写钩子函数。最后我们需要在序列化类里面要重写create方法,因为ModelSerializer封装了create方法,但是该方法只能适用于前端传的是关联表里面的字段数据,会自动将前端的数据利用ORM写到数据库里面去。但是现在前端传的是两个表里面的数据,所以我们要重写create方法,自己将两个表里面的数据从validated_data里面拿出来,利用ORM分别写到两张表里面去!!!!!!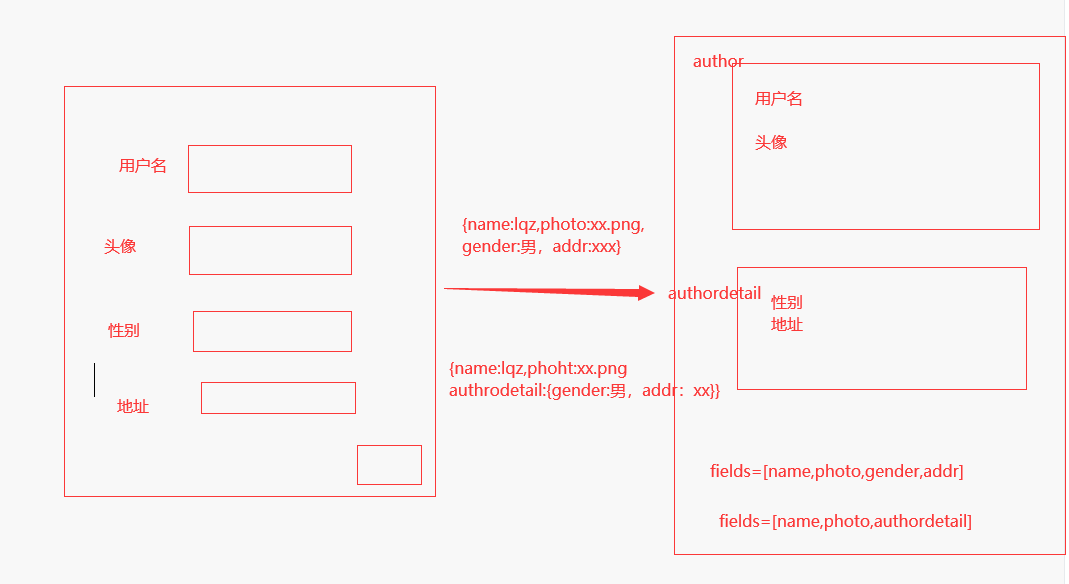
.
.
.
.
.
1 反序列化类校验部分源码解析(了解)
反序列化校验,什么时候开始执行校验?视图类中的调用 ser.is_valid(), 就会执行校验,校验通过返回True,不通过返回False----------------------------------------ser是我们自己写的BookSerializer序列化类的对象入口:ser.is_valid() ------BookSerializer类里面没有is_valid------继续找最终找到了父类-----BaseSerializer中的is_valid注意视图类post函数里面 if ser.is_valid(): 括号里面写raise_exception=True,就会直接抛异常!!---------------------------------------------------------------------------------- def is_valid(self, *, raise_exception=False): if not hasattr(self, '_validated_data'): try: # self序列化类的对象,属性中没有_validated_data,一定会走下面这句【核心】 # 这句走完后,对象就有该属性了,下次对象再点is_valid方法时,下面这句话肯定就不走了 # 所以is_valid被对象调用一次,与被对象调用多次的效果是一样的!,只有第一次的时候会校验 self._validated_data = self.run_validation(self.initial_data) except ValidationError as exc: self._validated_data = {} self._errors = exc.detail else: self._errors = {} if self._errors and raise_exception: raise ValidationError(self.errors) return not bool(self._errors)----------------------------------------------------------------------------------# self._validated_data = self.run_validation(self.initial_data) 这行代码的self是序列化类的对象-切记一定不要按住ctrl键点击名字,因为系统默认是基于当前名字所属的类查找及往上找!!-哪个对象调用的该方法,那么该方法里面self就是哪个对象,和self当前所在的函数所属的类无关!!!-所以真正的查找顺序是,从self所指代的这个对象开始从下往上找,找不到,再往上,知道找到该方法!!!-最终从Serializer类中找到了run_validation,而不是Field中的run_validation !!---------------------------------------------------------------------------------- def run_validation(self, data=empty): # 执行字段自己的,及validates方法,也就是第一层与第二层的校验 (is_empty_value, data) = self.validate_empty_values(data) if is_empty_value: return data # 局部钩子----【局部钩子】 value = self.to_internal_value(data) try: self.run_validators(value) # 全局钩子--》如果在BookSerializer中写了全局钩子validate,优先走它,非常简单 value = self.validate(value) except (ValidationError, DjangoValidationError) as exc: raise ValidationError(detail=as_serializer_error(exc)) return value----------------------------------------------------------------------------------# 局部钩子 self.to_internal_value(data) ---》self是BookSerializer的对象,从根上找# 最后在Serializer类中找到了 def to_internal_value(self, data): ret = OrderedDict() errors = OrderedDict() fields = self._writable_fields # fields 就是写在序列化类中一个个字段类的对象!!! for field in fields: # self 是BookSerializer的对象 # 还是用反射,反射出BookSerializer对象中的局部钩子函数的函数名字 validate_method = getattr(self, 'validate_' + field.field_name, None) try: # 执行BookSerializer类中的钩子函数方法,传入了要校验的数据 validated_value = validate_method(validated_value) except ValidationError as exc: errors[field.field_name] = exc.detail else: set_value(ret, field.source_attrs, validated_value) if errors: raise ValidationError(errors) return ret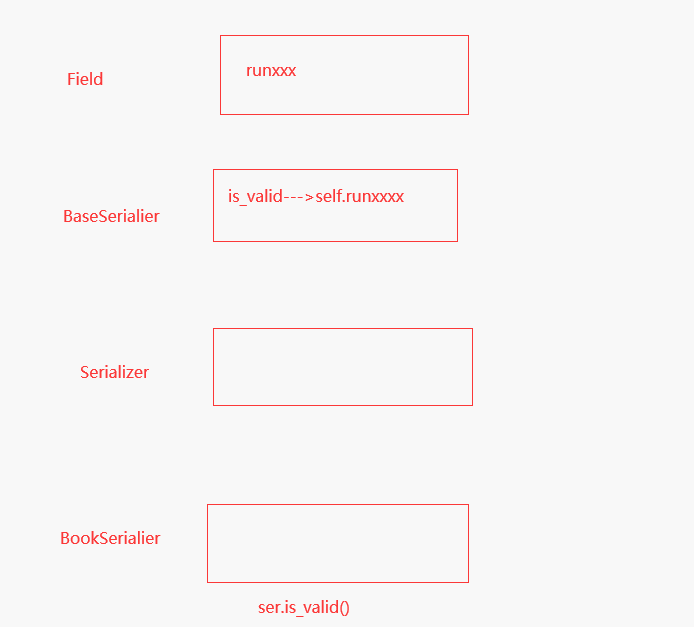
.
.
.
.
2 断言
# 源码中大量使用try和断言# 关键字assert ,有什么作用,断定你是什么,如果是没事,如果不是就抛异常--------------------------------------------name = 'zzz'if name == 'lqz': passelse: raise Exception('名字不为lqz,不能继续走了')print('后续代码')---------------------上面代码可以写成这样name = 'zzz'assert name=='lqz' # 断定是,没问题,代码继续往下走,如果不是,就主动抛异常!!print('后续代码')---------------------------------------------- def is_valid(self, *, raise_exception=False): # 断言对象里面有'initial_data'属性,如果有就继续往下走,如果没有就主动抛异常报错了 assert hasattr(self, 'initial_data') if not hasattr(self, '_validated_data'): try: self._validated_data = self.run_validation(self.initial_data) except ValidationError as exc: self._validated_data = {} self._errors = exc.detail else: self._errors = {}# 判断后面的代码的结果的布尔值,True就正常继续往下走,False就主动抛异常,不让代码往下走了!!! 断言的主要目的就是如果是False,不让代码往下走了--------------------------------------------------.
.
.
.
3 drf之请求3.1 Request能够解析的前端传入的编码格式——-配置解析类
# 需求是该接口只能接收某种编码格式,比如json格式,不能接收其他格式---------------------------------------------方式一,在继承自APIView及其子类的的视图类中配置(局部配置,只对该视图类有效)# 总共有三个:from rest_framework.parsers import JSONParser,FormParser,MultiPartParserclass BookView(APIView): parser_classes = [JSONParser,]# 这样一配置,以后该视图类只能够解析,用json格式编码传入的文件了!!用其他格式编码传入的文件就解析不了了!!!# parser_classes 解析类 意思是能够解析前端传入的上面编码格式(默认情况下配了3个解析类)# drf解析类已经帮我们写好了,我们只需要导入即可!----------------------------------------------方式二:在配置文件中配置(影响所有,全局配置)-django有套默认配置,每个项目也有个配置-drf也有套默认配置,每个项目也有个配置(就是django的配置文件)------------------ REST_FRAMEWORK = { 'DEFAULT_PARSER_CLASSES': [ 'rest_framework.parsers.JSONParser', # 'rest_framework.parsers.FormParser', # 'rest_framework.parsers.MultiPartParser', ],}# 这样在django的配置文件中写一下,假如上面的视图类里面不配置解析类,在这里配置的就对整个django项目生效了!!!------------------------------------------------方式三:全局配了1个解析类,某个视图类想要配3个解析类,怎么配?-只需要在视图类,配置3个即可-因为:先从视图类自身找,找不到,再去项目的drf配置(django项目配置)中找,再找不到,去drf默认的配置找如果是json格式编码,request.data就是普通dict
.
如果urlencoded,或form-data编码,就是querydict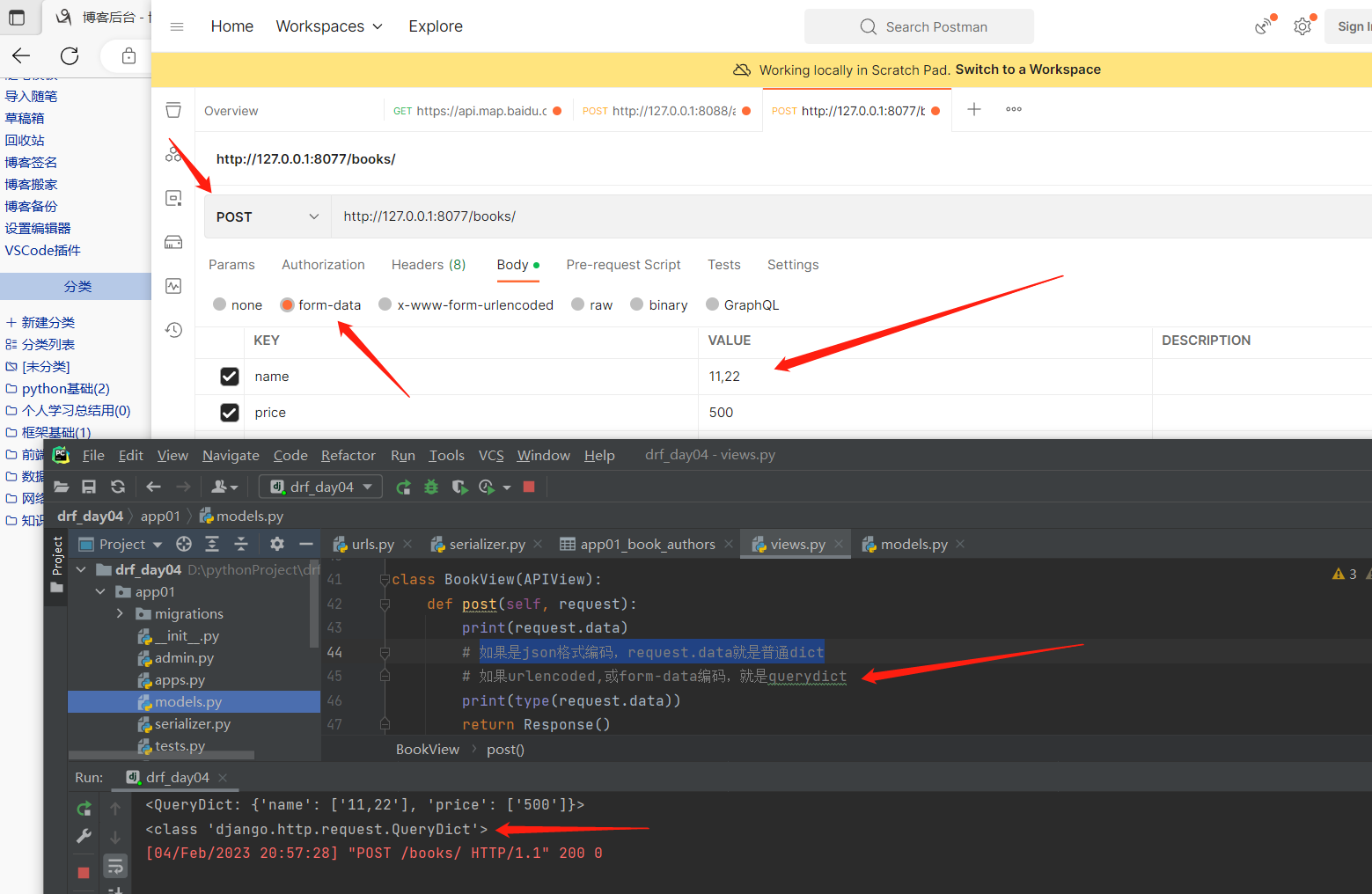
.
.
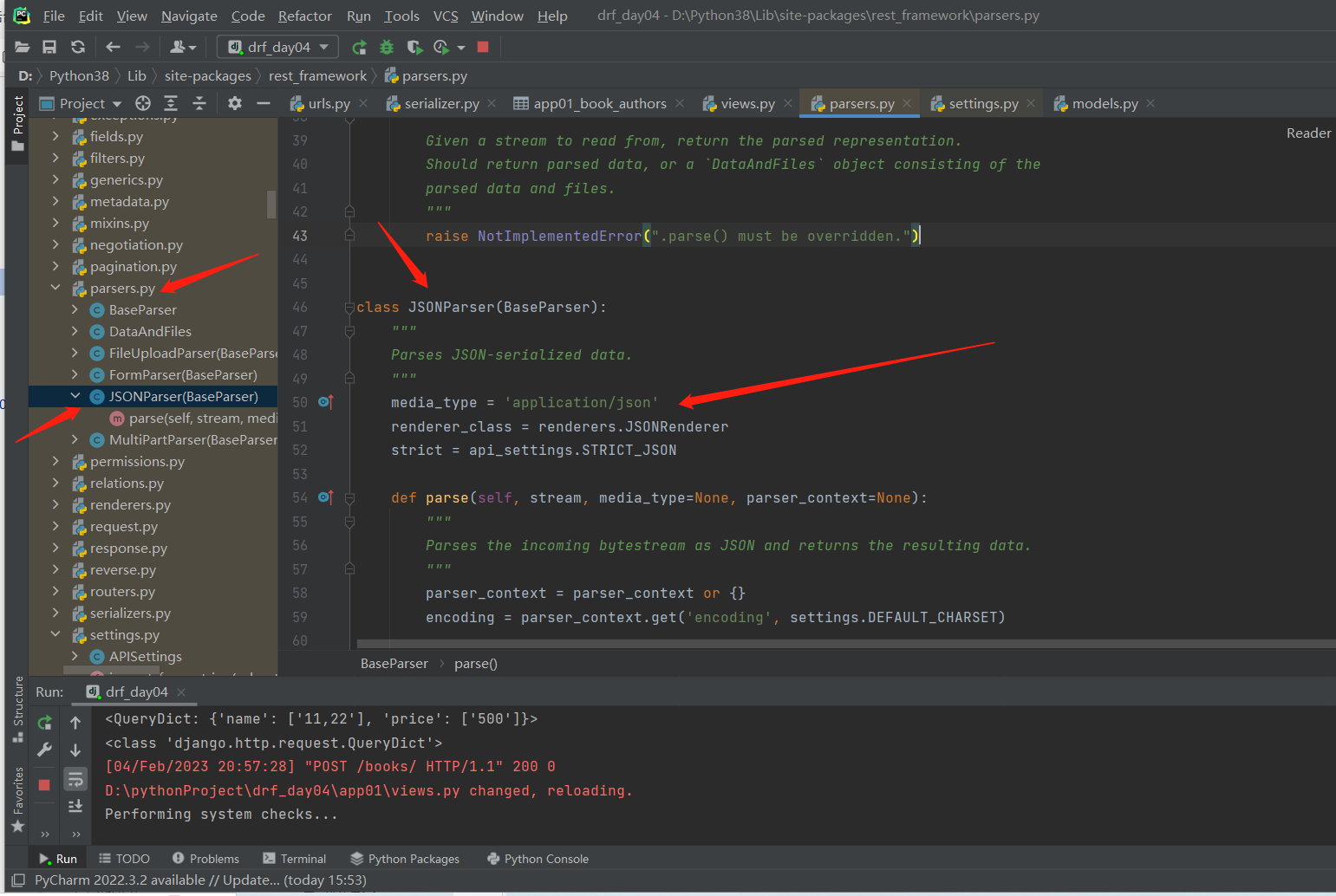
DRF的配置文件查找
lib—site-packges—rest-framework—settings.py文件里面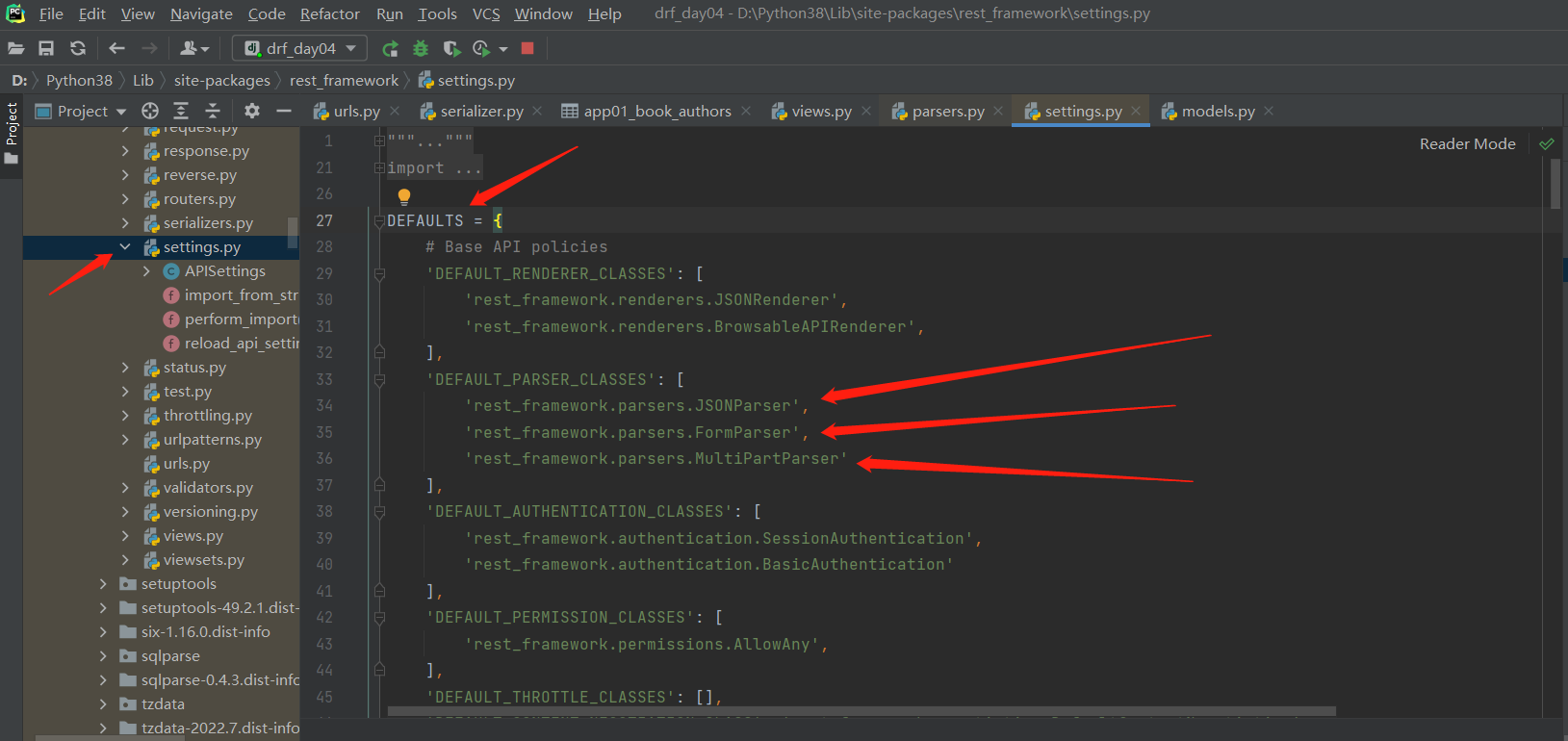
.
.
.
这样在django的配置文件中写一下,在这里配置的就对整个django项目生效了!!!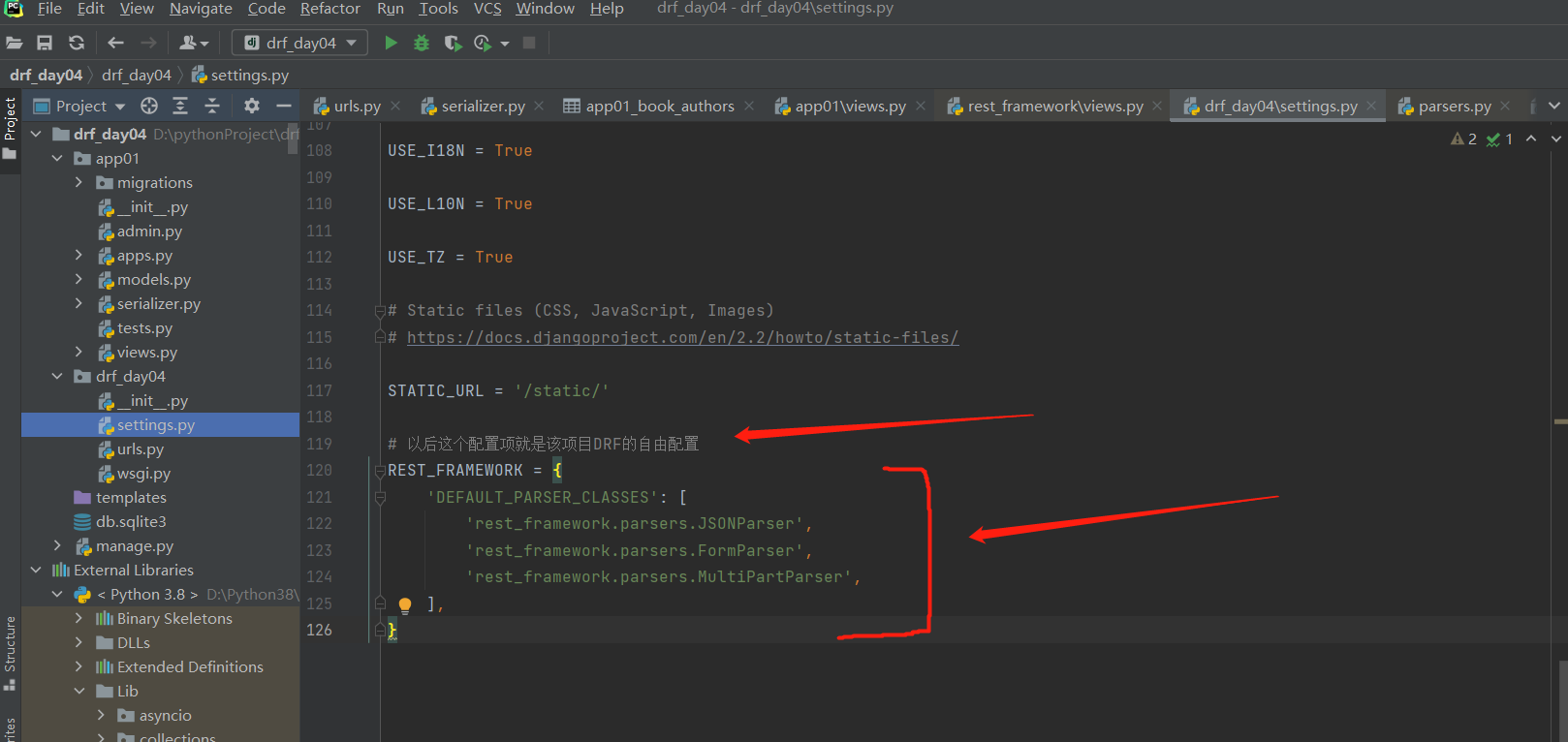
.
.
.
3.2 Request类有哪些属性和方法(学过)
# 视图类方法中的requestdata__getattr__query_params.
.
.
4 drf之响应4.1 Response能够响应的编码格式——-配置响应类
drf 是djagno的一个app,所以要注册!!!drf的响应,如果使用浏览器和postman访问同一个接口,返回格式是不一样的drf做了个判断,如果是浏览器,好看一些,如果是postman只要核心的json数据------------------------------------------------------------------------------------# 需求:现在想让浏览器也返回的也像postman一样,就返回核心的json数据,怎么办?# 两个响应类------drf的默认配置文件中找------两个类方式一:在视图类中写(局部配置,只对视图类有效)from rest_framework.renderers import JSONRenderer,BrowsableAPIRendererclass BookView(APIView): renderer_classes=[JSONRenderer,]----------------------------------------------方式二:在项目配置文件中写(全局配置,整个项目有效)REST_FRAMEWORK = { 'DEFAULT_RENDERER_CLASSES': [ 'rest_framework.renderers.JSONRenderer', 'rest_framework.renderers.BrowsableAPIRenderer', ],}------------------------------------------方式三:使用顺序(一般就用内置的即可)优先使用视图类中的配置,其次使用项目配置文件中的配置,最后使用内置的drf 是djagno的一个app,所以要注册!!!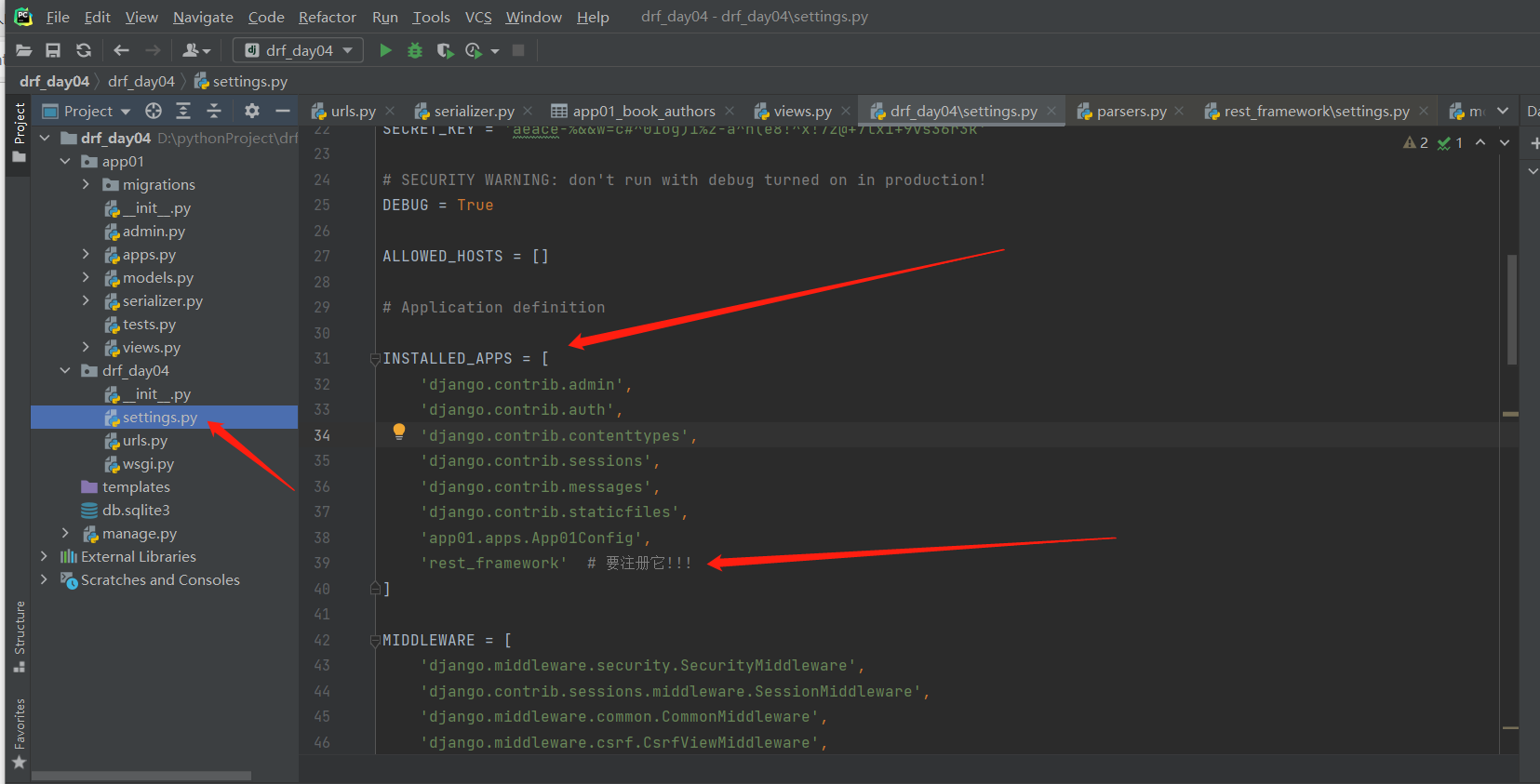
.
.
.
.
4.2 Resposne的源码属性或方法
# drf 的Response 源码分析from rest_framework.response import Response视图类的方法返回时,retrun Response ,走它的 __init__研究 init中可以传什么参数------------------------------------------# Response init 可以传的参数 def __init__(self, data=None, status=None, template_name=None, headers=None, exception=False, content_type=None)# data:之前咱们写的ser.data 可以是字典或列表或字符串---》序列化后返回给前端---》前端在响应体中看到的就是这个# status:http响应的状态码,默认是200,你可以改。drf在status包下,把所有http响应状态码都写了一遍,是个常量from rest_framework.status import HTTP_200_OKResponse('dddd',status=status.HTTP_200_OK)Response('dddd',status=200) # 这两句话一个意思# template_name:了解即可,修改响应模板的样子,BrowsableAPIRenderer定死的样子,后期公司可以自己定制# headers:响应头,http响应的响应头,可以通过传参的形式headers={'name': 'lqz'} 往响应头里面塞东西!!!思考,原生djagno如何用4板斧向响应头中加东西 ? # 四件套 render,redirect,HttpResponse,JsonResponse obj = HttpResponse('dddd') obj['age'] = '18' obj['name'] = 'lqz' return obj# content_type :响应编码格式,一般不动-----------------------------------------------# 重点:data,status,headersfrom rest_framework.status import HTTP_200_OK
.
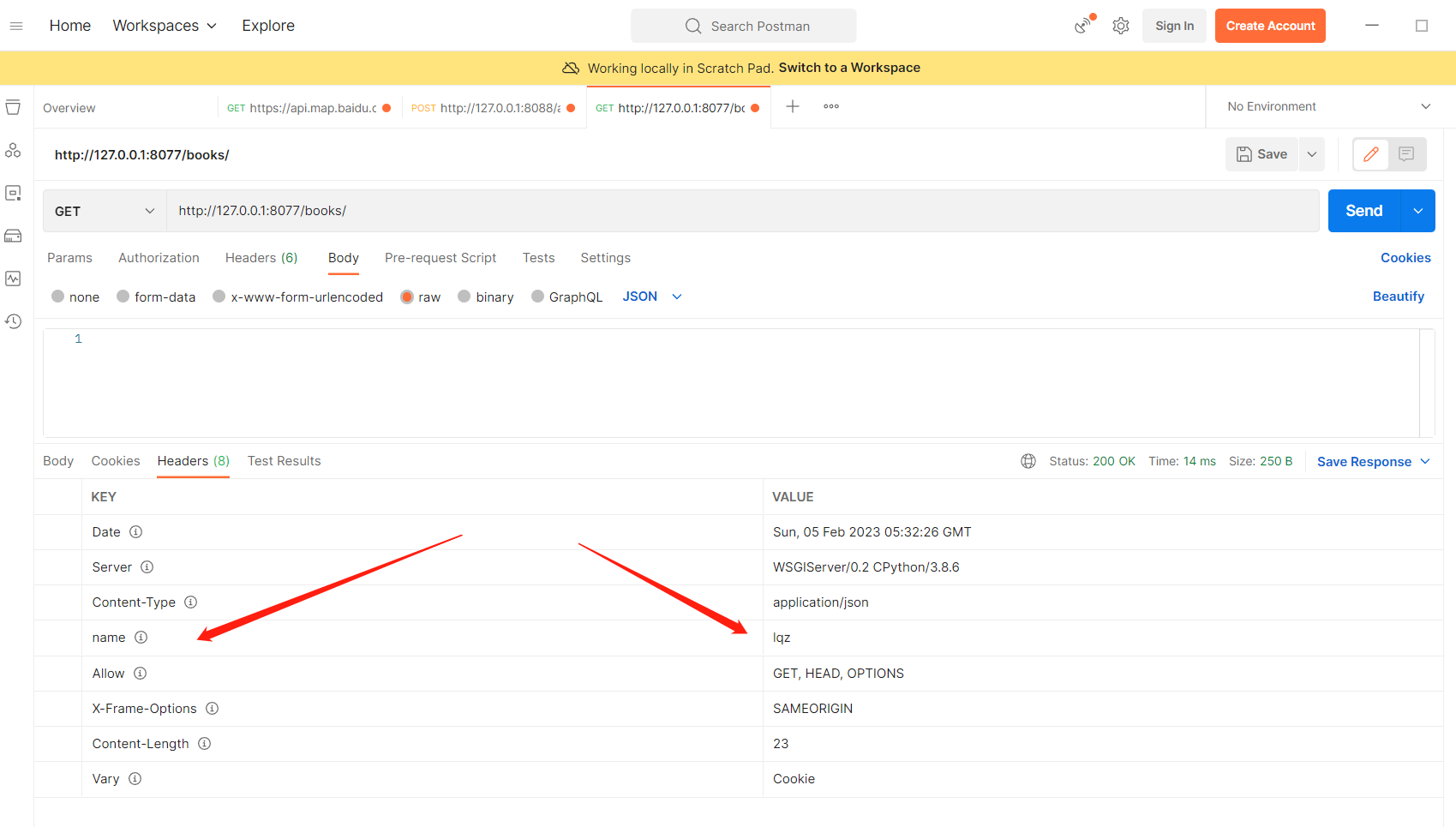
用DRF的Response 往响应头里面加东西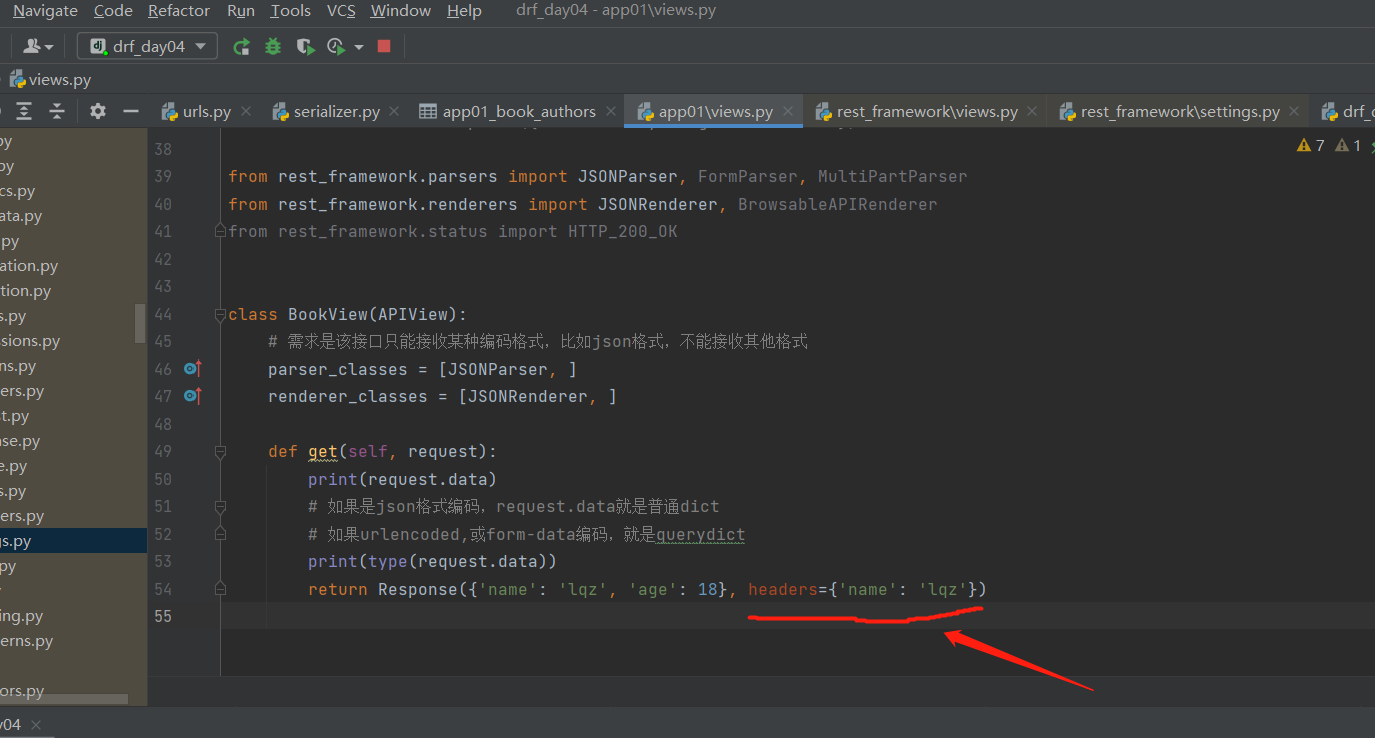
.
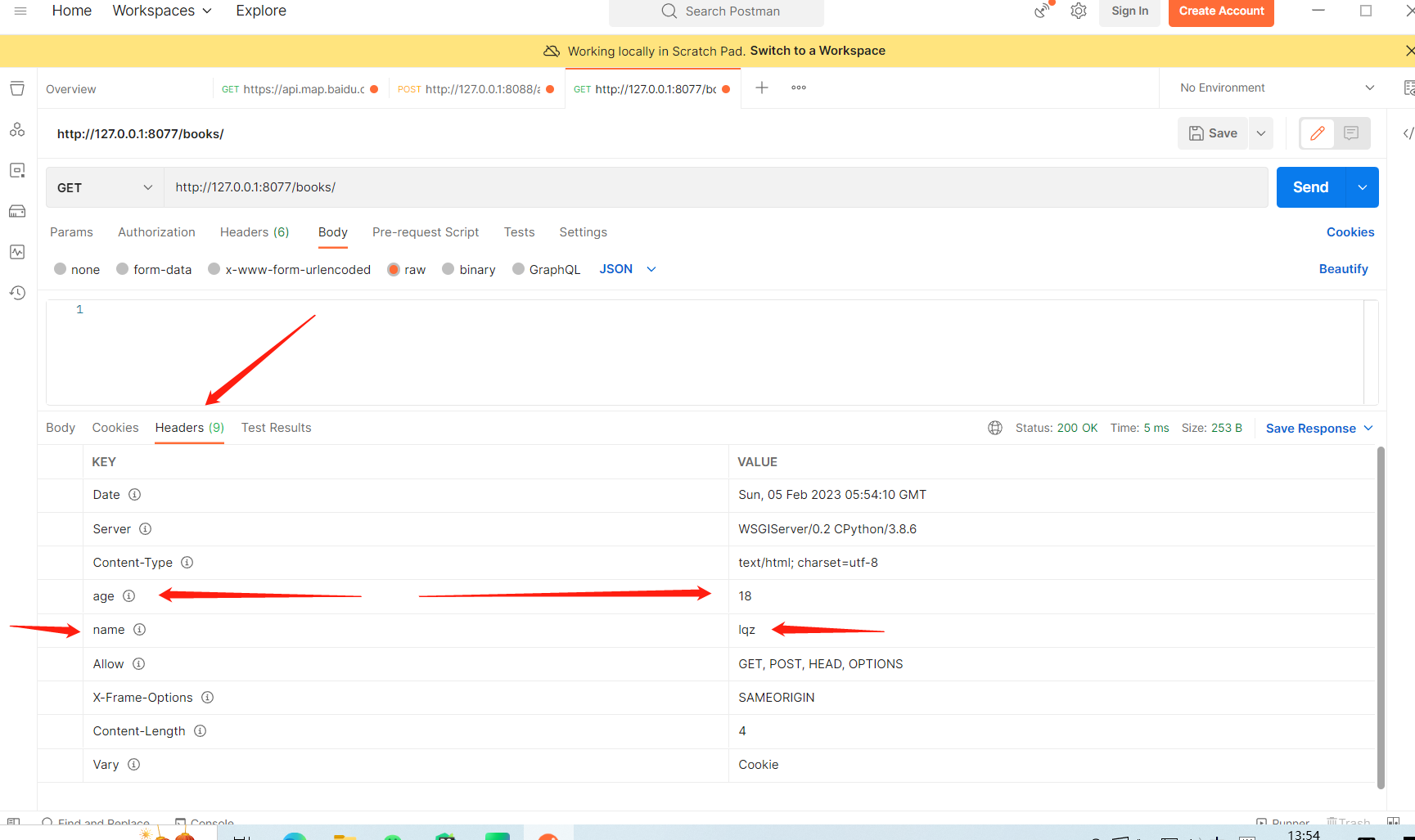
用django的四板斧 往响应头里面加东西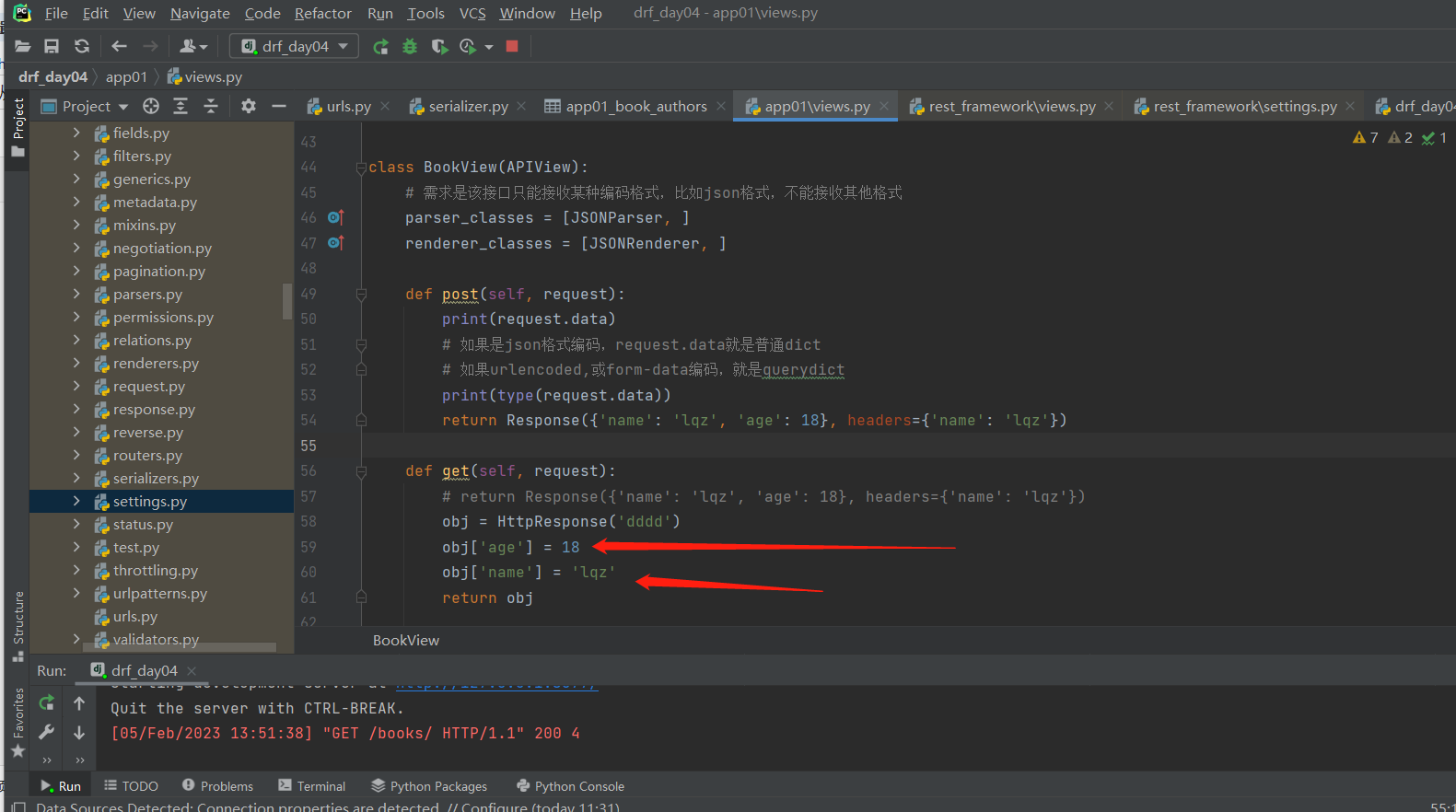
.
.
.
.
5 视图组件介绍 及 两个视图基类 与 五个视图扩展类的 用法介绍
# 之前学过APIView,是drf的基类,是drf提供的最顶层的类------------------------------------------# APIView跟之前的View区别:-传入到视图方法中的是REST framework的Request对象,而不是Django的HttpRequeset对象-视图方法可以返回 REST framework的Response对象-任何APIException异常都会被捕获到,并且处理成合适的响应信息-在进行dispatch()分发前,会对请求进行身份认证、权限检查、频率流量控制------------------------------------------# drf的 两个视图基类APIVIew 与 GenericAPIView------------------------------------------# APIVIew的类里面属性:renderer_classes # 响应格式类parser_classes # 能够解析的请求格式类authentication_classes # 认证类throttle_classes # 频率类permission_classes # 权限类.
.
.
.
5.1 第一层 用APIView + ModelSerializer + Resposne 写5个接口
# 视图类代码from .models import Bookfrom .serializer import BookSerializerclass BookView(APIView): def get(self, request): books = Book.objects.all() ser = BookSerializer(instance=books, many=True) return Response(ser.data) def post(self, request): ser = BookSerializer(data=request.data) if ser.is_valid(): ser.save() return Response({'code': 100, 'msg': '新增成功', 'result': ser.data})# restful规范里面要求把新增对策数据返回,怎么返回新增的数据 ?# 我们现在只有ser序列化类的对象,能不能拿到新增的对象?可以,ser.save方法运行会触发create方法运行,create方法的返回值就是新增的对象# 所以ser.data该方法的作用:就是将create方法的返回值也就是新增的表模型对象,再序列化成字典给前端# 所以说虽然post方法整体是将前端的字符串转化为对象的反序列化的过程,但是该方法最后还是有一步将对象序列化成字典的过程!!# 所以序列化类中的create方法一定要返回新增的对象,否则ser.data方法没拿到新增的对象,序列化也拿不到新增对象的数据!!! else: return Response({'code': 101, 'msg': ser.errors})class BookDetailView(APIView): def get(self, request, pk): books = Book.objects.filter(pk=pk).first() ser = BookSerializer(instance=books)# 所以说ser=BookSerializer(XXX)只是一个生成对象给对象添加属性的过程,正真将表模型对象转成字典是ser.data在做!!! return Response(ser.data) def put(self, request, pk): books = Book.objects.filter(pk=pk).first() ser = BookSerializer(instance=books, data=request.data) if ser.is_valid(): ser.save() return Response({'code': 100, 'msg': '修改成功', 'result': ser.data}) else: return Response({'code': 101, 'msg': ser.errors}) def delete(self, request, pk): Book.objects.filter(pk=pk).delete() return Response({'code': 100, 'msg': '删除成功'})---------------------------------------------------------------------------------------------------------------------------------------------# 序列化类### ModelSerializer的使用class BookSerializer(serializers.ModelSerializer): # 跟表有关联 class Meta: model = Book fields = ['name', 'price', 'publish_detail', 'author_list', 'publish', 'authors'] extra_kwargs = {'name': {'max_length': 8}, 'publish_detail': {'read_only': True}, 'author_list': {'read_only': True}, 'publish': {'write_only': True}, 'authors': {'write_only': True}, }# ModelSerializer序列化类帮我们干了好多事,原来用Serializer序列化类时,序列化字段与反序列化字段都要我们自己写,现在用fields配一下,全部将模型表里面的字段都映射过来了# 而且最骚的是模型表里面的一对多的外键字段映射过来自动变成了Integerfield,多对多的外键字段映射过来自动变成了ListField的了!!# 而且原来我们要自己写create与update方法,将校验过后的数据利用ORM语句写入数据库,现在全被ModelSerializer序列化类自动帮我们干了!!!---------------------------------------------------------------------------------------------------------------------------------------------# 路由urlpatterns = [ path('admin/', admin.site.urls), path('books/', views.BookView.as_view()), path('books//', views.BookDetailView.as_view()),].
注意前端传数据反序列新增或者修改的时候,用postman在请求体里面写数据的时候有点不一样比如json格式我们这样写{"name":"红楼","price":199,"publish":1,"authors":[1,3]}但是如果用urlencode或者form-data格式写的时候,对于多对多的authors外键字段有点不一样,authors键对应的框里面不能直接填一个[1,3],而是要把authors写两遍,一个对应1,一个对应3这么来操作
.
.
.
.
5.2 第二层 基于 GenericAPIView + ModelSerializer 写5个接口
# 研究 如果我们要写publish的5个接口,只要复制之前的代码,改一部分,就可以快速写出publish的5个接口,区别就只在于表模型与序列化类# 可以通过继承,少些代码,GenericAPIView 继承了APIView 并扩展了新的属性与方法!!'''GenericAPIView 的属性和方法:属性:queryset: 要序列化或反序列化的表模型对象serializer_class: 使用的序列化类lookup_field : 查询单条的 路由匹配的转换器里面的分组名filter_backends: 过滤类的配置pagination_class: 分页类的配置方法:get_queryset() 获取序列化的对象get_object() 获取单个对象get_serializer() 获取序列化对象filter_queryset() 跟后续的排序由关系'''from rest_framework.generics import GenericAPIViewclass BookView(GenericAPIView): queryset = Book.objects.all() # 原来我们是写在函数里面的,现在写外面,在函数里面通过self.queryset拿表模型对象 serializer_class = BookSerializer def get(self, request): # objs = self.queryset # 这里可以拿到,但是不要这么用,GenericAPIView提供了另一个方法 objs = self.get_queryset() # get_queryset()函数的返回值就是self.queryset,相当于套了一层壳 # 那不是多此一举吗?那你就浅了,这样操作有个好处,可以在序列化类里面重写该get_queryset方法 # 然后在self.queryset里面加点其他数据,或者剔除掉一些数据,那序列化的对象是不是就不一样了!所以直接拿就写死了,扩展性差了!! # 调用get_queryset()前,就可以在拿前先重写get_queryset()方法,对queryset对象先处理一下!!! ser = self.get_serializer(instance=objs, many=True) # 同理也是给self.serializer_class() 套了一层壳!!后期可以重写get_serializer_class方法,通过返回值来控制所使用的序列化类 return Response(ser.data) def post(self, request): ser = self.get_serializer(data=request.data) if ser.is_valid(): ser.save() return Response({'code': 100, 'msg': '新增成功', 'result': ser.data}) else: return Response({'code': 101, 'msg': ser.errors})class BookDetailView(GenericAPIView): queryset = Book.objects.all() # 原来我们是写在函数里面的,现在写外面,在函数里面通过self.queryset拿表模型对象 serializer_class = BookSerializer # lookup_field = 'pk' # 如果路由匹配的转换器里面的分组名不是pk,要手动在这改一下,如果是pk这句话可以不写! def get(self, request, pk): obj = self.get_object() # 获取表模型的单条对象 ser = self.get_serializer(instance=obj) return Response(ser.data) def put(self, request, pk): obj = self.get_object() ser = self.get_serializer(instance=obj, data=request.data) if ser.is_valid(): ser.save() return Response({'code': 100, 'msg': '修改成功', 'result': ser.data}) else: return Response({'code': 101, 'msg': ser.errors}) def delete(self, request, pk): self.get_object().delete() return Response({'code': 100, 'msg': '删除成功'}).
.
.
.
.
5.3 第三层 基于 5个视图扩展类 + ModelSerializer 写5个接口
# 视图类代码from rest_framework.mixins import CreateModelMixin, UpdateModelMixin, DestroyModelMixin, RetrieveModelMixin, ListModelMixin# 基于GenericAPIView + 5个视图扩展类写接口class BookView(GenericAPIView, ListModelMixin, CreateModelMixin): queryset = Book.objects.all() serializer_class = BookSerializer def get(self, request): return self.list(request) def post(self, request): return self.create(request)class BookDetailView(GenericAPIView, RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin): queryset = Book.objects.all() serializer_class = BookSerializer # def get(self, request, pk): # return self.retrieve(request,pk) 可以直接写pk 也可以像下面一样写,都行 def get(self, request, *args, **kwargs): return self.retrieve(request, *args, **kwargs) def put(self, request, *args, **kwargs): return self.update(request, *args, **kwargs) def delete(self, request, *args, **kwargs): return self.destroy(request, *args, **kwargs)---------------------------------------------------------------------------------------------------------------------------------------------# 序列化类代码class BookSerializer(serializers.ModelSerializer): # 跟表有关联 class Meta: model = Book fields = ['name', 'price', 'publish_detail', 'author_list', 'publish', 'authors'] extra_kwargs = {'name': {'max_length': 8}, 'publish_detail': {'read_only': True}, 'author_list': {'read_only': True}, 'publish': {'write_only': True}, 'authors': {'write_only': True}, }---------------------------------------------------------------------------------------------------------------------------------------------# 路由urlpatterns = [ path('admin/', admin.site.urls), path('books/', views.BookView.as_view()), path('books//', views.BookDetailView.as_view()),].
.
.
.
作业
# 1 研究反序列化源码# 2 整理断言的使用# 3 整理drf的请求与响应# 4 基于APIView写5个接口基于GenericAPIView 基于GenericAPIView+5个视图扩展类# 5 剩下两层-第一层 class PublishView(CreateAPIView): queryset = Book.objects.all() serializer_class = BookSerializer class BookDetailView(DestroyAPIView): queryset = Book.objects.all() serializer_class = BookSerializer -第二层带5个接口 class PublishView(CreateAPIView): queryset = Book.objects.all() serializer_class = BookSerializer # 周六周天:刷 面向对象视频