原创:扣钉日记(微信公众号ID:codelogs),欢迎分享,非公众号转载保留此声明。
简介
日常编程工作中,Java集合会经常被使用到,且经常需要对集合做一些类似过滤、排序、对象转换之类的操作。
为了简化这类操作,Java8添加了一套新的Stream API,使用方式就像写SQL一样,大大简化了这类处理的实现代码量与可读性。
基础Stream函数
比如,我们要查询双11期间交易额最大的10笔订单的用户信息,用SQL实现的话,大致如下:
select user_id, user_name from order where pay_time >= '2022-11-01' and pay_time < '2022-12-01' order by goods_amount desc limit 10;这种处理逻辑,不用Stream API,实现代码大致如下:
public static List getTop10Users() throws ParseException { List orders = getOrders(); // 过滤出双11订单 List filteredOrders = new ArrayList(); long begin = DateUtils.parseDate("2022-11-01", "yyyy-MM-dd").getTime(); long end = DateUtils.parseDate("2022-12-01", "yyyy-MM-dd").getTime(); for (Order order : orders) { if(order.getPayTime().getTime() >= begin && order.getPayTime().getTime() < end) { filteredOrders.add(order); } } // 按订单金额倒序排序 filteredOrders.sort(Comparator.comparing(Order::getGoodsAmount).reversed()); // 取前10名订单,组装出用户信息 List users = new ArrayList(); Iterator it = filteredOrders.iterator(); for (int i = 0; i < 10 && it.hasNext(); i++) { Order order = it.next(); users.add(new User(order.getUserId(), order.getUserName())); } return users;}上面代码与SQL的逻辑是一样的,但可以发现,上面代码的可理解性比SQL差很多,原因是SQL使用的是含义更加接近意图的声明式语法,而上述代码如果没有很好的注释的话,则需要你的大脑像CPU一样,将各种指令执行一遍才明白大概意图。
那我们再用Stream API实现一下这个函数看看,如下:
public static List getTop10Users() throws ParseException { List orders = getOrders(); long begin = DateUtils.parseDate("2022-11-01", "yyyy-MM-dd").getTime(); long end = DateUtils.parseDate("2022-12-01", "yyyy-MM-dd").getTime(); List users = orders.stream() .filter(order -> order.getPayTime().getTime() >= begin && order.getPayTime().getTime() new User(order.getUserId(), order.getUserName())) .collect(Collectors.toList()); return users;}这段代码我没有加注释,但只要有过一点经验的程序员,都能很快明白它是在做啥,这是因为Stream API和SQL设计类似,使用的是更加接近意图的声明式函数,看到函数名就大概明白含义了。
大概解释一下,如下:
stream()函数用于将集合转换为Stream流对象。filter()函数过滤Stream流中的元素,传入的逻辑表达式则为过滤规则。sorted()函数排序Stream流中的元素,使用传入的Comparator比较元素大小。limit()函数取前x个元素,传入参数指定取的元素个数。map()函数用于转换Stream中的元素为另一类型元素,可以类比于SQL从表中查询指定字段时,就好像是创建了一个包含这些字段的临时表一样。
Stream里面的函数大多很简单,就不逐一介绍了,如下:
| 函数 | 用途 | 类比SQL |
|---|---|---|
| map | 转换Stream中的元素为另一类型元素 | select x,y,z |
| filter | 过滤Stream中元素 | where |
| sorted | 排序Stream中元素 | order by |
| limit | 取前x个元素 | limit |
| distinct | 去重Stream中元素 | distinct |
| count | 计数 | count(*) |
| min | 计算最小值 | min(x) |
| max | 计算最大值 | max(x) |
| forEach | 消费Stream中的每个元素 | – |
| toArray | 转换为数组 | – |
| findFirst | 获取第1个元素 | – |
| findAny | 获取任一个元素,与findFirst区别是findAny可能是数据拆分后多线程处理的,返回值可能不稳定 | – |
| allMatch | Stream中元素全部匹配判定表达式 | – |
| anyMatch | Stream中元素任一匹配判定表达式 | – |
| noneMatch | Stream中元素全部不匹配判定表达式 | – |
| peek | 检查经过Stream的每个元素,但并不消费元素,一般用于调试目的 | – |
这些是Stream比较基础的用法,下面看看一些更高级的用法吧!
reduce函数
可以看到Stream提供了min、max操作,但并没有提供sum、avg这样的操作,如果要实现sum、avg操作,就可以使用reduce(迭代)函数来实现,reduce函数有3个,如下:
下面以订单金额的sum汇总操作为示例,如下:
带初始值与累加器的reduce函数
T reduce(T identity, BinaryOperator accumulator);汇总示例:
List orders = getOrders();BigDecimal sum = orders.stream() .map(Order::getGoodsAmount) .reduce(BigDecimal.ZERO, BigDecimal::add);其中,reduce函数的identity参数BigDecimal.ZERO相当于是初始值,而accumulator参数BigDecimal::add是一个累加器,将Stream中的金额一个个累加起来。
reduce函数的执行逻辑大致如下: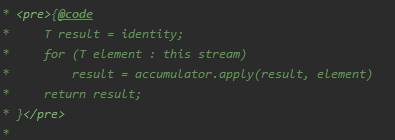
无初始值的reduce函数
Optional reduce(BinaryOperator accumulator);汇总示例:
List orders = getOrders();BigDecimal sum = orders.stream() .map(Order::getGoodsAmount) .reduce(BigDecimal::add) .orElse(BigDecimal.ZERO);第2个reduce函数不传入初始值,只有累加器函数,返回Optional,因此当Stream中没有元素时,它返回的Optional没有值,这种情况我使用Optional.orElse函数给了一个默认值BigDecimal.ZERO。
带初始值、累加器、合并器的reduce函数
U reduce(U identity, BiFunction accumulator, BinaryOperator combiner);汇总示例:
List orders = getOrders();BigDecimal sum = orders.stream() .reduce(BigDecimal.ZERO, (s, o) -> s.add(o.getGoodsAmount()), BigDecimal::add);这个reduce函数的累加器和前面的不一样,前面的累加器的迭代元素与汇总结果都是BigDecimal,而这个累加器的迭代元素是Order类型,汇总结果是BigDecimal类型,它们可以不一样。
另外,这个reduce函数还提供了一个合并器,它是做什么用的?
其实合并器用于并行流场景,当使用多个线程处理数据时,数据拆分给多个线程后,每个线程使用累加器计算出自己的汇总值,然后使用合并器将各个线程的汇总值再次汇总,从而计算出最后结果,执行过程如下图:
使用reduce实现avg
reduce可以实现avg,但稍微有点繁琐,如下:
@Dataprivate static class SumCount { private BigDecimal sum = BigDecimal.ZERO; private Integer count = 0; /** * 累加函数 * @param val * @return */ public SumCount accumulate(BigDecimal val) { this.sum = this.sum.add(val); this.count++; return this; } /** * 合并函数 * @param sumCount * @return */ public SumCount merge(SumCount sumCount) { SumCount sumCountNew = new SumCount(); sumCountNew.setSum(this.sum.add(sumCount.sum)); sumCountNew.setCount(this.count + sumCount.count); return sumCountNew; } public Optional calAvg(int scale, int roundingMode) { if (count == 0) { return Optional.empty(); } return Optional.of(this.sum.divide(BigDecimal.valueOf(count), scale, roundingMode)); }}List orders = getOrders();Optional avg = orders.stream() .map(Order::getGoodsAmount) .reduce(new SumCount(), SumCount::accumulate, SumCount::merge) .calAvg(2, BigDecimal.ROUND_HALF_UP);如上,由于avg是由汇总值除以数量计算出来的,所以需要定义一个SumCount类来记录汇总值与数量,并实现它的累加器与合并器函数即可。
可以发现,使用reduce函数实现avg功能,还是有点麻烦的,而且代码可读性不强,大脑需要绕一下才知道是在求平均数,而collect函数就可以很方便的解决这个问题。
collect函数
Stream API提供了一个collect(收集)函数,用来处理一些比较复杂的使用场景,它传入一个收集器Collector用来收集流中的元素,并做特定的处理(如汇总),Collector定义如下:
public interface Collector { Supplier supplier(); BiConsumer accumulator(); BinaryOperator combiner(); Function finisher(); Set characteristics();}其实,收集器与reduce是比较类似的,只是比reduce更加灵活了,如下:
- supplier: 初始汇总值提供器,类似reduce中的identity,只是这个初始值是函数提供的。
- accumulator:累加器,将值累加到收集器中,类似reduce中的accumulator。
- combiner:合并器,用于并行流场景,类似reduce中的combiner。
- finisher:结果转换器,将汇总对象转换为最终的指定类型对象。
- characteristics:收集器特征标识,如是否支持并发等。
那用收集器实现类似上面的avg试试!
@Datapublic class AvgCollector implements Collector<BigDecimal, SumCount, Optional> { private int scale; private int roundingMode; public AvgCollector(int scale, int roundingMode) { this.scale = scale; this.roundingMode = roundingMode; } @Override public Supplier supplier() { return SumCount::new; } @Override public BiConsumer accumulator() { return (sumCount, bigDecimal) -> { sumCount.setSum(sumCount.getSum().add(bigDecimal)); sumCount.setCount(sumCount.getCount() + 1); }; } @Override public BinaryOperator combiner() { return (sumCount, otherSumCount) -> { SumCount sumCountNew = new SumCount(); sumCountNew.setSum(sumCount.getSum().add(otherSumCount.getSum())); sumCountNew.setCount(sumCount.getCount() + otherSumCount.getCount()); return sumCountNew; }; } @Override public Function<SumCount, Optional> finisher() { return sumCount -> { if (sumCount.getCount() == 0) { return Optional.empty(); } return Optional.of(sumCount.getSum().divide( BigDecimal.valueOf(sumCount.getCount()), this.scale, this.roundingMode)); }; } @Override public Set characteristics() { return Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.UNORDERED)); }}如上,实现一个AvgCollector收集器,然后将这个收集器传给collect函数即可。
List orders = getOrders();Optional> avg = orders.stream() .map(Order::getGoodsAmount) .collect(new AvgCollector(2, BigDecimal.ROUND_HALF_UP));整体执行过程如下: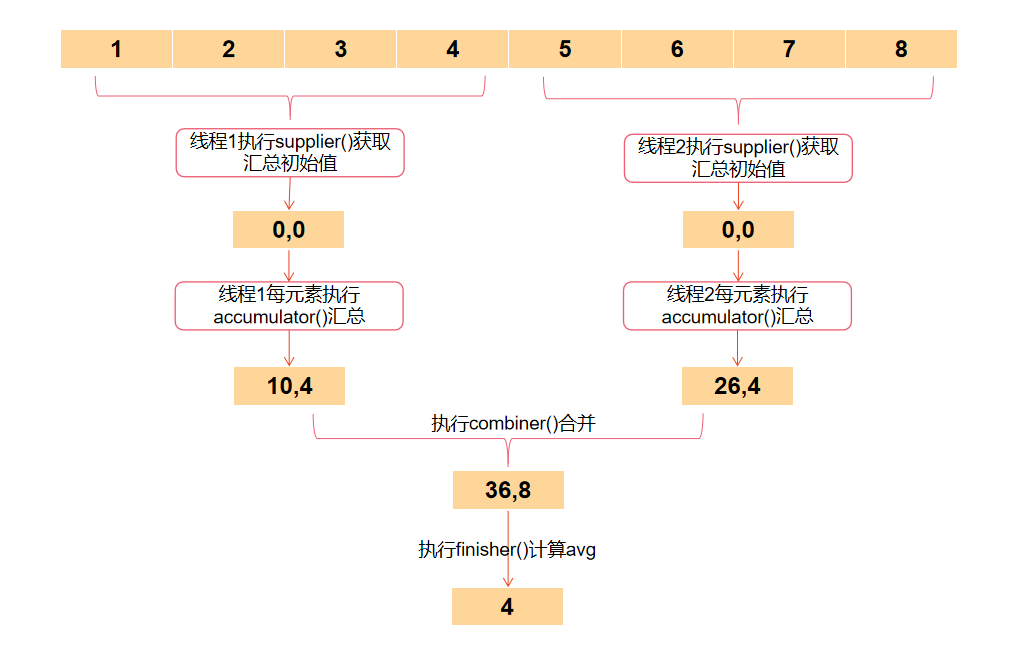
可以发现,其实Collector相比reduce,就是把相关操作都封装到一个收集器里面去了,这样做的好处是,可以事先定义好一些Collector,然后使用方就可以直接拿来用了。
所以,Java也为我们提供了一系列常用场景的Collector,它们放在Collectors中,如下:
| 收集器 | 用途 |
|---|---|
Collectors.toList() | 将流中元素收集为List |
Collectors.toSet() | 将流中元素收集为Set |
Collectors.toMap() | 将流中元素收集为Map |
Collectors.toCollection() | 将流中元素收集为任意集合 |
Collectors.mapping() | 元素类型转换 |
Collectors.counting() | 计数 |
Collectors.minBy() | 计算最小值 |
Collectors.maxBy() | 计算最大值 |
Collectors.summingXXX() | 求和 |
Collectors.averagingXXX() | 求平均数 |
Collectors.reducing() | 迭代操作 |
Collectors.groupingBy() | 分组汇总 |
Collectors.joining() | 拼接字符串 |
Collectors.collectingAndThen() | 收集结果后,对结果再执行一次类型转换 |
可以发现,Java已经为我们提供了大量的收集器实现,对于绝大多数场景,我们并不需要自己去实现收集器啦!
以上函数就不一一介绍了,介绍几个典型例子,如下:
元素收集到TreeSet中
TreeSet orderSet = orders.stream() .collect(Collectors.toCollection(TreeSet::new));元素收集到Map中
List orders = getOrders();Map orderMap = orders.stream() .collect(Collectors.toMap(Order::getOrderId, Function.identity()));如上,Order::getOrderId函数为Map提供Key值,Function.identity()函数定义如下: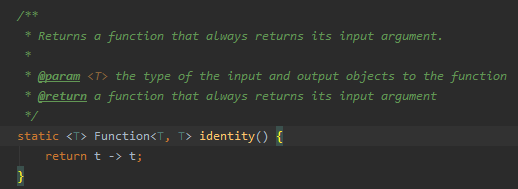
它的作用是直接返回传给它的参数,你写成o -> o也是可以的,如果你想得到Map这样的Map,那应该如下写:
List orders = getOrders();Map amountMap = orders.stream() .collect(Collectors.toMap(Order::getOrderId, Order::getGoodsAmount));在知道了怎么获取Key与Value后,Collectors.toMap()收集器就知道怎么去生成Map了。
但toMap有一个容易忽略的坑,就是默认情况下,如果List生成的Key值有重复,则会抛出异常,如果你不想抛异常,可以再传入一个冲突处理函数,如下:
List orders = getOrders();Map orderMap = orders.stream() .collect(Collectors.toMap(Order::getOrderId, Function.identity(), (ov, v)->v));(ov, v)->v函数含义是,当新元素Key值冲突时,ov是map中的旧值,v是新值,返回v则代表使用新值,即后面元素覆盖前面元素的值。
实现分组汇总操作
比如我们经常需要将List分组为Map<K, List>的形式,可以使用groupingBy收集器,看groupingBy收集器的定义,如下:
它需要提供两个参数,第一个参数classifier指定分类的Key回调函数,第二个参数downstream指定下游收集器,即提供每个Key对应Value的聚合收集器。
看几个例子:
按省份分组汇总订单
Map<Integer, List> groupedOrderMap = orders.stream() .collect(Collectors.groupingBy(Order::getProvince, Collectors.toList()));其中Order::getProvince函数提供分类的Key值,Collectors.toList()提供分类后的Value聚合操作,将值聚合成List。
按省份分组汇总单量
类似如下SQL:
select province, count(*) from order group by province;java实现如下:
Map groupedCountMap = orders.stream() .collect(Collectors.groupingBy(Order::getProvince, Collectors.counting()));按省份分组汇总金额
类似如下SQL:
select province, sum(goods_amount) from order group by province;java实现如下:
Map<Integer, Optional> groupedAmountMap = orders.stream() .collect(Collectors.groupingBy(Order::getProvince, Collectors.mapping(Order::getGoodsAmount, Collectors.reducing(BigDecimal::add))));按省份分组汇总单号
类似如下SQL:
select province, group_concat(order_id) from order group by province;java实现如下:
Map groupedOrderIdMap = orders.stream() .collect(Collectors.groupingBy(Order::getProvince, Collectors.mapping(order -> order.getOrderId().toString(), Collectors.joining(","))));按省、市汇总并计算单量、金额等
类似如下SQL:
select province, city, count(*), group_concat(order_id), group_concat(goods_amount), sum(goods_amount), min(goods_amount), max(goods_amount), avg(goods_amount) from order group by province, city;java实现如下:
@NoArgsConstructor@Dataclass ProvinceCityStatistics { private Integer province; private Integer city; private Long count; private String orderIds; private List amounts; private BigDecimal sum; private BigDecimal min; private BigDecimal max; private BigDecimal avg; public ProvinceCityStatistics(Order order){ this.province = order.getProvince(); this.city = order.getCity(); this.count = 1L; this.orderIds = String.valueOf(order.getOrderId()); this.amounts = new ArrayList(Collections.singletonList(order.getGoodsAmount())); this.sum = order.getGoodsAmount(); this.min = order.getGoodsAmount(); this.max = order.getGoodsAmount(); this.avg = order.getGoodsAmount(); } public ProvinceCityStatistics accumulate(ProvinceCityStatistics other) { this.count = this.count + other.count; this.orderIds = this.orderIds + "," + other.orderIds; this.amounts.addAll(other.amounts); this.sum = this.sum.add(other.sum); this.min = this.min.compareTo(other.min) = 0 ? this.max : other.max; this.avg = this.sum.divide(BigDecimal.valueOf(this.count), 2, BigDecimal.ROUND_HALF_UP); return this; }}List orders = getOrders();Map<String, Optional> groupedMap = orders.stream().collect( Collectors.groupingBy(order -> order.getProvince() + "," + order.getCity(), Collectors.mapping(order -> new ProvinceCityStatistics(order), Collectors.reducing(ProvinceCityStatistics::accumulate))));groupedMap.values().stream().map(Optional::get).forEach(provinceCityStatistics -> { Integer province = provinceCityStatistics.getProvince(); Integer city = provinceCityStatistics.getCity(); long count = provinceCityStatistics.getCount(); String orderIds = provinceCityStatistics.getOrderIds(); List amounts = provinceCityStatistics.getAmounts(); BigDecimal sum = provinceCityStatistics.getSum(); BigDecimal min = provinceCityStatistics.getMin(); BigDecimal max = provinceCityStatistics.getMax(); BigDecimal avg = provinceCityStatistics.getAvg(); System.out.printf("province:%d, city: %d -> count: %d, orderIds: %s, amounts: %s," + " sum: %s, min: %s, max: %s, avg : %s %n", province, city, count, orderIds, amounts, sum, min, max, avg);});执行结果如下:
可以发现,使用Collectors.reducing可以实现功能,但有点繁琐,且代码含义不明显,因此我封装了一个MultiCollector收集器,用来将多种收集器组合起来,实现这种复杂场景,如下:
/** * 将多个收集器,组合成一个收集器 * 汇总结果保存在Map中,最终结果转换成R类型返回 * * @param */public class MultiCollector implements Collector<T, Map, R> { private Class clazz; private Map<String, Collector> collectorMap; public MultiCollector(Class clazz, Map<String, Collector> collectorMap) { this.clazz = clazz; this.collectorMap = collectorMap; } @Override public Supplier<Map> supplier() { Map<String, Supplier> supplierMap = new HashMap(); collectorMap.forEach((fieldName, collector) -> supplierMap.put(fieldName, collector.supplier())); return () -> { Map map = new HashMap(); supplierMap.forEach((fieldName, supplier) -> { map.put(fieldName, supplier.get()); }); return map; }; } @Override @SuppressWarnings("all") public BiConsumer<Map, T> accumulator() { Map<String, BiConsumer> accumulatorMap = new HashMap(); collectorMap.forEach((fieldName, collector) -> accumulatorMap.put(fieldName, collector.accumulator())); return (map, order) -> { accumulatorMap.forEach((fieldName, accumulator) -> { ((BiConsumer)accumulator).accept(map.get(fieldName), order); }); }; } @Override @SuppressWarnings("all") public BinaryOperator<Map> combiner() { Map<String, BinaryOperator> combinerMap = new HashMap(); collectorMap.forEach((fieldName, collector) -> combinerMap.put(fieldName, collector.combiner())); return (map, otherMap) -> { combinerMap.forEach((fieldName, combiner) -> { map.put(fieldName, ((BinaryOperator)combiner).apply(map.get(fieldName), otherMap.get(fieldName))); }); return map; }; } @Override @SuppressWarnings("all") public Function<Map, R> finisher() { Map<String, Function> finisherMap = new HashMap(); collectorMap.forEach((fieldName, collector) -> finisherMap.put(fieldName, collector.finisher())); // 将Map反射转换成指定类对象,这里用json反序列化也可以 return map -> { R result = newInstance(clazz); finisherMap.forEach((fieldName, finisher) -> { Object value = ((Function)finisher).apply(map.get(fieldName)); setFieldValue(result, fieldName, value); }); return result; }; } @Override public Set characteristics() { return Collections.emptySet(); } private static R newInstance(Class clazz){ try { return clazz.newInstance(); } catch (ReflectiveOperationException e) { return ExceptionUtils.rethrow(e); } } @SuppressWarnings("all") private static void setFieldValue(Object obj, String fieldName, Object value){ if (obj instanceof Map){ ((Map)obj).put(fieldName, value); } else { try { new PropertyDescriptor(fieldName, obj.getClass()).getWriteMethod().invoke(obj, value); } catch (Exception e) { ExceptionUtils.rethrow(e); } } }}然后封装一些语义更加明确的通用Collector方法,如下:
public class CollectorUtils { /** * 取第一个元素,类似Stream.findFirst,返回Optional * @param mapper 获取字段值的函数 * @return */ public static Collector<T, ?, Optional> findFirst(Function mapper){ return Collectors.mapping(mapper, Collectors.reducing((u1, u2) -> u1)); } /** * 取第一个元素,类似Stream.findFirst,返回U,可能是null * @param mapper 获取字段值的函数 * @return */ public static Collector findFirstNullable(Function mapper){ return Collectors.mapping(mapper, Collectors.collectingAndThen( Collectors.reducing((u1, u2) -> u1), opt -> opt.orElse(null))); } /** * 收集指定字段值为List * @param mapper 获取字段值的函数 * @return */ public static Collector<T, ?, List> toList(Function mapper){ return Collectors.mapping(mapper, Collectors.toList()); } /** * 收集指定字段为逗号分隔的字符串 * @param mapper 获取字段值的函数 * @return */ public static Collector joining(Function mapper, CharSequence delimiter){ return Collectors.mapping(mapper.andThen(o -> Objects.toString(o, "")), Collectors.joining(delimiter)); } /** * 对BigDecimal求和,返回Optional类型汇总值 * @param mapper 获取字段值的函数 * @return */ public static Collector<T, ?, Optional> summingBigDecimal(Function mapper){ return Collectors.mapping(mapper, Collectors.reducing(BigDecimal::add)); } /** * 对BigDecimal求和,返回BigDecimal类型汇总值,可能是null * @param mapper 获取字段值的函数 * @return */ public static Collector summingBigDecimalNullable(Function mapper){ return Collectors.mapping(mapper, Collectors.collectingAndThen( Collectors.reducing(BigDecimal::add), opt -> opt.orElse(null))); } /** * 对BigDecimal求平均值,返回Optional类型平均值 * @param mapper 获取字段值的函数 * @return */ public static Collector<T, ?, Optional> averagingBigDecimal(Function mapper, int scale, int roundingMode){ return Collectors.mapping(mapper, new AvgCollector(scale, roundingMode)); } /** * 对BigDecimal求平均值,返回BigDecimal类型平均值,可能是null * @param mapper 获取字段值的函数 * @return */ public static Collector averagingBigDecimalNullable(Function mapper, int scale, int roundingMode){ return Collectors.mapping(mapper, Collectors.collectingAndThen( new AvgCollector(scale, roundingMode), opt -> opt.orElse(null))); } /** * 求最小值,返回最小值Optional * @param mapper 获取字段值的函数 * @return */ public static <T,U extends Comparable> Collector<T, ?, Optional> minBy(Function mapper){ return Collectors.mapping(mapper, Collectors.minBy(Comparator.comparing(Function.identity()))); } /** * 求最小值,返回最小值U,可能是null * @param mapper 获取字段值的函数 * @return */ public static <T,U extends Comparable> Collector minByNullable(Function mapper){ return Collectors.collectingAndThen( Collectors.mapping(mapper, Collectors.minBy(Comparator.comparing(Function.identity()))), opt -> opt.orElse(null)); } /** * 求最大值,返回最大值Optional * @param mapper 获取字段值的函数 * @return */ public static <T,U extends Comparable> Collector<T, ?, Optional> maxBy(Function mapper){ return Collectors.mapping(mapper, Collectors.maxBy(Comparator.comparing(Function.identity()))); } /** * 求最大值,返回最大值U,可能是null * @param mapper 获取字段值的函数 * @return */ public static <T,U extends Comparable> Collector maxByNullable(Function mapper){ return Collectors.collectingAndThen( Collectors.mapping(mapper, Collectors.maxBy(Comparator.comparing(Function.identity()))), opt -> opt.orElse(null)); }}CollectorUtils中封装的各Collector用途如下:
| 方法 | 用途 |
|---|---|
findFirst(mapper) | 获取第一个值,类似Stream.findFirst,返回Optional |
findFirstlNullable(mapper) | 获取第一个值,类似Stream.findFirst,返回值可能是null |
toList(mapper) | 用于实现对指定字段收集为List |
joining(mapper) | 实现类似group_concat(order_id)的功能 |
summingBigDecimal(mapper) | 用于对BigDecimal做汇总处理,返回Optional |
summingBigDecimalNullable(mapper) | 用于对BigDecimal做汇总处理,返回BigDecimal |
averagingBigDecimal(mapper) | 实现对BigDecimal求平均数,返回Optional |
averagingBigDecimal(mapper) | 实现对BigDecimal求平均数,返回BigDecimal |
minBy(mapper) | 实现求最小值,返回Optional |
minByNullable(mapper) | 实现求最小值,返回BigDecimal |
maxBy(mapper) | 实现求最大值,返回Optional |
maxByNullable(mapper) | 实现求最大值,返回BigDecimal |
然后结合MultiCollector收集器与CollectorUtils中的各种Collector,就可以实现各种复杂的分组汇总逻辑了,如下:
@NoArgsConstructor@Dataclass ProvinceCityStatistics { private Integer province; private Integer city; private Long count; private String orderIds; private List amounts; private BigDecimal sum; private BigDecimal min; private BigDecimal max; private BigDecimal avg;}List orders = getOrders();Map groupedMap = orders.stream().collect( Collectors.groupingBy(order -> order.getProvince() + "," + order.getCity(), new MultiCollector( ProvinceCityStatistics.class, //指定ProvinceCityStatistics各字段对应的收集器 MapBuilder.<String, Collector>create() .put("province", CollectorUtils.findFirstNullable(Order::getProvince)) .put("city", CollectorUtils.findFirstNullable(Order::getCity)) .put("count", Collectors.counting()) .put("orderIds", CollectorUtils.joining(Order::getOrderId, ",")) .put("amounts", CollectorUtils.toList(Order::getGoodsAmount)) .put("sum", CollectorUtils.summingBigDecimalNullable(Order::getGoodsAmount)) .put("min", CollectorUtils.minByNullable(Order::getGoodsAmount)) .put("max", CollectorUtils.maxByNullable(Order::getGoodsAmount)) .put("avg", CollectorUtils.averagingBigDecimalNullable(Order::getGoodsAmount, 2, BigDecimal.ROUND_HALF_UP)) .build() ) ));groupedMap.forEach((key, provinceCityStatistics) -> { Integer province = provinceCityStatistics.getProvince(); Integer city = provinceCityStatistics.getCity(); long count = provinceCityStatistics.getCount(); String orderIds = provinceCityStatistics.getOrderIds(); List amounts = provinceCityStatistics.getAmounts(); BigDecimal sum = provinceCityStatistics.getSum(); BigDecimal min = provinceCityStatistics.getMin(); BigDecimal max = provinceCityStatistics.getMax(); BigDecimal avg = provinceCityStatistics.getAvg(); System.out.printf("province:%d, city: %d -> count: %d, orderIds: %s, amounts: %s," + " sum: %s, min: %s, max: %s, avg : %s %n", province, city, count, orderIds, amounts, sum, min, max, avg);});执行结果如下:
我想如果搞懂了这个,Collector API几乎就全玩明白了?
总结
Stream API非常实用,它的设计类似于SQL,相比于直接遍历处理集合的实现代码,用它来实现的可读性会更强。
当然,好用也不要滥用,API使用场景应该与其具体意图相对应,比如不要在filter里面去写非过滤逻辑的代码,虽然代码可能跑起来没问题,但这会误导读者,反而起到负面作用。