
目录
一、降低资源使用
1.1 降低磁盘使用率
1.2 异步日志
1.3 降低cpu使用率
二、日志链路追踪
2.1 ThreadLocal技术选型
2.2 TTL线程池改造
2.3 Log4j2 MDC + TTL线程池实现
2.4 链路日志使用
三、测试指标及建议
3.1 建议
3.2 测试指标
3.3 Log4j2各项参数测试结果
随着京东到家的业务发展,作为黄金链路之一的购物车系统访问量也越来越大,打印日志的场景也越来越多,系统方面面临以下急需解决的问题:
日志输出过多,磁盘压力大,排查问题要过滤大量日志。
日志导致cpu负载过高,甚至会打满,影响服务的性能和吞吐量。
无法快速精准的定位出某个请求链路的所有日志,定位问题比较困难。
经过购物车线上真实流量和系统压测验证,我们在减少磁盘使用率,降低cpu负载等方面进行了优化,在接口性能和吞吐量等方面得到了很大程度的提升。
一、降低资源使用
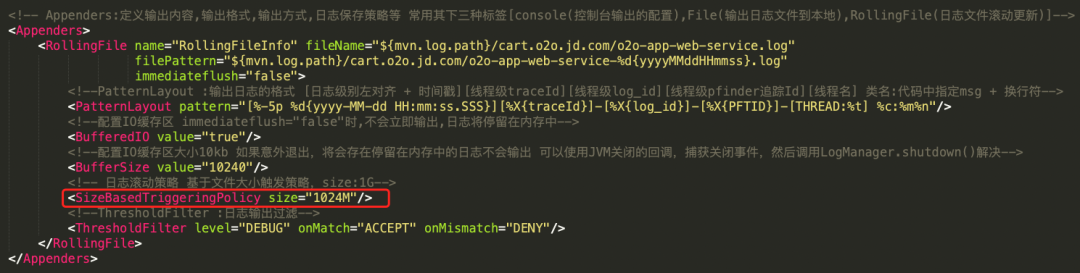
1、降低磁盘使用率
下图是购物车网关INFO级别的磁盘使用率(服务器配置4c8g磁盘50G), 以每小时20G的写入速度记录程序的运行过程。
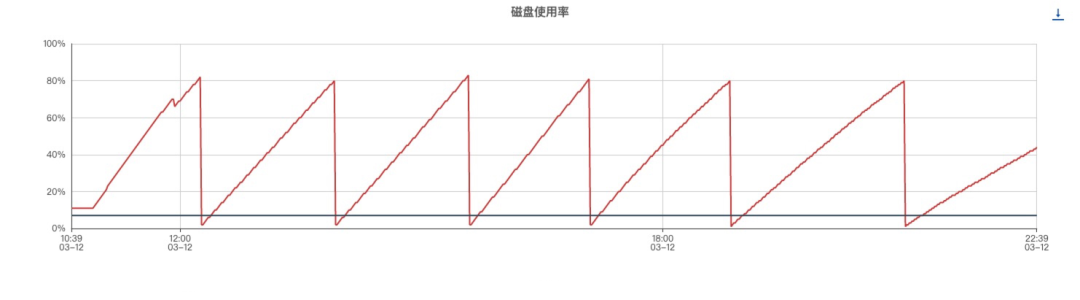
通过日志分级输出,控制日志打印级别,现在磁盘全天的使用率保持在10G左右。

1)Log4j2日志分级
日志打印需要可读性强且易于解析 ,写作的三要素是时间+地点+人物,打印日志的三要素则是时间+位置+事件。
时间:业务执行的时间;
位置:某个方法,某项业务;
事件:入参、出参、异常堆栈等;
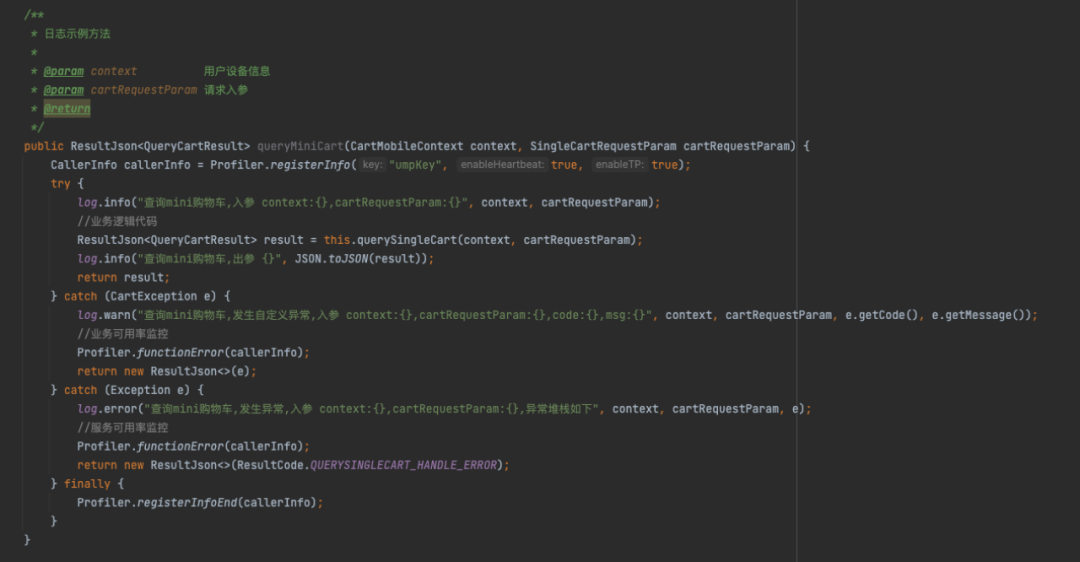
以下是购物车在不同场景使用的日志级别:
开发和联调阶段使用INFO级别,用来打印接口入参、出参、耗时和程序的运行过程,方便定位和排查问题。
线上使用WARN级别,用来感知服务降级、业务异常、参数异常、限流等场景。
在压测或大促期间我们会使用ERROR级别记录运行时异常情况。
日志分级的目的是尽量减少日志打印对服务性能和磁盘压力的影响。
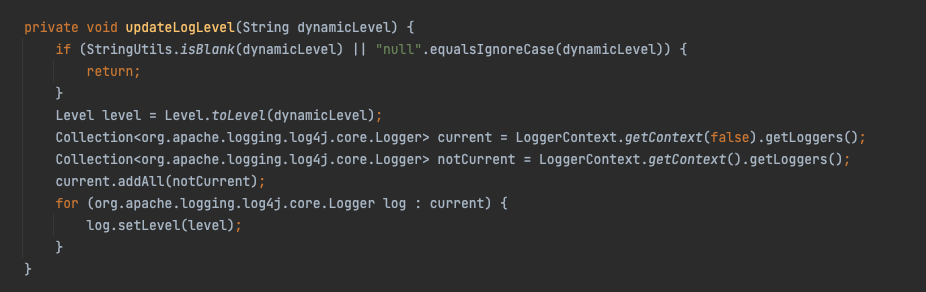
在一些极端场景下,线上需要详细日志的输出来定位问题,我们通过动态的调整日志级别来实现,调整日志级别代码如下:
2、异步日志
购物车网关通过改造日志配置,将同步输出日志,改成AsyncLogger异步输出,我们看一下同步日志和异步日志的性能对比。
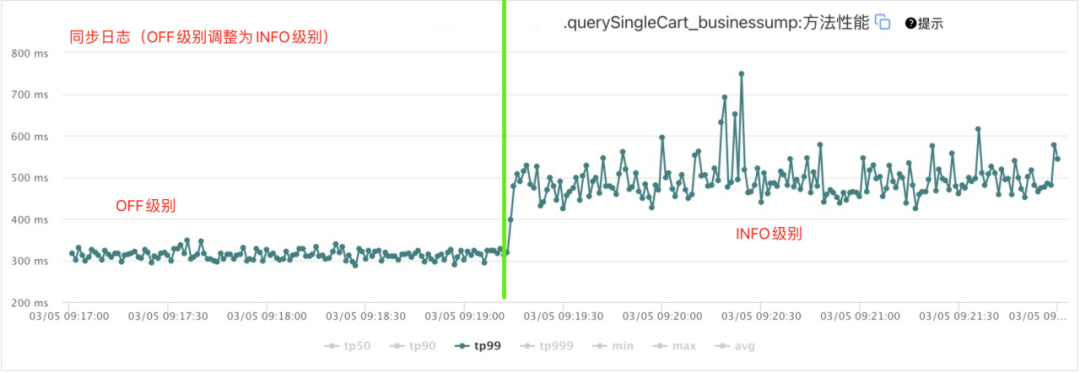
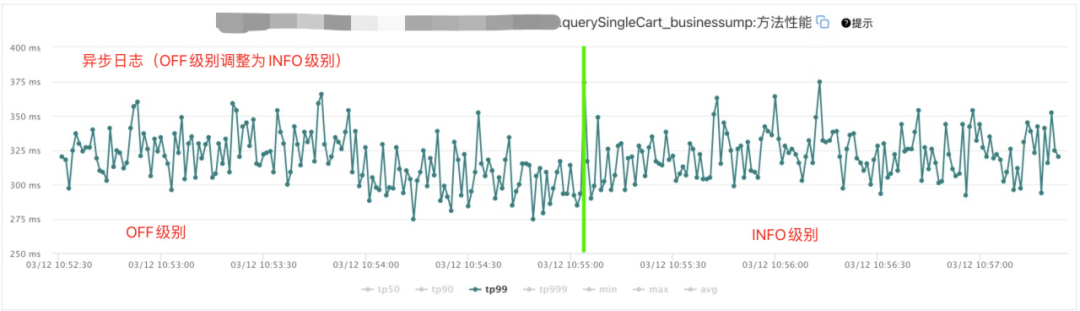
通过分析上面两张图,我们可以得出如下结论:
同步日志由OFF级别(不打印日志)调整为INFO级别(打印日志)后,接口耗时由320ms骤增至500ms,同步日志对于资源消耗是非常大的;
异步日志由OFF级别(不打印日志)调整为INFO级别(打印日志)后,对性能形象几乎可以忽略不计。
1)异步日志-AsyncLogger简介
AsyncLogger是Log4j2 官方推荐的异步方式。有全局异步和混合异步两种模式:
全局异步:所有的日志都异步的记录,在配置文件上不用做任何改动,只需要在jvm启动的时候增加一个参数;(设置log4j2.contextSelector参数为AsyncLoggerContextSelector)
混合异步:应用中可以同时使用同步日志和异步日志,这使得日志的配置方式更加灵活。同步日志适用于审计日志,异步日志会大幅度提升性能,使用时可按照具体场景选择日志输出模式。
AsyncLogger底层采用Disruptor,通过环形无阻塞队列作为缓冲,多生产者多线程的竞争是通过CAS(compare and swap)无锁化实现,可以极大的提高日志输出效率。
在加载log4j2.xml启动阶段,如果检测到配置了AsyncRoot或AsyncLogger,将启动一个disruptor实例。即使log4j2.xml中配置了多AsyncLogger,也仅有一个EventProcessor线程进行日志的异步处理。
Disruptor有一个基于数组的循环数据结构(环状缓冲区)。这种结构拥有多个可用元素引用的数组。预先分配了对象内存空间。生产者与消费者通过循环数据结构进行读写操作,不会有锁或资源竞争。
在Disruptor中,采用消费者-生产者模型进行读写的分离,所有事件(events)以组播的方式被发布给所有消费者,以便下游队列通过并行的方式进行消费。因为消费者是并行消费,所以需要协调消费者间的依赖关系。
生产者和消费者中有个序列计数器,指示缓冲区中当前正在被它所处理的元素。所有生产者或消费者只可以修改自己的序列计数器,但可以读取其他的序列计数器,通过内存屏障加序列号的方式实现了无锁的并发机制。

2)购物车AsyncLogger混合异步配置
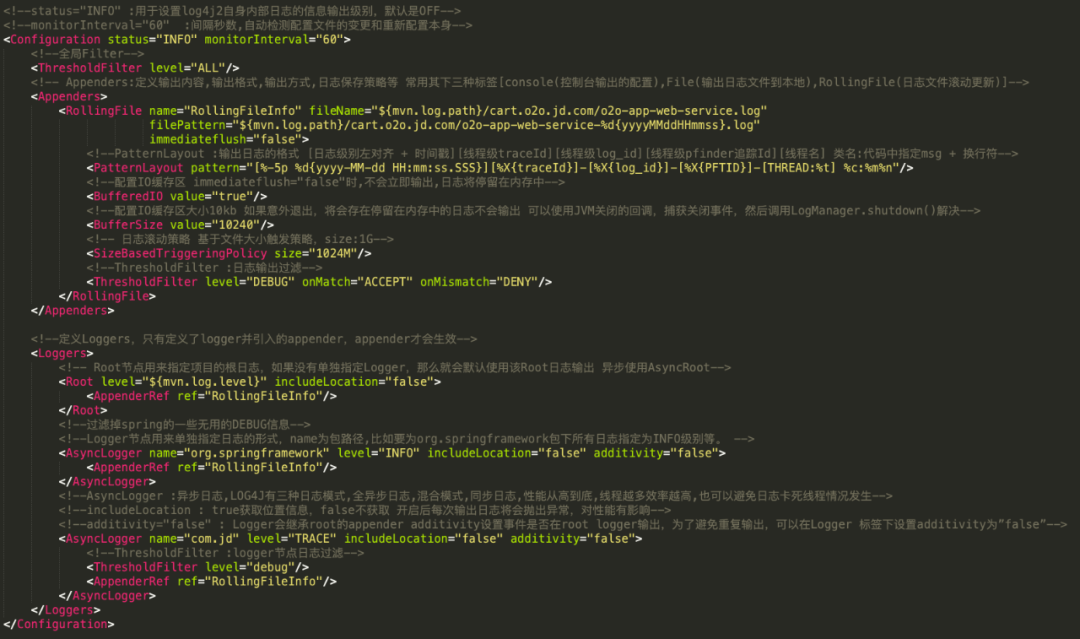
详细配置参考:https://blog.csdn.net/jek123456/article/details/100123570
3)异步日志注意事项
不要开启全局异步的情况下,使用AsyncAppender和AsyncLogger,虽然不会报错,但是对于性能提升没有任何好处。
不管是同步异步,都设置immediateFlush为false(为true时立即输出,不会缓冲),这会对性能提升有很大帮助,设置为false会提升5倍吞吐量左右,可以根据BufferSize值调整缓冲池大小,默认8Kb,如果程序意外退出,缓冲区内的日志不会输出 ,这种情况可以使用JVM关闭的回调功能,捕获关闭事件,然后调用LogManager.shutdown()输出缓冲区中的日志。
同步模式下不获取位置信息要比获取位置信息性能提升1-5倍,异步模式则会提升30-100倍。
4)日志的输出过程
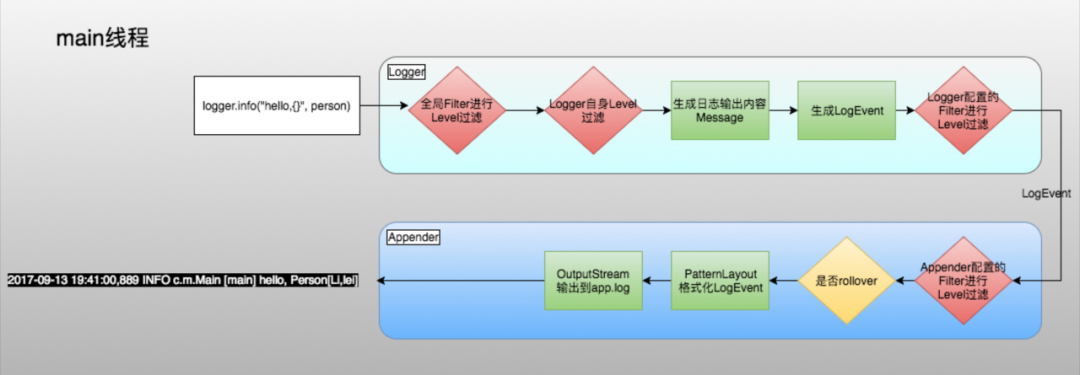
① 首先使用全局Filter对日志事件进行过滤
Log4j2中的日志Level分为8个级别,按照从低到高为:ALL < TRACE < DEBUG < INFO < WARN < ERROR < FATAL < OFF。
全局Filter的Level为ALL,表示允许输出所有级别的日志。logger.info()请求输出INFO级别的日志,通过。

② 使用Logger的Level对日志事件进行过滤
Logger的Level为TRACE,表示允许输出TRACE级别及以上级别的日志。logger.info()请求输出INFO级别的日志,通过。

③ 生成日志输出内容Message
使用占位符的方式输出日志,输出语句为logger.info()(“increase {} from {} to {}”, arg1, arg2,arg3)的形式,最终输出时{}占位符处的内容将用arg1,arg2,arg3的字符串填充。为后续日志格式化输出做准备。
④ 生成LogEvent
LogEvent中含有loggerName(日志的输出者),level(日志级别),timeMillis(日志输出时间),message(日志输出内容),threadName(线程名称)等信息。
在上述程序中,生成的LogEvent的属性值为loggerName=com.jddj.Main,Level=INFO,timeMillis=1505659461759,message为步骤3中创建的Message,threadNama=main。
⑤ 使用Logger配置的Filter对日志事件进行过滤
Logger配置的Filter的Level为DEBUG,表示允许输出DEBUG及以上级别的日志。logger.info()请求输出INFO级别的日志,通过。

⑥ 使用Logger对应的Appender配置的Filter对日志事件进行过滤
Appender的Filter配置的Level为INFO级别日志onMatch=ACCEPT,表示允许输出INFO级别的日志。logger.info()请求输出INFO级别的日志,通过。
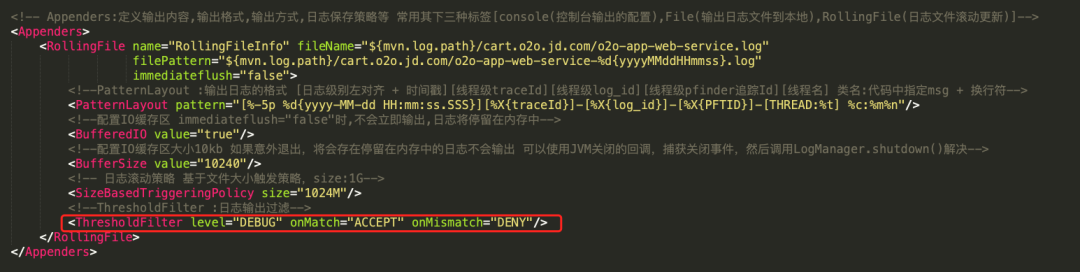
⑦ 判断是否需要触发rollover
此步骤不是日志输出的必须步骤,如配置的Appender无需进行rollover,则无此步骤。
因为使用RollingFileAppender,并且配置了基于文件大小的rollover触发策略,在此阶段会判断是否需要触发rollover。判断当前的文件大小是否达到了指定size,如果达到了,触发rollover操作(如果日志打印过多,则会频繁触发文件滚动机制,从而影响输出性能)。可参考Log4j2中RollingFile的文件滚动更新机制:https://www.cnblogs.com/yeyang/p/7944899.html
⑧ PatternLayout对LogEvent进行格式化,生成可输出的字符串
PatternLayout将根据Pattern的模式,利用各种Converter对LogEvent的相关信息进行转换,最终拼接成可输出的日志字符串。如:
DatePatternConverter对LogEvent的日志输出时间进行格式化转换;
LevelPatternConverter对LogEvent的日志级别信息进行格式化转换;
LoggerPatternConverter对LogEvent的Logger的名字进行格式化转换;
MessagePatternConverter对LogEvent的日志输出内容进行格式化转换等。
经各种Converter转换后,LogEvent的信息被格式化为指定格式的字符串。
⑨ 使用OutputStream,将日志输出到文件
将日志字符串序列化为字节数组,使用字节流OutoutStream将日志输出到文件中。如果配置了immediateFlush为true,打开app.log就可观察到输出的日志了。
3、降低CPU使用率
下图购物车网关单机3k/min的请求量下,打印行号和不打印行号cpu使用率对比。
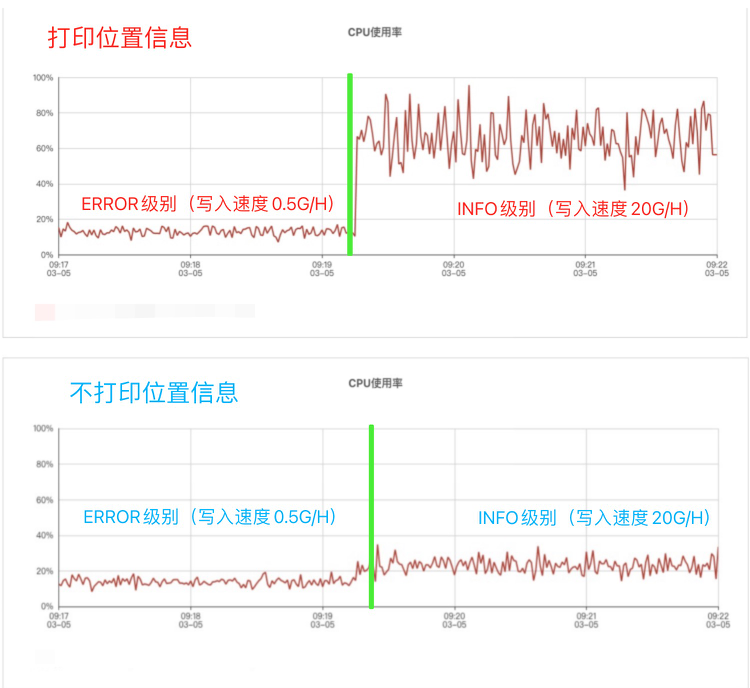
通过对比我们发现如果日志打印量少的情况下,cpu使用率差距不大,但是当达到每小时写入20G的时候,打印位置信息比不打印位置信息使用率差3倍左右,购物车系统通过以下两点解决cpu升高问题:
日志分级,降低日志的输出量
优化PatternLayout配置(不打印位置信息)

打印位置信息会导致的cpu使用率升高,下面是Log4j2官方针对打印位置信息性能的压测数据:
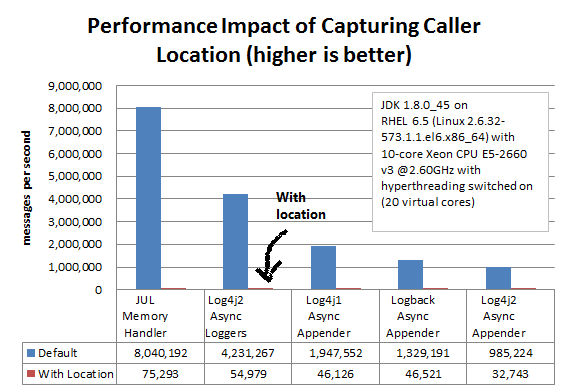
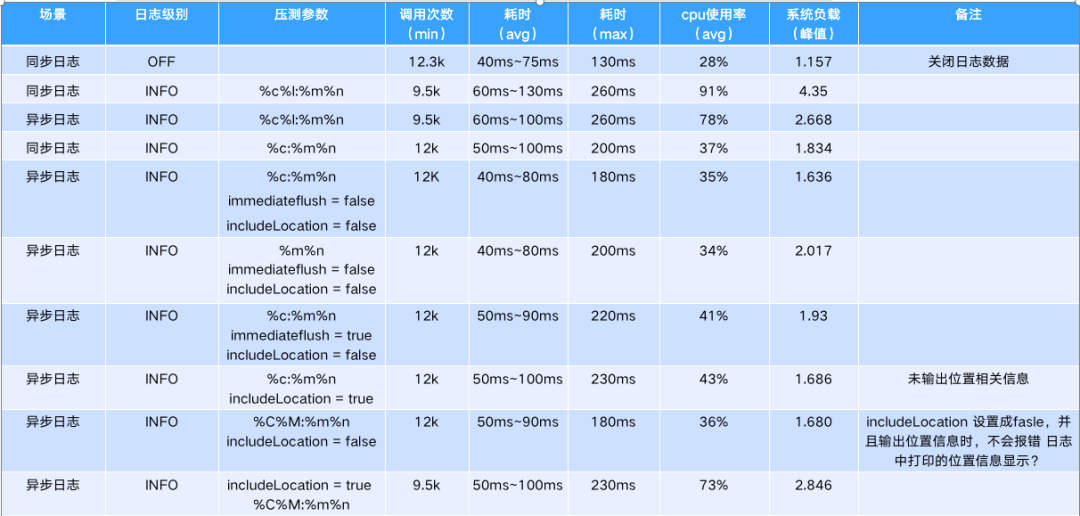
以下参数配置会使性能急剧下降 : %C or $class, %F or %file, %l or %location, %L or %line, %M or %method, 大概下降30-100倍左右(includeLocation 参数配置决定了是否抛出异常,以上参数配置决定了是否遍历堆栈)。
这是因为Log4j需要在运行时获取堆栈的快照(snapshot),并遍历堆栈跟踪以查找位置信息,无论是在Java 9之前通过Thorwable.getStackTrace(),还是通过 Java 9 之后的 StackWalker,获取当前代码堆栈,都是一个非常消耗 CPU 性能的操作。在大量输出日志的时候,会成为严重的性能瓶颈,其原因是:
获取堆栈属于从 Java 代码运行,切换到 JVM 代码运行,是 JNI (Java Native Interface)调用。这个切换是有性能损耗的。
Java 9 之前通过新建异常获取堆栈,Java 9 之后通过 Stackwalker 获取。这两种方式,截止目前 Java 17 版本,都在高并发情况下,有严重的性能问题,会吃掉大量 CPU。(底层 JVM 符号与常量池优化的问题)
从源码看,获取位置信息需要遍历异常+反射+字符串截取+悲观锁,这些都是非常消耗性能的。
Log4j PatternLayout 符号定义
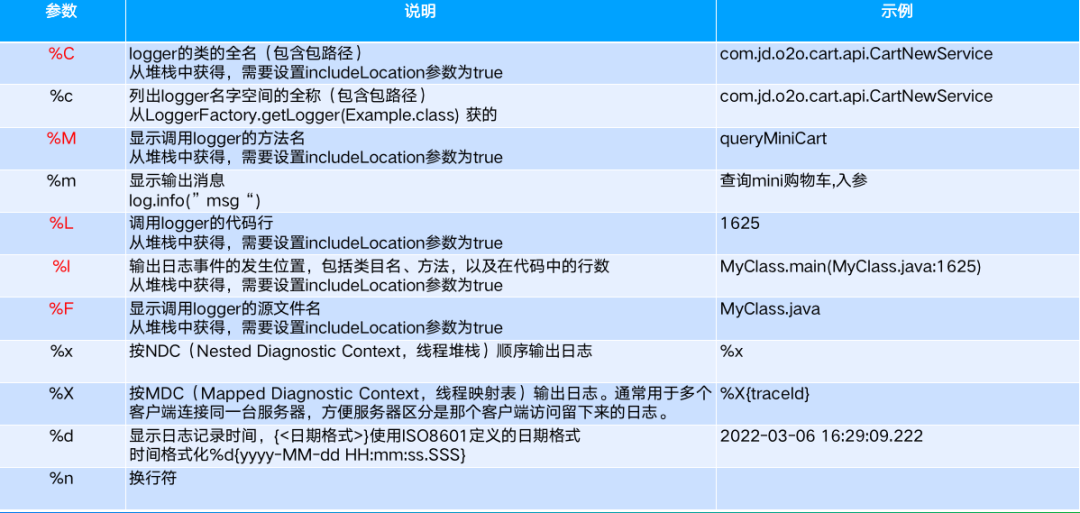
红色标注的参数不建议配置,这些参数配置后非常影响性能。
二、日志链路追踪
生产环境排查问题往往都是通过日志,但对于巨大的日志量,如何实现针对某一个操作进行整个日志链路的追踪就显得尤为重要。
Log4j2提供的日志追踪方案是NDC和MDC,但仅限于当前线程内的数据传递(其底层原理是维护一个ThreadLocalMap),如果是父子线程之间的调用,就无法完成完整的链路追踪工作。
购物车使用 TTL(TransmittableThreadLocal) + 线程池 + Log4j2 来解决这个问题。
1、ThreadLocal技术选型
1)ThreadLocal:解决的是每个线程可以拥有自己线程的变量实例。可以从隔离的角度解决变量线程安全的问题。
优点:解决了当前线程的值传递。
缺点:不支持子线程。
2)InheritableThreadLocals:其设计的初衷是为了增强ThreadLocal类型,使其具备变量可以被子线程继承的特性,具体表现为当前线程创建子线程的时候,会把ThreadLocal快照拷贝一份到子线程的ThreadLocal中,但是对于使用复用线程的执行组件时,ITL的值传递已经不起作用。
优点:支持新建子线程的值传递。
缺点:不支持线程池。
3)TransmittableThreadLocal:为了进一步增强InheritableThreadLocals,使其能够在提交任务到线程池的时候拷贝“任务提交者(通常为主线程)”的线程变量,因此会在当前线程创建任务的时候初始化,即构造Runnable接口的对象时初始化。(因继承ITL,会有ITL特性,当线程池新建线程执行任务时,即使不改造线程池仍然会有主线程快照,但是会存在脏数据)
优点:支持子线程、线程池的值传递。
缺点:需要改造线程池代码。
2、TTL线程池改造
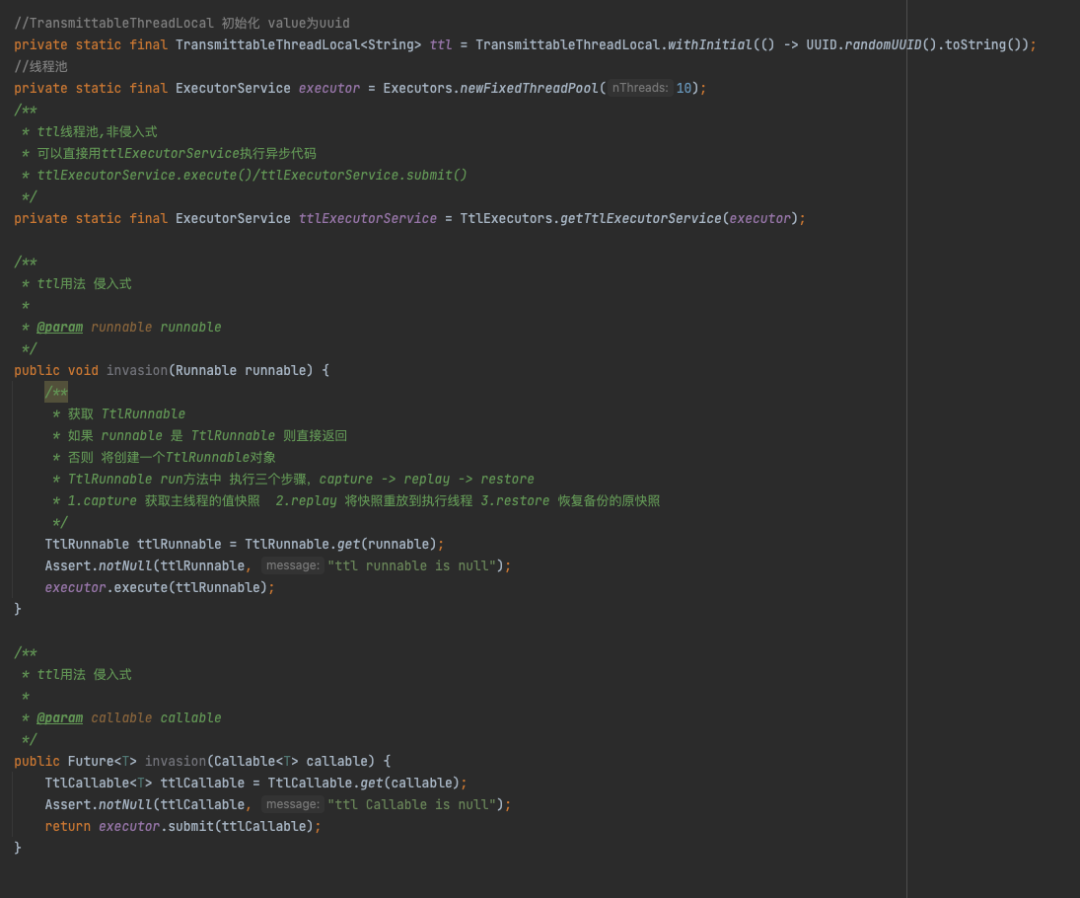
3、Log4j2 MDC + TTL线程池实现
MDC和NDC是Log4j用于存储应用程序的上下文信息,其底层原理是维护一个ThreadLocalMap (ThreadLocal),当使用线程池时,无法获取主线程的值,所以我们利用TTL思想在线程池执行任务之前,copy一份主线程上下文信息快照,并且在执行完线程之后,恢复执行线程备份的变量,解决Log4j2在线程池值传递的问题。
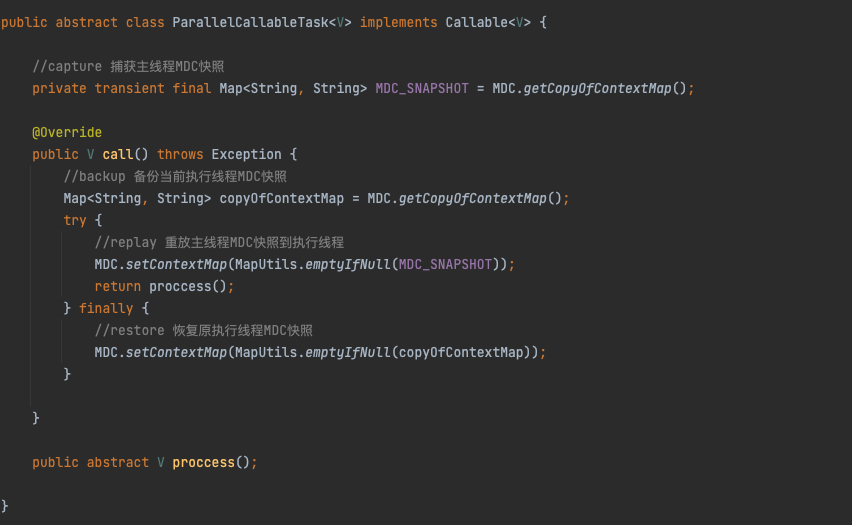
ParallelCallableTask重写Callable任务,所以需要线程池执行Callable任务,改为执行ParallelCallableTask任务。

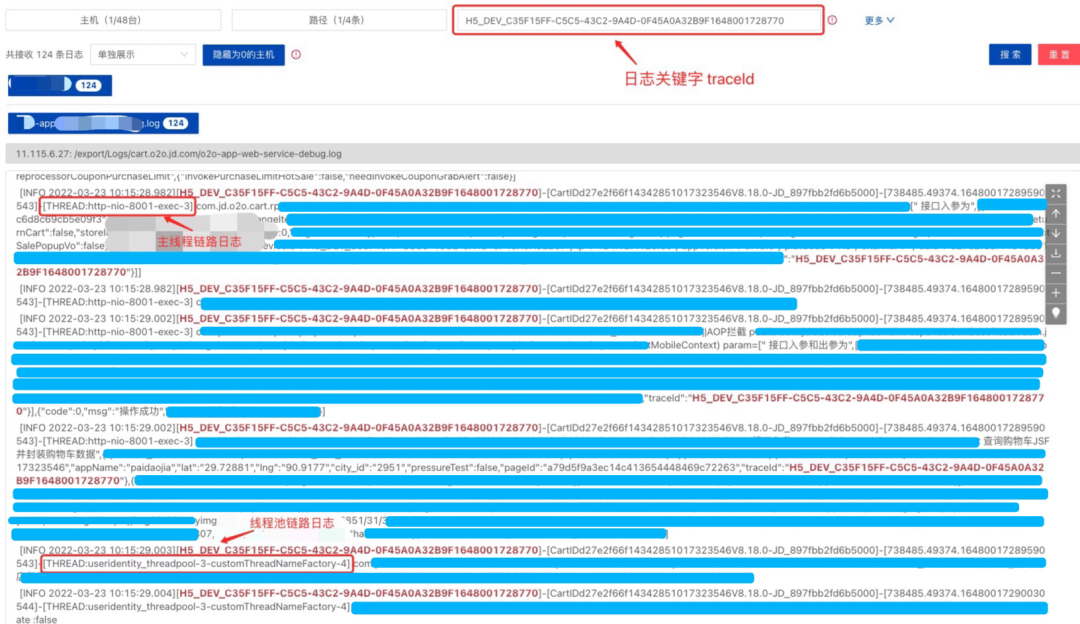
4、链路日志使用
针对用户每次请求的traceId分析产生问题的具体原因,通过链路日志的改造,traceId贯穿整个业务流程。
三、测试指标及建议
1、建议
合理的记录程序运行时的各项参数,可以快速帮我们定位问题原因。
日志分级输出,合理调整日志的输出级别,可以减少cpu和磁盘压力。
调整日志格式,正确清晰的输出日志,可以减少线上风险,规避性能隐患。
Log4j+监控组合使用可以让开发更容易发现问题,解决问题。
如果对日志性能要求高,可以使用异步日志,如果打印过多,要考虑日志分级。
改造线程池可以减少系统链路关键字的维护,不需要无限制的透传下去。
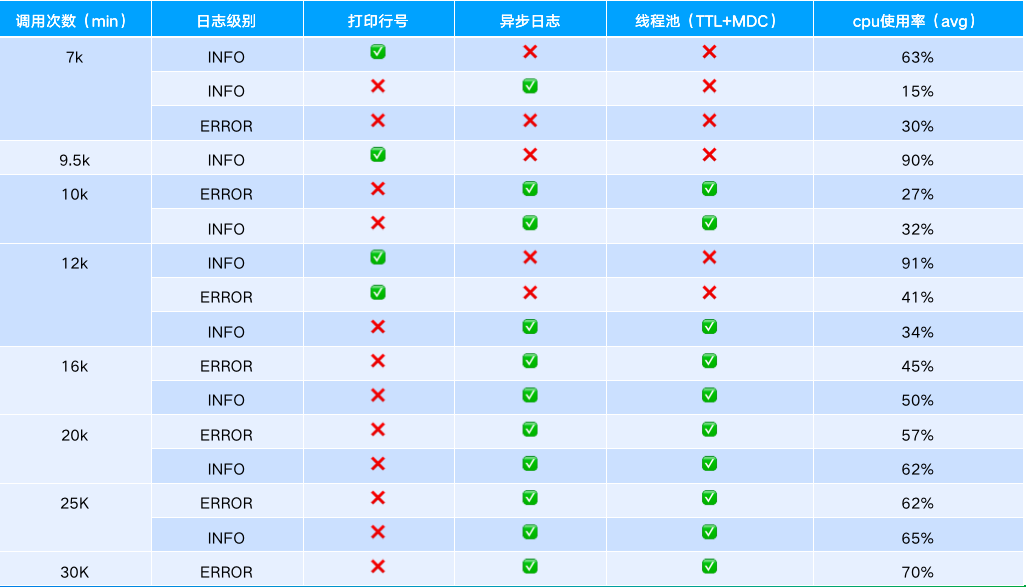
2、测试指标
购物车网关cpu使用率压测结果(服务器配置cpu:4c 内存8g 磁盘50G)
3、Log4j2各项参数测试结果
(服务器配置 4c8g磁盘50G 12并发tp99)
本文来自博客园,作者:古道轻风,转载请注明原文链接:https://www.cnblogs.com/88223100/p/2-major-optimizations-of-log-system-performance5-major-criteria.html