首先,大家对Python语法的了解已经基本完成,现在我们需要开始进行各种练习。我为大家准备了一些练习题目,比如之前的向量数据库等,这些题目可以参考第三方的SDK来进行操作,文档也是比较完善的。这个过程有点像我们之前使用Java对接第三方接口的方式,所以今天我想开发一个很实用的工具类,用于将PDF转换为DOCX文档。我觉得这个工具非常实用,所以通过这个项目,我想带领那些在Python基础上还比较薄弱的同学们从零开始,一起完成这个项目。
首先,我也刚开始接触这个项目,所以我并不知道如何实现。我的第一反应是去搜索引擎上查找是否有其他人已经实现了类似的功能,因为现在有很多优秀的开源项目可供参考。毕竟,站在巨人的肩膀上进行开发并不可耻,而是一种聪明的做法。
幸运的是,我找到了一个名为”pdf2docx”的第三方包,它提供了非常优秀的功能。令人惊讶的是,仅仅几行代码就可以完成PDF转换为DOCX的工作。而且,转换结果也非常出色。让我们来看一下具体的实现过程。
希望大家可以去仓库中查看源码,学习如何使用这个工具包,也欢迎大家在仓库中留言,提出任何问题或建议。一起进步,共同学习!仓库地址为:https://github.com/StudiousXiaoYu/pdf2docx_with_ui
PDF转DOCX文档第三方包:pdf2docx
from pdf2docx import Converterdef convert_pdf_to_docx(pdf_path, docx_path): # 创建一个转换器对象 converter = Converter(pdf_path) # 将PDF转换为DOCX converter.convert(docx_path, start=0, end=None) # 关闭转换器 converter.close()# 调用函数进行转换pdf_path = "input.pdf"docx_path = "output.docx"convert_pdf_to_docx(pdf_path, docx_path)他很容易理解,只需要你定义好文件路径即可完成转换操作。此外,我也不多解释了,因为start参数用于指定转换的起始页码,而end参数用于指定转换的结束页码。你可以根据需要设置这两个参数的值,如果不需要指定起始页码,可以将start参数设置为0;如果不需要指定结束页码,则可以将end参数设置为None。
官方可视化界面
代码很简单,但是如果是自己使用的话,每次都要写一次路径可能会很麻烦。不过你可以使用一个可视化交互界面来简化这个过程,这样会更方便一些。幸运的是,pdf2docx提供了一个简易版的界面,你可以在控制台中直接输入”pdf2docx gui”来启动。在界面中,你只需要选择要转换的PDF文件和一个文件夹作为保存路径,就可以完成转换操作了。这样的话,你就不需要每次都手动输入路径了。非常方便。

简易版可交互界面
但是,如果你对pdf2docx提供的界面不满意,并且觉得界面不够好看,那么可以考虑使用另一个第三方界面库,叫做gradio。我记得你之前在向量数据库中使用过这个库,对后端非常友好。你可以先写一个简单的界面,然后逐步优化它,以满足你的需求。gradio提供了很多功能和自定义选项,你可以根据自己的喜好来设计界面的外观和交互方式。然后慢慢优化吧。
import gradio as grfrom pdf2docx import Converterdef convert_pdf_to_docx_with_display(pdf_file): tmp_file = "./output.docx" # Convert PDF to DOCX cv = Converter(pdf_file) cv.convert(tmp_file) cv.close() return tmp_filedef convert_and_display_pdf_to_docx(pdf_file): docx_file = convert_pdf_to_docx_with_display(pdf_file) return docx_fileiface = gr.Interface( fn=convert_and_display_pdf_to_docx, inputs=["file"], outputs=["file"], title="[努力的小雨] PDF to DOCX Converter", description="上传pdf文件,并将其转化为docx文件",)iface.launch()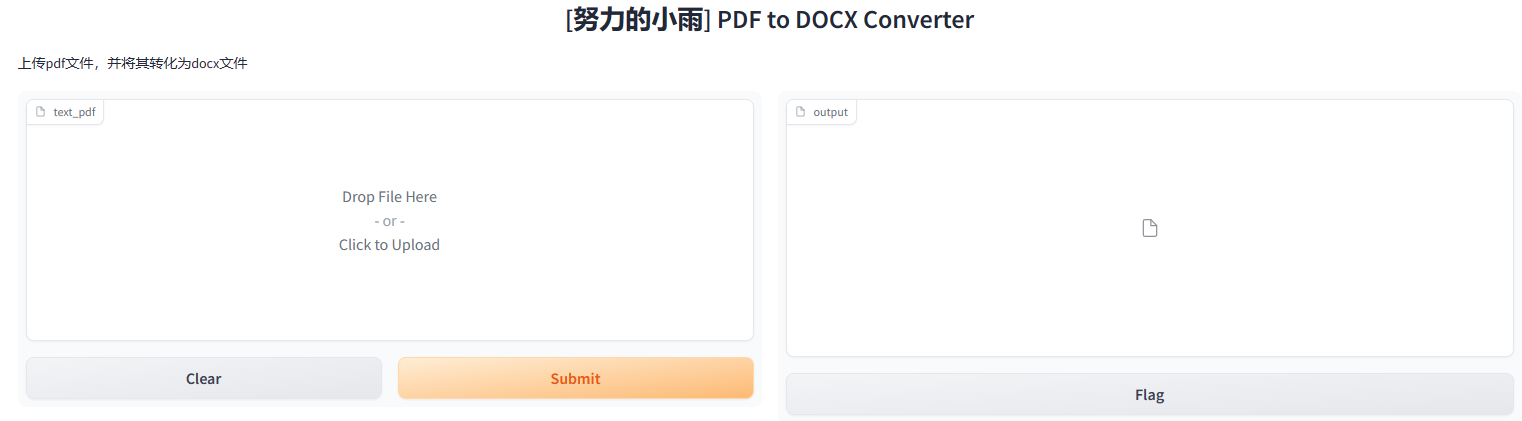
恩恩,我看着是相当不错的,这个小工具已经可以满足用户的需求了。效果图,你可以看看:

优化版界面
好的,目前可交互的资源还相对较少。然而,如果我们能够提前预览解析后的文字内容,有时就能避免不必要的下载。比如,在查看PDF文件时,我们只需要复制粘贴其中的文字,而无需下载整个文件。为了实现这一功能,我们可以考虑在文件底部添加一个额外的窗口,用于显示解析后的文字内容。通过提供复制粘贴功能,用户可以轻松地获取所需的文字信息。
import gradio as grfrom pdf2docx import Converterimport docx2txtdef convert_pdf_to_docx_with_display(pdf_file): tmp_file = "./output.docx" # Convert PDF to DOCX cv = Converter(pdf_file) cv.convert(tmp_file) cv.close() # Extract text from DOCX docx_text = docx2txt.process(tmp_file) return tmp_file, docx_textdef convert_and_display_pdf_to_docx(pdf_file): docx_file, docx_text = convert_pdf_to_docx_with_display(pdf_file) return docx_file, docx_textiface = gr.Interface( fn=convert_and_display_pdf_to_docx, inputs=["file"], outputs=["file", "text"], title="[努力的小雨] PDF to DOCX Converter", description="上传pdf文件,并将其转化为docx文件且在界面单独显示文件的文字",)iface.launch()当我们完成代码的修改后,运行一下,我发现效果与我预期的是一致的。

至强版界面
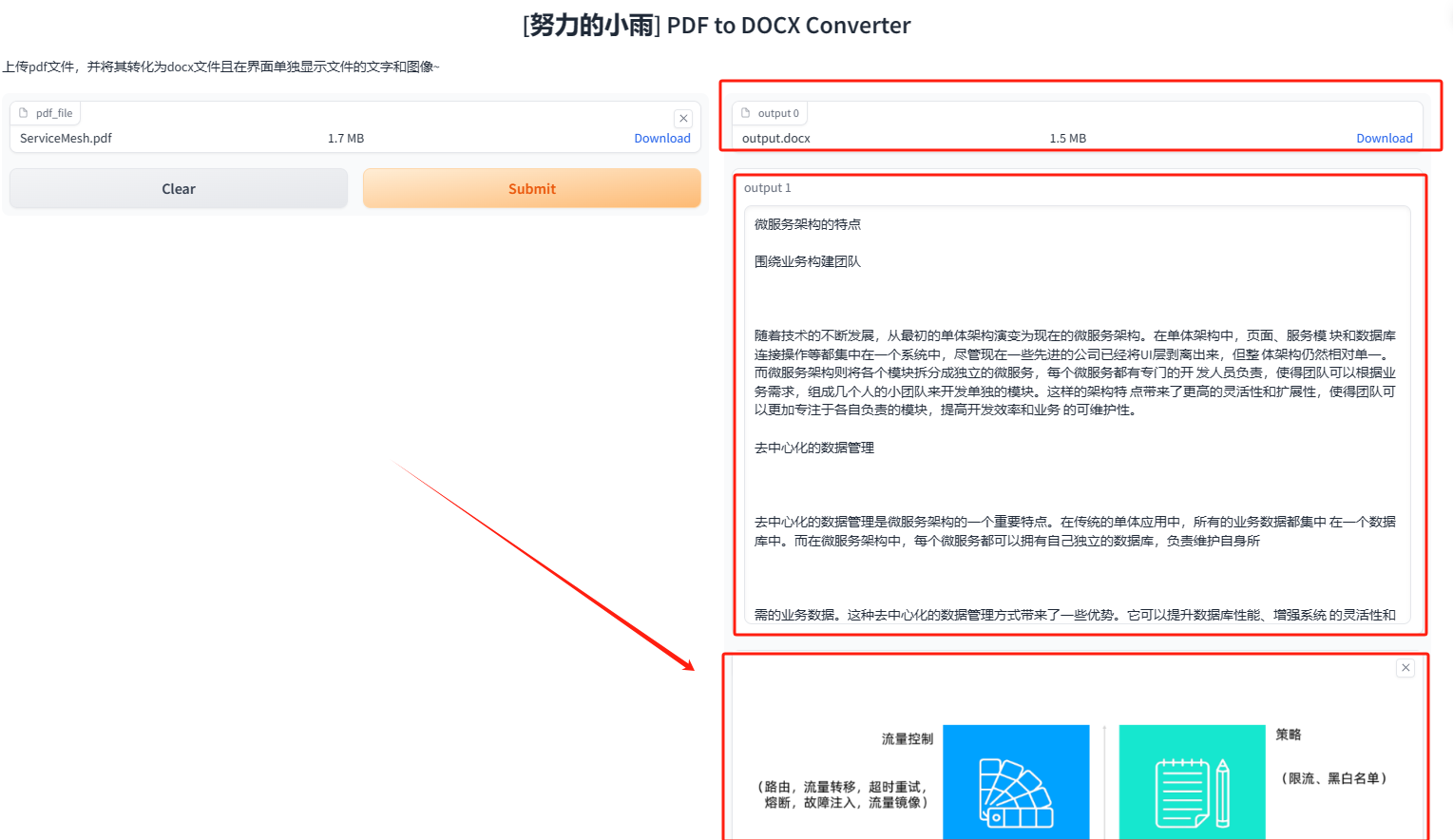
如果我们已经能够显示文字,那么是否还需要显示图片呢?考虑到PDF中常常包含图片,为了满足用户复制粘贴图片的需求,我认为单独开发一个窗口来保存图片是合理的。然而,在这个过程中,我遇到了一些困难,几乎是我的噩梦。我一直遇到报错,而且这些错误几乎是我之前从未遇到过的。就像当初学习Java的时候,总是需要上网搜索解决方法一样。在使用gradio时,我创建了一个画廊窗口,但是错误地以为它可以直接返回图像的二进制内容,所以没有进行保存,结果一直报错。后来,我保存了图像,问题得以解决。现在我们来修改代码,因为有很多重复的代码,我就不再一直复制粘贴了。
# 此处省略部分代码# Extract images from DOCX images = [] image_dir = os.path.join(tmp_dir, "images") os.makedirs(image_dir, exist_ok=True) for embed, related_part in document.part.related_parts.items(): if isinstance(related_part, ImagePart): image_path = os.path.join(image_dir, f'image_{embed}.png') with open(image_path, 'wb') as f: f.write(related_part.image.blob) images.append(image_path) return tmp_file, docx_text, images# 此处省略部分代码 我将图片保存到一个文件夹中,并返回一个包含图片实体的列表。现在让我们来看一下效果:可以看到图片已经显示出来了,但我觉得交互性还不够,如果用户不想要前几页的PDF怎么办呢?为了解决这个问题,我将再添加一个输入框,让用户可以输入相关信息。让我们继续优化一下。
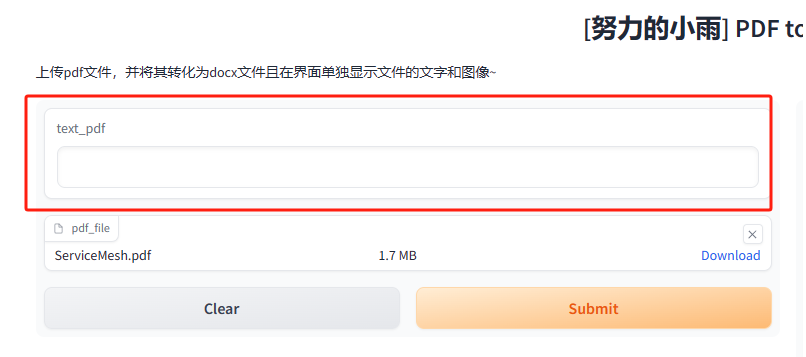
inputs=["text","file"],为了实现传参,我们可以修改输入参数的类型。这个过程非常简单。除了我之前演示的简单样式外,Gradio还有很多其他样式可供选择。我只是提供了一个最简单的示例,剩下的优化工作就交给你了。你可以根据需要选择适合的样式进行优化。
这里我就不演示了,因为只要我们能够获取参数,我们就可以实现各种功能。就pdf转docx的可视化界面而言,我已经基本完成了它,它符合我的要求并且基本上令我满意。毕竟,我不需要去优化界面。
总结
pdf转docx文档是一个非常实用的功能,我只是简单地实现了一个可视化界面供用户操作。我这么做的目的之一是想更多地掌握gradio的使用方法,同时也加强对Python流行第三方包的熟悉程度,因为这些第三方包是快速开发的关键。我也希望你能从中有所收获,我已经公布了本期的源码地址,如果你觉得还不错,或者在自己编写的过程中遇到问题,可以简单地参考一下。不过,我仍然希望你能自己解决bug问题,这样一旦熟悉了,就知道如何处理,不用总是上网寻找解决方案。